Mitigating Unfair Bias in ML Models with the MinDiff Framework
November 16, 2020
Posted by Flavien Prost, Senior Software Engineer and Alex Beutel, Staff Research Scientist, Google Research
Quick links
The responsible research and development of machine learning (ML) can play a pivotal role in helping to solve a wide variety of societal challenges. At Google, our research reflects our AI Principles, from helping to protect patients from medication errors and improving flood forecasting models, to presenting methods that tackle unfair bias in products, such as Google Translate, and providing resources for other researchers to do the same.
One broad category for applying ML responsibly is the task of classification — systems that sort data into labeled categories. At Google, such models are used throughout our products to enforce policies, ranging from the detection of hate speech to age-appropriate content filtering. While these classifiers serve vital functions, it is also essential that they are built in ways that minimize unfair biases for users.
Today, we are announcing the release of MinDiff, a new regularization technique available in the TF Model Remediation library for effectively and efficiently mitigating unfair biases when training ML models. In this post, we discuss the research behind this technique and explain how it addresses the practical constraints and requirements we’ve observed when incorporating it in Google’s products.
Unfair Biases in Classifiers
To illustrate how MinDiff can be used, consider an example of a product policy classifier that is tasked with identifying and removing text comments that could be considered toxic. One challenge is to make sure that the classifier is not unfairly biased against submissions from a particular group of users, which could result in incorrect removal of content from these groups.
The academic community has laid a solid theoretical foundation for ML fairness, offering a breadth of perspectives on what unfair bias means and on the tensions between different frameworks for evaluating fairness. One of the most common metrics is equality of opportunity, which, in our example, means measuring and seeking to minimize the difference in false positive rate (FPR) across groups. In the example above, this means that the classifier should not be more likely to incorrectly remove safe comments from one group than another. Similarly, the classifier’s false negative rate should be equal between groups. That is, the classifier should not miss toxic comments against one group more than it does for another.
When the end goal is to improve products, it’s important to be able to scale unfair bias mitigation to many models. However, this poses a number of challenges:
- Sparse demographic data: The original work on equality of opportunity proposed a post-processing approach to the problem, which consisted of assigning each user group a different classifier threshold at serving time to offset biases of the model. However, in practice this is often not possible for many reasons, such as privacy policies. For example, demographics are often collected by users self-identifying and opting in, but while some users will choose to do this, others may choose to opt-out or delete data. Even for in-process solutions (i.e., methods that change how a model is trained) one needs to assume that most data will not have associated demographics, and thus needs to make efficient use of the few examples for which demographics are known.
- Ease of Use: In order for any technique to be adopted broadly, it should be easy to incorporate into existing model architectures, and not be highly sensitive to hyperparameters. While an early approach to incorporating ML fairness principles into applications utilized adversarial learning, we found that it too frequently caused models to degenerate during training, which made it difficult for product teams to iterate and made new product teams wary.
- Quality: The method for removing unfair biases should also reduce the overall classification performance (e.g., accuracy) as little as possible. Because any decrease in accuracy caused by the mitigation approach could result in the moderation model allowing more toxic comments, striking the right balance is crucial.
MinDiff Framework
We iteratively developed the MinDiff framework over the previous few years to meet these design requirements. Because demographic information is so rarely known, we utilize in-process approaches in which the model’s training objective is augmented with an objective specifically focused on removing biases. This new objective is then optimized over the small sample of data with known demographic information. To improve ease of use, we switched from adversarial training to a regularization framework, which penalizes statistical dependency between its predictions and demographic information for non-harmful examples. This encourages the model to equalize error rates across groups, e.g., classifying non-harmful examples as toxic.
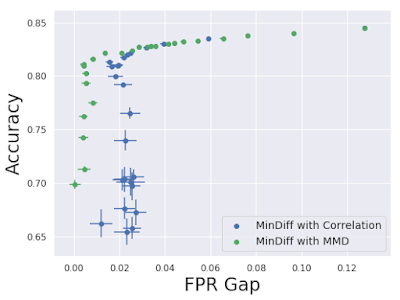
There are several ways to encode this dependency between predictions and demographic information. Our initial MinDiff implementation minimized the correlation between the predictions and the demographic group, which essentially optimized for the average and variance of predictions to be equal across groups, even if the distributions still differ afterward. We have since improved MinDiff further by considering the maximum mean discrepancy (MMD) loss, which is closer to optimizing for the distribution of predictions to be independent of demographics. We have found that this approach is better able to both remove biases and maintain model accuracy.
 |
| MinDiff with MMD better closes the FPR gap with less decrease in accuracy (on an academic benchmark dataset). |
To date we have launched modeling improvements across several classifiers at Google that moderate content quality. We went through multiple iterations to develop a robust, responsible, and scalable approach, solving research challenges and enabling broad adoption.
Gaps in error rates of classifiers is an important set of unfair biases to address, but not the only one that arises in ML applications. For ML researchers and practitioners, we hope this work can further advance research toward addressing even broader classes of unfair biases and the development of approaches that can be used in practical applications. In addition, we hope that the release of the MinDiff library and the associated demos and documentation, along with the tools and experience shared here, can help practitioners improve their models and products.
Acknowledgements
This research effort on ML Fairness in classification was jointly led with Jilin Chen, Shuo Chen, Ed H. Chi, Tulsee Doshi, and Hai Qian. Further, this work was pursued in collaboration with Jonathan Bischof, Qiuwen Chen, Cristos Goodrow, Pierre Kreitmann, and Christine Luu. The MinDiff infrastructure was also developed in collaboration with Nick Blumm, James Chen, Thomas Greenspan, Christina Greer, Lichan Hong, Manasi Joshi, Maciej Kula, Summer Misherghi, Dan Nanas, Sean O'Keefe, Mahesh Sathiamoorthy, Catherina Xu, and Zhe Zhao. Further, this post was written with significant feedback and guidance from Reena Jana. (All names are listed in alphabetical order of last names.)
Quick links
Other posts of interest
-

June 30, 2026
Introducing TabFM: A zero-shot foundation model for tabular data- Data Management ·
- Machine Intelligence ·
- Product
-

June 10, 2026
New framework for auditing machine unlearning- Algorithms & Theory ·
- Responsible AI ·
- Security, Privacy and Abuse Prevention
-

June 5, 2026
Unlocking dependable responses with Gemini Enterprise Agent Platform’s Agentic RAG- Data Management ·
- Machine Intelligence ·
- Natural Language Processing ·
- Product