Language-Agnostic BERT Sentence Embedding
August 18, 2020
Posted by Yinfei Yang and Fangxiaoyu Feng, Software Engineers, Google Research
Quick links
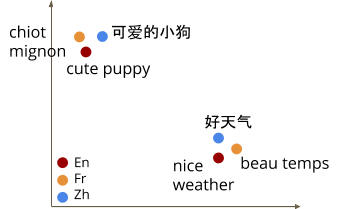
A multilingual embedding model is a powerful tool that encodes text from different languages into a shared embedding space, enabling it to be applied to a range of downstream tasks, like text classification, clustering, and others, while also leveraging semantic information for language understanding. Existing approaches for generating such embeddings, like LASER or m~USE, rely on parallel data, mapping a sentence from one language directly to another language in order to encourage consistency between the sentence embeddings. While these existing multilingual approaches yield good overall performance across a number of languages, they often underperform on high-resource languages compared to dedicated bilingual models, which can leverage approaches like translation ranking tasks with translation pairs as training data to obtain more closely aligned representations. Further, due to limited model capacity and the often poor quality of training data for low-resource languages, it can be difficult to extend multilingual models to support a larger number of languages while maintaining good performance.
 |
| Illustration of a multilingual embedding space. |
Recent efforts to improve language models include the development of masked language model (MLM) pre-training, such as that used by BERT, ALBERT and RoBERTa. This approach has led to exceptional gains across a wide range of languages and a variety of natural language processing tasks since it only requires monolingual text. In addition, MLM pre-training has been extended to the multilingual setting by modifying MLM training to include concatenated translation pairs, known as translation language modeling (TLM), or by simply introducing pre-training data from multiple languages. However, while the internal model representations learned during MLM and TLM training are helpful when fine-tuning on downstream tasks, without a sentence level objective, they do not directly produce sentence embeddings, which are critical for translation tasks.
In “Language-agnostic BERT Sentence Embedding”, we present a multilingual BERT embedding model, called LaBSE, that produces language-agnostic cross-lingual sentence embeddings for 109 languages. The model is trained on 17 billion monolingual sentences and 6 billion bilingual sentence pairs using MLM and TLM pre-training, resulting in a model that is effective even on low-resource languages for which there is no data available during training. Further, the model establishes a new state of the art on multiple parallel text (a.k.a. bitext) retrieval tasks. We have released the pre-trained model to the community through tfhub, which includes modules that can be used as-is or can be fine-tuned using domain-specific data.
 |
| The collection of the training data for 109 supported languages |
The Model
In previous work, we proposed the use of a translation ranking task to learn a multilingual sentence embedding space. This approach tasks the model with ranking the true translation over a collection of sentences in the target language, given a sentence in the source language. The translation ranking task is trained using a dual encoder architecture with a shared transformer encoder. The resulting bilingual models achieved state-of-the-art performance on multiple parallel text retrieval tasks (including United Nations and BUCC). However, the model suffered when the bi-lingual models were extended to support multiple languages (16 languages, in our test case) due to limitations in model capacity, vocabulary coverage, training data quality and more.
| Translation ranking task. Given a sentence in a given source language, the task is to find the true translation over a collection of sentences in the target language. |
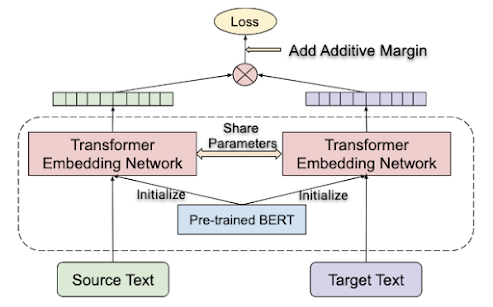
For LaBSE, we leverage recent advances on language model pre-training, including MLM and TLM, on a BERT-like architecture and follow this with fine-tuning on a translation ranking task. A 12-layer transformer with a 500k token vocabulary pre-trained using MLM and TLM on 109 languages is used to increase the model and vocabulary coverage. The resulting LaBSE model offers extended support to 109 languages in a single model.
 |
| The dual encoder architecture, in which the source and target text are encoded using a shared transformer embedding network separately. The translation ranking task is applied, forcing the text that paraphrases each other to have similar representations. The transformer embedding network is initialized from a BERT checkpoint trained on MLM and TLM tasks. |
Performance on Cross-lingual Text Retrieval
We evaluate the proposed model using the Tatoeba corpus, a dataset consisting of up to 1,000 English-aligned sentence pairs for 112 languages. For more than 30 of the languages in the dataset, the model has no training data. The model is tasked with finding the nearest neighbor translation for a given sentence, which it calculates using the cosine distance.
To understand the performance of the model for languages at the head or tail of the training data distribution, we divide the set of languages into several groups and compute the average accuracy for each set. The first 14-language group is selected from the languages supported by m~USE, which cover the languages from the head of the distribution (head languages). We also evaluate a second language group composed of 36 languages from the XTREME benchmark. The third 82-language group, selected from the languages covered by the LASER training data, includes many languages from the tail of the distribution (tail languages). Finally, we compute the average accuracy for all languages.
The table below presents the average accuracy achieved by LaBSE, compared to the m~USE and LASER models, for each language group. As expected, all models perform strongly on the 14-language group that covers most head languages. With more languages included, the averaged accuracy for both LASER and LaBSE declines. However, the reduction in accuracy from the LaBSE model with increasing numbers of languages is much less significant, outperforming LASER significantly, particularly when the full distribution of 112 languages is included (83.7% accuracy vs. 65.5%).
| Model | 14 Langs | 36 Langs | 82 Langs | All Langs |
| m~USE* | 93.9 | — | — | — |
| LASER | 95.3 | 84.4 | 75.9 | 65.5 |
| LaBSE | 95.3 | 95.0 | 87.3 | 83.7 |
| Average Accuracy (%) on Tatoeba Datasets. The “14 Langs” group consists of languages supported by m~USE; the “36 Langs” group includes languages selected by XTREME; and the “82 Langs” group represents languages covered by the LASER model. The “All Langs” group includes all languages supported by Taoteba. * The m~USE model comes in two varieties, one built on a convolutional neural network architecture and the other a Transformer-like architecture. Here, we compare only to the Transformer version. |
Support to Unsupported Languages
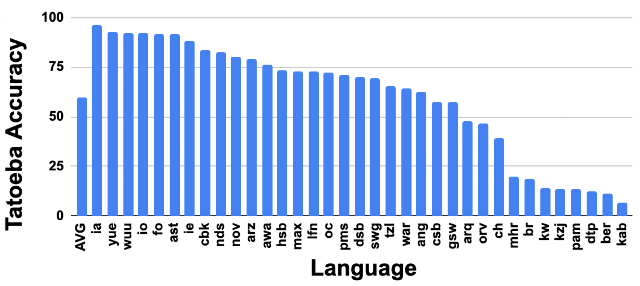
The average performance of all languages included in Tatoeba is very promising. Interestingly, LaBSE even performs relatively well for many of the 30+ Tatoeba languages for which it has no training data (see below). For one third of these languages the LaBSE accuracy is higher than 75% and only 8 have accuracy lower than 25%, indicating very strong transfer performance to languages without training data. Such positive language transfer is only possible due to the massively multilingual nature of LaBSE.
 |
| LaBSE accuracy for the subset of Tatoeba languages (represented with ISO 639-1/639-2 codes) for which there was no training data. |
Mining Parallel Text from Web LaBSE can be used for mining parallel text (bi-text) from web-scale data. For example, we applied LaBSE to CommonCrawl, a large-scale monolingual corpus, to process 560 million Chinese and 330 million German sentences for the extraction of parallel text. Each Chinese and German sentence pair is encoded using the LaBSE model and then the encoded embedding is used to find a potential translation from a pool of 7.7 billion English sentences pre-processed and encoded by the model. An approximate nearest neighbor search is employed to quickly search through the high-dimensional sentence embeddings. After a simple filtering, the model returns 261M and 104M potential parallel pairs for English-Chinese and English-German, respectively. The trained NMT model using the mined data reaches BLEU scores of 35.7 and 27.2 on the WMT translation tasks (wmt17 for English-to-Chinese and wmt14 for English-to-German). The performance is only a few points away from current state-of-art-models trained on high quality parallel data.
Conclusion We're excited to share this research, and the model, with the community. The pre-trained model is released at tfhub to support further research on this direction and possible downstream applications. We also believe that what we're showing here is just the beginning, and there are more important research problems to be addressed, such as building better models to support all languages.
Acknowledgements The core team includes Wei Wang, Naveen Arivazhagan, Daniel Cer. We would like to thank the Google Research Language team, along with our partners in other Google groups for their feedback and suggestions. Special thanks goes to Sidharth Mudgal, and Jax Law for help with data processing; as well as Jialu Liu, Tianqi Liu, Chen Chen, and Anosh Raj for help on BERT pre-training.
Quick links
Other posts of interest
-

March 12, 2026
Introducing Groundsource: Turning news reports into data with Gemini- Climate & Sustainability ·
- Generative AI ·
- Natural Language Processing ·
- Open Source Models & Datasets
-

March 6, 2026
WAXAL: A large-scale open resource for African language speech technology- Natural Language Processing ·
- Open Source Models & Datasets
-

March 4, 2026
Teaching LLMs to reason like Bayesians- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing