Restoring speaker voices with zero-shot cross-lingual voice transfer for TTS
August 21, 2024
Fadi Biadsy, Senior Staff Research Scientist, and Youzheng (Joseph) Chen, Senior Software Engineer, Google Assistant
Quick links
Vocal characteristics contribute significantly to the construction and perception of individual identity. The loss of one's voice, caused by physical or neurological conditions, can result in a profound sense of loss, striking at the very heart of one's identity. Speakers with degenerative neural diseases, such as amyotrophic lateral sclerosis (ALS), Parkinson's, and multiple sclerosis, may experience a degradation of some of the unique characteristics of their voice over time. Some individuals are born with conditions, like muscular dystrophy, that affect the articulatory system and limit their ability to produce certain sounds. Profound deafness also impacts vocal and articulatory patterns due to the absence of auditory input and feedback. These conditions present lifelong challenges in matching the typical speech heard widely.
In recent years, there have been new advances in voice transfer (VT) technology, integrated in text-to-speech (TTS), voice conversion (VC), and speech-to-speech translation models. For example, in our previous work, we built a VC model that converts atypical speech directly to a synthesized predetermined typical voice that can be more easily understood by others. Yet for many individuals with dysarthria, VT extends speech technologies to help them regain their original voice and potentially predict speech patterns they have lost.
A VT module can be designed for a given speaker using either few- or zero-shot training. In few-shot training for VT, a sample of speech from a given speaker is used to adapt a pre-trained model to transfer or clone their voice. This approach typically produces high quality speech with high speaker-voice fidelity, depending on the amount and quality of the training samples. A more challenging approach is zero-shot, which does not require training, but rather feeds audio reference samples (e.g., 10 seconds) from a given speaker to the system during generation, to transfer their voice into the output synthesized speech. These systems vary significantly in their quality and do not guarantee to produce high fidelity voices to the reference voice. Few-shot approaches can be effective for those speakers who once had typical speech and have banked a set of high quality samples of their voice before an etiology has progressed (or a physical injury has occurred). On the other hand, zero-shot is more appropriate for those dysarthric speakers who have not banked sufficient samples of their voice or have never had a typical voice. Moreover, a zero-shot system can be easily scaled and deployed.
In this blogpost, we describe a zero-shot VT module that can be easily plugged into a state-of-the-art TTS system to restore the voices of input speakers. It can be used both when speakers have banked a small set of their voice or when atypical speech is the only data available. We add this module to our TTS system and use it to restore the voices of speakers who banked their typical speech. We also show that the same model produces high quality speech with high fidelity voice preservation even when the input reference is atypical, useful for those who have not banked their voice or never had typical speech. Finally, we demonstrate that such a module is capable of transferring voice across languages, even though the language of the input reference speech is different from the intended target language.
The text-to-speech model with voice transfer module
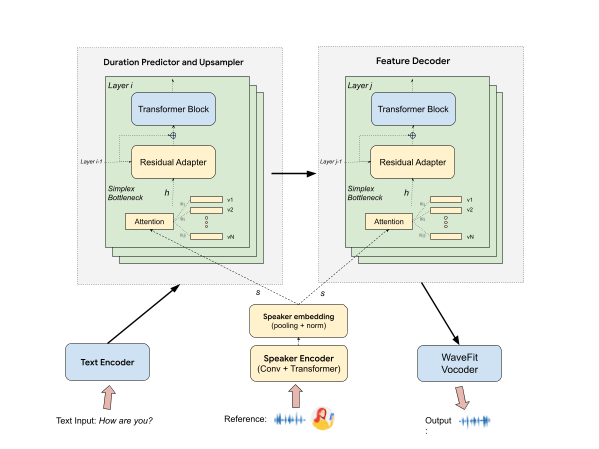
The TTS inference system consists of a text encoder that transforms the linguistic information into a sequence of hidden representations. These representations are then fed into a token duration predictor and upsampler, which generate a longer sequence proportional to the predicted output duration. This expanded sequence is passed to a feature decoder to generate hidden features corresponding to the synthesized acoustic features. Finally, a WaveFit vocoder converts these features into an output time-domain waveform.
Our new VT module is an extension to this TTS system that takes an input reference speech example. This extension enables the TTS model to transfer the voice in the reference speech to generate synthesized speech in this voice. This extension is shown in the yellow components in the figure below. The VT module is composed of a speaker encoder, bottleneck modules, and residual adapters.
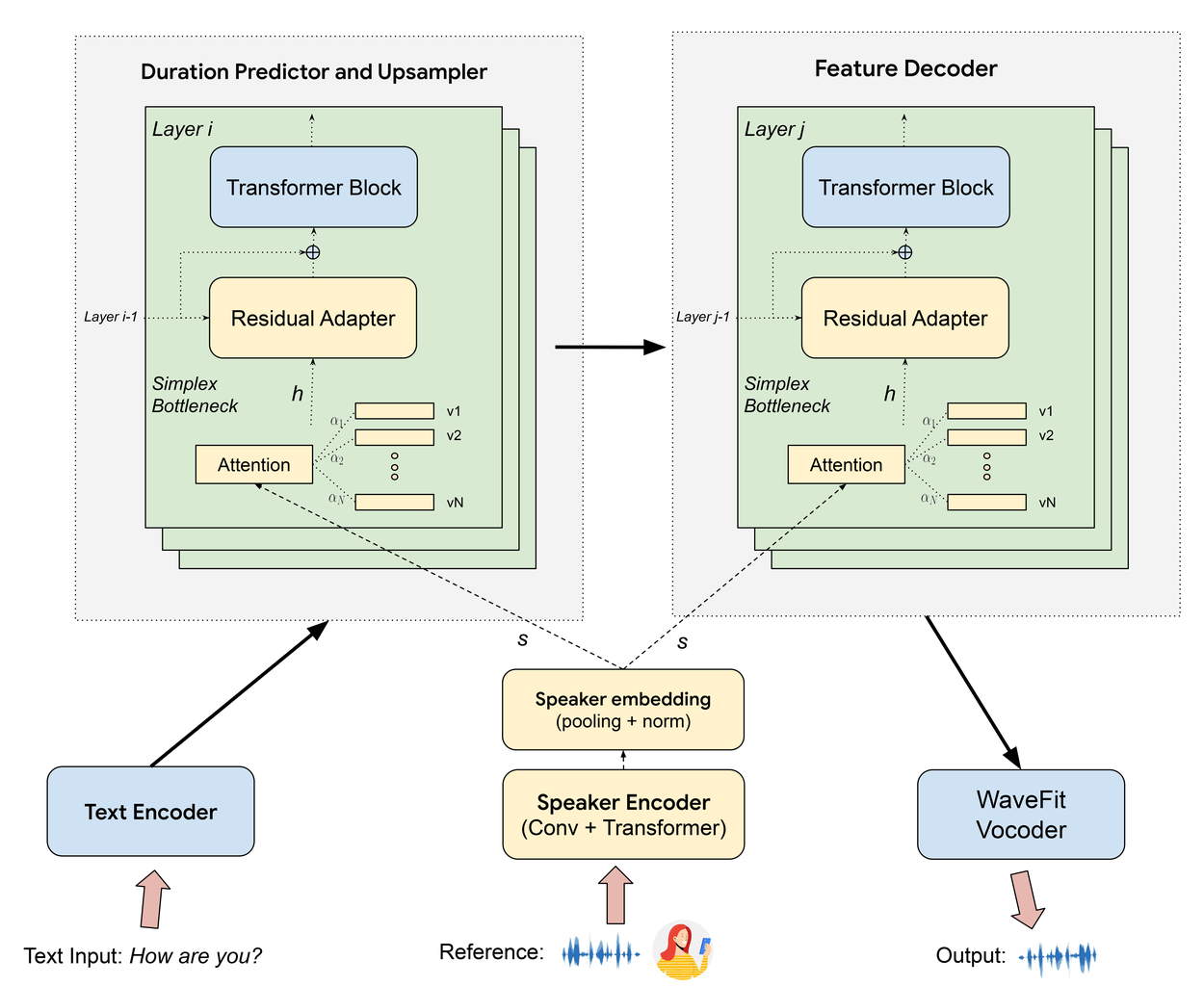
TTS model architecture with voice transfer.
The VT speaker encoder takes a spectrogram from a reference voice of 2–14 seconds. It extracts a high-level representation to summarize the acoustic-phonetic and prosodic characteristics of the input reference speech into an embedding vector. This vector is then passed to all layers of duration and feature decoders.
In each of those layers, we add a 1024-dimensional simplex bottleneck layer (based on global style token) to constrain the embedding vectors to lie within a simplex. This layer also helps ensure the embedding space continuity and completeness. The simplex itself can be learned during training. We find that this choice of bottleneck is crucial to modeling zero-shot capability for unseen voices, especially for speakers with atypical speech.
Finally, the output of the bottleneck layer is concatenated with the previous layer’s output and is given to a residual adapter added between each two consecutive layers. Using residual adapters makes the model modular — i.e., one can plug and unplug this VT module to a pre-trained TTS model without impacting the quality of the original TTS model. Additionally, they enable us to adapt and dedicate a very small set of parameters for each target voice to perform few-shot training, to perfect a target voice when banked-speech is enabled. Given their parameter-efficient nature, these adapters can be loaded on-demand.
Model training
We follow a previously defined procedure using multilingual training data to obtain a multilingual TTS system that includes our VT extension. With the model now accepting both text and reference speech, we pass a random consecutive chunk (2–14 seconds) from the target speech as a reference in each training sample. Using random chunks helps prevent leakage of durational and linguistic information. Recall that since the model is trained on multilingual data, the VT module is multilingual.
Experiments
Typical voice samples
Below are zero-shot examples using typical reference speech, to demonstrate when the speaker's voice was recorded before any voice degradation occurred. We demonstrate the concept of zero-shot capability using samples from the VCTK corpus (full list of audio samples on our GitHub repo):
|
Reference |
TTS with Zero-shot VT |
|
|---|---|---|
|
Female (P257) |
||
|
Male (P256) |
||
|
Female (P244) |
||
|
Male (P243) |
We have done a subjective similarity evaluation of 500 pairs of audio, where each pair includes reference audio and synthesized speech of sentences generated by an LLM (using Gemini API). Each pair is presented to five human raters who are asked whether the two samples are spoken by the same person. We found that on average 76% (± 3.6) of those raters indicate that the two samples came from the same speaker.
Case study: Atypical speech as a reference
To demonstrate the system’s performance when atypical speech/voice is the only reference available, we worked with our fellow Google research scientist Dimitri Kanevsky who is profoundly deaf from a young age and learned to speak English using Russian phonetics. As a result, Dimitri has never had a typical voice. His speech patterns are unique and may be difficult for unfamiliar listeners to understand. Using only 12 seconds of Dimitri’s atypical voice as a reference, we synthesize the transcript of the following original video to generate the output video presented below.
Left: Original; Right: VT - Output
The transcript was obtained using Dimitri’s personalized ASR model described in our previous work. Since Dimitri can’t hear this video, we asked 10 subjects who have a working relationship with Dimitri to score (1 to 10) of how similar the output voice is to that of Dimitri’s. We obtained an average of 8.1/10 (± 1.1).
As a second case study, we worked with Aubrie Lee, a Googler and advocate for disability inclusion who has muscular dystrophy, a condition that causes progressive muscle weakness and sometimes impacts speech production. Like Dimitri, Aubrie has never had a typical speech. Similar to our procedure above, using our zero-shot model, we give the model about 14 seconds of atypical reference speech and use the model to synthesize the automatic transcript of the following video.
Left: Original; Right: VT - Output
We asked Aubrie to score how similar she thinks the output voice is to hers and she gave it 8/10.
Cross-lingual experiments
As discussed above, the TTS system with VT module is trained on multilingual data. We test whether our model that makes use of the same atypical English reference speech from Dimitri and Aubrie can generalize and transfer their voice to other languages, given non-English text. To do so, we first call GeminiAPI to translate the English video transcripts to four target languages. We then use our model and their English speech references to synthesize the translations. Giving the output synthesis to our video generation tool, we automatically produce the following voice transfer of the videos:
Below are VT outputs in six different languages for Dimitri (French, Spanish, Italian, Arabic, German, Russian):
Left to Right; Top to Bottom:
French - Spanish
Italian - Arabic
German - Russian
Below are VT outputs in six different languages for Aubrie (French, Spanish, Italian, Arabic, Hindi, Norwegian):
Left to Right; Top to Bottom:
French - Spanish
Italian - Arabic
Hindi - Norwegian
We also test the cross-lingual capability of our TTS zero-shot model using English and typical reference speech across six languages, using reference speakers from the VCTK corpus. The transcripts and their translations were automatically generated using Gemini.
We conducted another set of cross-lingual subjective evaluations and found that on average 73.1% (± 4.7) of the human raters think the speakers in the given English references and the automatically translated synthesized utterances are spoken by the same speakers. All our raters are native speakers of the corresponding tested language. We also report a mean opinion score (MOS; from 1–5) for each language, measuring the naturalness and quality of the output audio of our TTS system.
|
Reference |
English |
Chinese Mandarin |
Spanish |
Arabic |
French |
Japanese |
German |
|
|---|---|---|---|---|---|---|---|---|
|
Male (P246) |
||||||||
|
Female (P303) |
||||||||
|
Male (P285) |
||||||||
|
Female (P244) |
||||||||
|
Speaker Similarity |
85% |
76% |
70% |
62% |
74% |
75% |
70% |
70% |
|
MOS |
3.300 |
3.621 |
3.921 |
3.606 |
4.242 |
4.058 |
3.616 |
3.985 |
Voice transfer concerns
We recognize that in the context of voice transfer technology, the potential for misuse of synthesized speech is a growing concern. To address this, we use audio watermarking to embed watermarks so synthesized speech from our model can be detected. This technique involves embedding imperceptible information within the synthesized audio waveform. This hidden data can be detected using specialized software, enabling the identification of potentially manipulated or misused audio content. It's important to note that the risk of misuse is significantly lower for individuals who have never had typical speech patterns. In such cases, the synthesized nature of the output would be readily apparent, minimizing the potential for deception.
Acknowledgments
We would like to express our gratitude to Aubrie Lee, Dimitri Kanevsky, Kyle Kastner, Isaac Elias, Gary Wang, Andrew Rosenberg, Takaaki Saeki, Yuma Koizumi, Bhuvana Ramabhadran, Françoise Beaufays, RJ Skerry-Ryan, Ron Weiss, Zoe Ortiz, and the rest of Google’s speech team for their helpful feedback and contributions to this project.
Quick links
Other posts of interest
-
July 17, 2019
Parrotron: New Research into Improving Verbal Communication for People with Speech Impairments- Human-Computer Interaction and Visualization ·
- Responsible AI ·
- Speech Processing
-
August 13, 2019
Project Euphonia’s Personalized Speech Recognition for Non-Standard Speech- Conferences & Events ·
- Human-Computer Interaction and Visualization ·
- Speech Processing