Large Scale Language Modeling in Automatic Speech Recognition
October 31, 2012
Posted by Ciprian Chelba, Research Scientist
Quick links
The language model is the component of a speech recognizer that assigns a probability to the next word in a sentence given the previous ones. As an example, if the previous words are “new york”, the model would assign a higher probability to “pizza” than say “granola”. The n-gram approach to language modeling (predicting the next word based on the previous n-1 words) is particularly well-suited to such large amounts of data: it scales gracefully, and the non-parametric nature of the model allows it to grow with more data. For example, on Voice Search we were able to train and evaluate 5-gram language models consisting of 12 billion n-grams, built using large vocabularies (1 million words), and trained on as many as 230 billion words.
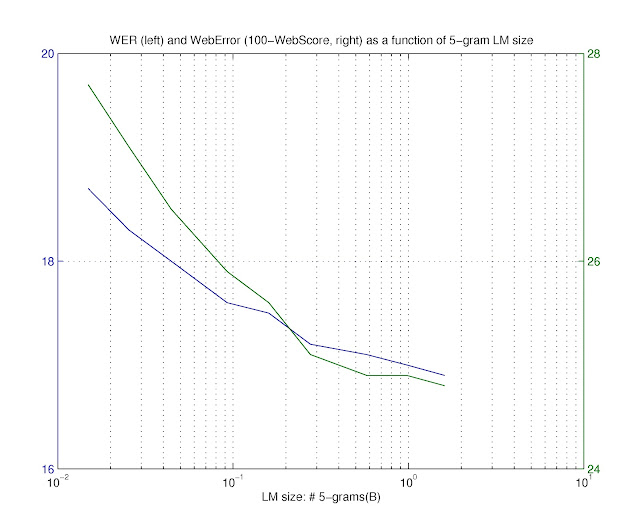
.jpg)
The computational effort pays off, as highlighted by the plot above: both word error rate (a measure of speech recognition accuracy) and search error rate (a metric we use to evaluate the output of the speech recognition system when used in a search engine) decrease significantly with larger language models.
A more detailed summary of results on Voice Search and a few YouTube speech transcription tasks (authors: Ciprian Chelba, Dan Bikel, Maria Shugrina, Patrick Nguyen, Shankar Kumar) presents our results when increasing both the amount of training data, and the size of the language model estimated from such data. Depending on the task, availability and amount of training data used, as well as language model size and the performance of the underlying speech recognizer, we observe reductions in word error rate between 6% and 10% relative, for systems on a wide range of operating points.
Quick links
Other posts of interest
-

July 30, 2026
Science One Framework: A verifiable autonomous research framework via Chain-of-Evidence- General Science ·
- Machine Intelligence ·
- Natural Language Processing
-

July 22, 2026
SymptomAI: Towards a conversational AI agent for everyday symptom assessment- General Science ·
- Health & Bioscience ·
- Natural Language Processing ·
- Responsible AI
-

June 26, 2026
Accelerating Gemini Nano models on Pixel with frozen Multi-Token Prediction- Machine Intelligence ·
- Mobile Systems ·
- Natural Language Processing
×
❮
❯
.jpg)