Background Features in Google Meet, Powered by Web ML
October 30, 2020
Posted by Tingbo Hou and Tyler Mullen, Software Engineers, Google Research
Quick links
Video conferencing is becoming ever more critical in people's work and personal lives. Improving that experience with privacy enhancements or fun visual touches can help center our focus on the meeting itself. As part of this goal, we recently announced ways to blur and replace your background in Google Meet, which use machine learning (ML) to better highlight participants regardless of their surroundings. Whereas other solutions require installing additional software, Meet’s features are powered by cutting-edge web ML technologies built with MediaPipe that work directly in your browser — no extra steps necessary. One key goal in developing these features was to provide real-time, in-browser performance on almost all modern devices, which we accomplished by combining efficient on-device ML models, WebGL-based rendering, and web-based ML inference via XNNPACK and TFLite.
 |
| Background blur and background replacement, powered by MediaPipe on the web. |
Overview of Our Web ML Solution
The new features in Meet are developed with MediaPipe, Google's open source framework for cross-platform customizable ML solutions for live and streaming media, which also powers ML solutions like on-device real-time hand, iris and body pose tracking.
A core need for any on-device solution is to achieve high performance. To accomplish this, MediaPipe’s web pipeline leverages WebAssembly, a low-level binary code format designed specifically for web browsers that improves speed for compute-heavy tasks. At runtime, the browser converts WebAssembly instructions into native machine code that executes much faster than traditional JavaScript code. In addition, Chrome 84 recently introduced support for WebAssembly SIMD, which processes multiple data points with each instruction, resulting in a performance boost of more than 2x.
Our solution first processes each video frame by segmenting a user from their background (more about our segmentation model later in the post) utilizing ML inference to compute a low resolution mask. Optionally, we further refine the mask to align it with the image boundaries. The mask is then used to render the video output via WebGL2, with the background blurred or replaced.
 |
| WebML Pipeline: All compute-heavy operations are implemented in C++/OpenGL and run within the browser via WebAssembly. |
In the current version, model inference is executed on the client’s CPU for low power consumption and widest device coverage. To achieve real-time performance, we designed efficient ML models with inference accelerated by the XNNPACK library, the first inference engine specifically designed for the novel WebAssembly SIMD specification. Accelerated by XNNPACK and SIMD, the segmentation model can run in real-time on the web.
Enabled by MediaPipe's flexible configuration, the background blur/replace solution adapts its processing based on device capability. On high-end devices it runs the full pipeline to deliver the highest visual quality, whereas on low-end devices it continues to perform at speed by switching to compute-light ML models and bypassing the mask refinement.
Segmentation Model
On-device ML models need to be ultra lightweight for fast inference, low power consumption, and small download size. For models running in the browser, the input resolution greatly affects the number of floating-point operations (FLOPs) necessary to process each frame, and therefore needs to be small as well. We downsample the image to a smaller size before feeding it to the model. Recovering a segmentation mask as fine as possible from a low-resolution image adds to the challenges of model design.
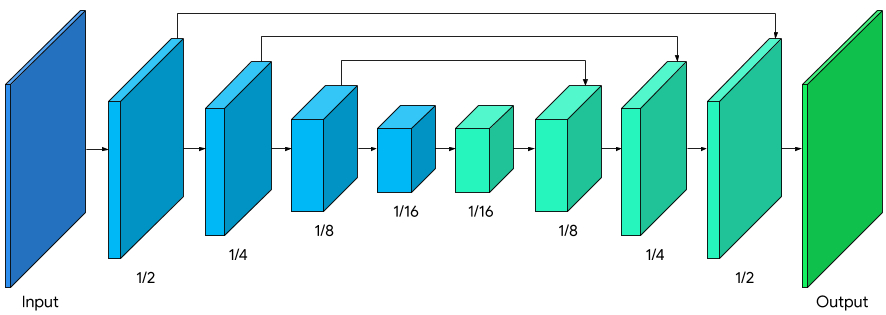
The overall segmentation network has a symmetric structure with respect to encoding and decoding, while the decoder blocks (light green) also share a symmetric layer structure with the encoder blocks (light blue). Specifically, channel-wise attention with global average pooling is applied in both encoder and decoder blocks, which is friendly to efficient CPU inference.
 |
| Model architecture with MobileNetV3 encoder (light blue), and a symmetric decoder (light green). |
We modified MobileNetV3-small as the encoder, which has been tuned by network architecture search for the best performance with low resource requirements. To reduce the model size by 50%, we exported our model to TFLite using float16 quantization, resulting in a slight loss in weight precision but with no noticeable effect on quality. The resulting model has 193K parameters and is only 400KB in size.
Rendering Effects
Once segmentation is complete, we use OpenGL shaders for video processing and effect rendering, where the challenge is to render efficiently without introducing artifacts. In the refinement stage, we apply a joint bilateral filter to smooth the low resolution mask.
 |
| Rendering effects with artifacts reduced. Left: Joint bilateral filter smooths the segmentation mask. Middle: Separable filters remove halo artifacts in background blur. Right: Light wrapping in background replace. |
The blur shader simulates a bokeh effect by adjusting the blur strength at each pixel proportionally to the segmentation mask values, similar to the circle-of-confusion (CoC) in optics. Pixels are weighted by their CoC radii, so that foreground pixels will not bleed into the background. We implemented separable filters for the weighted blur, instead of the popular Gaussian pyramid, as it removes halo artifacts surrounding the person. The blur is performed at a low resolution for efficiency, and blended with the input frame at the original resolution.
 |
| Background blur examples. |
For background replacement, we adopt a compositing technique, known as light wrapping, for blending segmented persons and customized background images. Light wrapping helps soften segmentation edges by allowing background light to spill over onto foreground elements, making the compositing more immersive. It also helps minimize halo artifacts when there is a large contrast between the foreground and the replaced background.
 |
| Background replacement examples. |
Performance
To optimize the experience for different devices, we provide model variants at multiple input sizes (i.e., 256x144 and 160x96 in the current release), automatically selecting the best according to available hardware resources.
We evaluated the speed of model inference and the end-to-end pipeline on two common devices: MacBook Pro 2018 with 2.2 GHz 6-Core Intel Core i7, and Acer Chromebook 11 with Intel Celeron N3060. For 720p input, the MacBook Pro can run the higher-quality model at 120 FPS and the end-to-end pipeline at 70 FPS, while the Chromebook runs inference at 62 FPS with the lower-quality model and 33 FPS end-to-end.
| Model | FLOPs | Device | Model Inference | Pipeline |
| 256x144 | 64M | MacBook Pro 18 | 8.3ms (120 FPS) | 14.3ms (70 FPS) |
| 160x96 | 27M | Acer Chromebook 11 | 16.1ms (62 FPS) | 30ms (33 FPS) |
| Model inference speed and end-to-end pipeline on high-end (MacBook Pro) and low-end (Chromebook) laptops. |
For quantitative evaluation of model accuracy, we adopt the popular metrics of intersection-over-union (IOU) and boundary F-measure. Both models achieve high quality, especially for having such a lightweight network:
| Model | IOU | Boundary F-measure |
| 256x144 | 93.58% | 0.9024 |
| 160x96 | 90.79% | 0.8542 |
| Evaluation of model accuracy, measured by IOU and boundary F-score. |
We also release the accompanying Model Card for our segmentation models, which details our fairness evaluations. Our evaluation data contains images from 17 geographical subregions of the globe, with annotations for skin tone and gender. Our analysis shows that the model is consistent in its performance across the various regions, skin-tones, and genders, with only small deviations in IOU metrics.
Conclusion
We introduced a new in-browser ML solution for blurring and replacing your background in Google Meet. With this, ML models and OpenGL shaders can run efficiently on the web. The developed features achieve real-time performance with low power consumption, even on low-power devices.
Acknowledgments
Special thanks to those on the Meet team and others who worked on this project, in particular Sebastian Jansson, Rikard Lundmark, Stephan Reiter, Fabian Bergmark, Ben Wagner, Stefan Holmer, Dan Gunnarson, Stéphane Hulaud and to all our team members who worked on the technology with us: Siargey Pisarchyk, Karthik Raveendran, Chris McClanahan, Marat Dukhan, Frank Barchard, Ming Guang Yong, Chuo-Ling Chang, Michael Hays, Camillo Lugaresi, Gregory Karpiak, Siarhei Kazakou, Matsvei Zhdanovich, and Matthias Grundmann.
Quick links
Other posts of interest
-

June 30, 2026
Introducing TabFM: A zero-shot foundation model for tabular data- Data Management ·
- Machine Intelligence ·
- Product
-

June 26, 2026
Accelerating Gemini Nano models on Pixel with frozen Multi-Token Prediction- Machine Intelligence ·
- Mobile Systems ·
- Natural Language Processing
-

June 24, 2026
Thinking to recall: How reasoning unlocks parametric knowledge in LLMs- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing