
Accelerated Training and Inference with the Tensorflow Object Detection API
July 13, 2018
Posted by Jonathan Huang, Research Scientist and Vivek Rathod, Software Engineer, Google AI Perception
Quick links
Last year we announced the TensorFlow Object Detection API, and since then we’ve released a number of new features, such as models learned via Neural Architecture Search, instance segmentation support and models trained on new datasets such as Open Images. We have been amazed at how it is being used – from finding scofflaws on the streets of NYC to diagnosing diseases on cassava plants in Tanzania.
 Today, as part of Google’s commitment to democratizing computer vision, and using feedback from the research community on how to make this codebase even more useful, we’re excited to announce a number of additions to our API. Highlights of this release include:
Today, as part of Google’s commitment to democratizing computer vision, and using feedback from the research community on how to make this codebase even more useful, we’re excited to announce a number of additions to our API. Highlights of this release include:- Support for accelerated training of object detection models via Cloud TPUs
- Improving the mobile deployment process by accelerating inference and making it easy to export a model to mobile with the TensorFlow Lite format
- Several new model architecture definitions including:
- RetinaNet (Lin et al., 2017)
- A MobileNet adaptation of RetinaNet
- A novel SSD-based architecture called the Pooling Pyramid Network (PPN) whose model size is >3x smaller than that of SSD MobileNet v1 with minimal loss in accuracy.
Accelerated Training via Cloud TPUs
Users spend a great deal of time on optimizing hyperparameters and retraining object detection models, therefore having fast turnaround times on experiments is critical. The models released today belong to the single shot detector (SSD) class of architectures that are optimized for training on Cloud TPUs. For example, we can now train a ResNet-50 based RetinaNet model to achieve 35% mean Average Precision (mAP) on the COCO dataset in < 3.5 hrs.

To better support low-latency requirements on mobile and embedded devices, the models we are providing are now natively compatible with TensorFlow Lite, which enables on-device machine learning inference with low latency and a small binary size. As part of this, we have implemented: (1) model quantization and (2) detection-specific operations natively in TensorFlow Lite. Our model quantization follows the strategy outlined in Jacob et al. (2018) and the whitepaper by Krishnamoorthi (2018) which applies quantization to both model weights and activations at training and inference time, yielding smaller models that run faster.
 |
| Quantized detection models are faster and smaller (e.g., a quantized 75% depth-reduced SSD Mobilenet model runs at >15 fps on a Pixel 2 CPU with a 4.2 Mb footprint) with minimal loss in detection accuracy compared to the full floating point model. |
To get started training your own model on Cloud TPUs, check out our new tutorial! This walkthrough will take you through the process of training a quantized pet face detector on Cloud TPU then exporting it to an Android phone for inference via TensorFlow Lite conversion.
We hope that these new additions will help make high-quality computer vision models accessible to anyone wishing to solve an object detection problem, and provide a more seamless user experience, from training a model with quantization to exporting to a TensorFlow Lite model ready for on-device deployment. We would like to thank everyone in the community who have contributed features and bug fixes. As always, contributions to the codebase are welcome, and please stay tuned for more updates!
Acknowledgements
This post reflects the work of the following group of core contributors: Derek Chow, Aakanksha Chowdhery, Jonathan Huang, Pengchong Jin, Zhichao Lu, Vivek Rathod, Ronny Votel and Xiangxin Zhu. We would also like to thank the following colleagues: Vasu Agrawal, Sourabh Bajaj, Chiachen Chou, Tom Jablin, Wenzhe Li, Tsung-Yi Lin, Hernan Moraldo, Kevin Murphy, Sara Robinson, Andrew Selle, Shashi Shekhar, Yash Sonthalia, Zak Stone, Pete Warden and Menglong Zhu.
Quick links
Other posts of interest
-
January 22, 2025
Parfait: Enabling private AI with research tools- Distributed Systems & Parallel Computing ·
- Generative AI ·
- Responsible AI ·
- Security, Privacy and Abuse Prevention
-
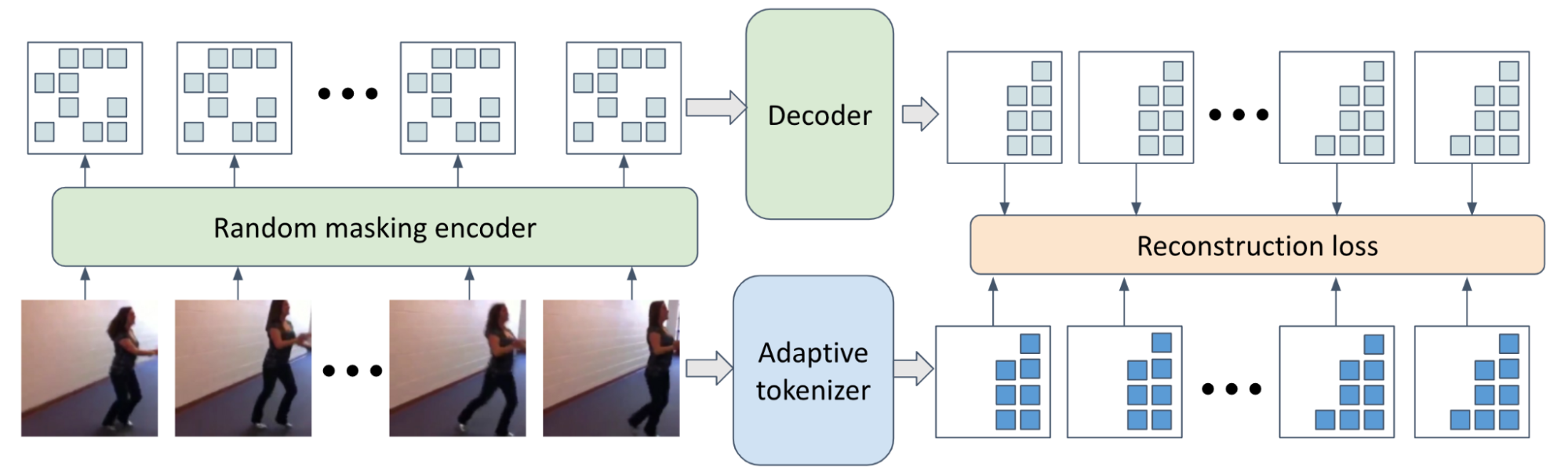
December 4, 2024
Extending video masked autoencoders to 128 frames- Machine Intelligence ·
- Machine Perception
-
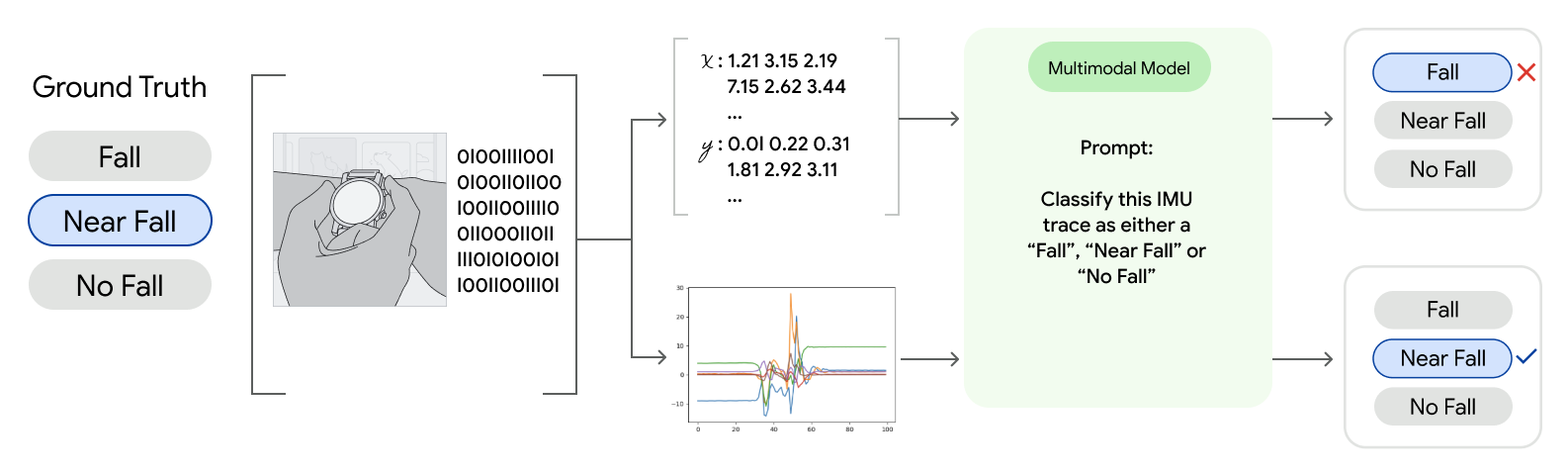
November 25, 2024
Unlocking the power of time-series data with multimodal models- Generative AI ·
- Machine Intelligence ·
- Machine Perception