
Four years of Schema.org - Recent Progress and Looking Forward
December 17, 2015
Posted by Ramanathan Guha, Google Fellow
Quick links
In 2011, we announced schema.org, a new initiative from Google, Bing and Yahoo! to create and support a common vocabulary for structured data markup on web pages. Since that time, schema.org has been a resource for webmasters looking to add markup to their pages so that search engines can use that data to index content better and surface it in new experiences like rich snippets, GMail, and the Google App.
Schema.org, which provides a growing vocabulary for describing various kinds of entity in terms of properties and relationships, has become increasingly important as the Web transitions to a multi-device, mobile-oriented world. We are now seeing schema.org being used on many millions of Web sites, defining data types and properties common across applications, platforms and products, in order to enhance the user experience by delivering the most relevant information they need, when they need it.
 |
| Schema.org in Google Rich Snippets |
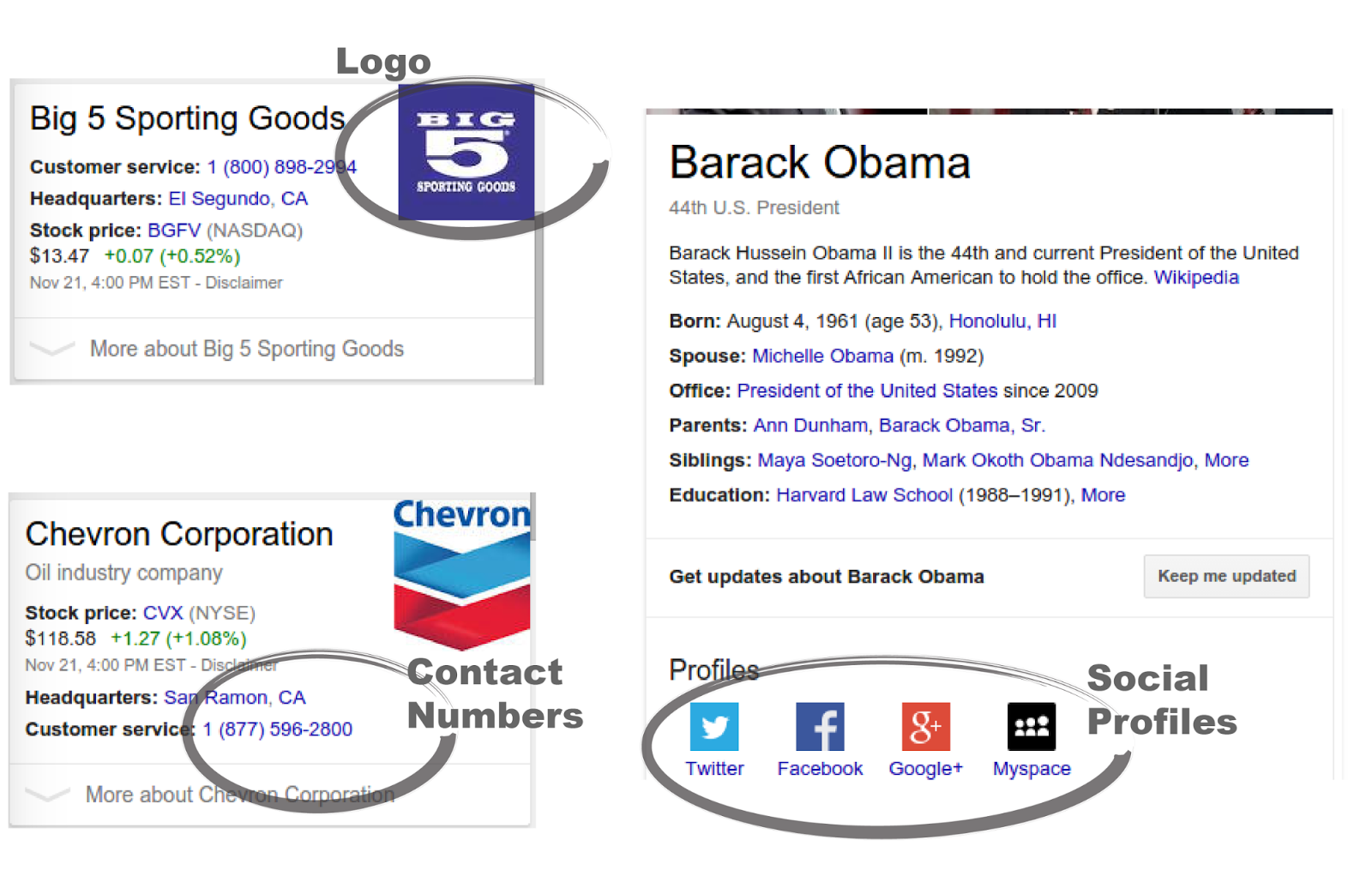 |
| Schema.org in Google Knowledge Graph panels |
 |
| Schema.org in Recipe carousels |
The schema.org group at W3C is now amongst the largest active W3C communities, serving as a hub for diverse groups exploring schemas covering diverse topics such as sports, healthcare, e-commerce, food packaging, bibliography and digital archive management. Other companies, also make use of the same data to build different applications, and as new use cases arise further schemas are integrated via community discussion at W3C. Each of these topics in turn have subtle inter-relationships - for example schemas for food packaging, for flight reservations, for recipes and for restaurant menus, each have different approaches to describing food restrictions and allergies. Rather than try to force a common unified approach across these domains, schema.org's evolution is pragmatic, driven by the combination of available Web data, and the likelihood of mainstream consuming applications.
Schema.org is also finding new kinds of uses. One exciting line of work is the use of schema.org marked up pages as training corpus for machine learning. John Foley, Michael Bendersky and Vanja Josifovski used schema.org data to build a system that can learn to recognize events that may be geographically local to a particular user. Other researchers are looking at using schema.org pages with similar markup, but in different languages, to automatically create parallel corpora for machine translation.
Four years after its launch, Schema.org is entering its next phase, with more of the vocabulary development taking place in a more distributed fashion, as extensions. As schema.org adoption has grown, a number groups with more specialized vocabularies have expressed interest in extending schema.org with their terms. Examples of this include real estate, product, finance, medical and bibliographic information. A number of extensions, for topics ranging from automobiles to product details, are already underway. In such a model, schema.org itself is just the core, providing a unifying vocabulary and congregation forum as necessary.
Quick links
Other posts of interest
-

June 30, 2026
Introducing TabFM: A zero-shot foundation model for tabular data- Data Management ·
- Machine Intelligence ·
- Product
-

June 25, 2026
Optimizing cloud economics with linear elastic caching- Algorithms & Theory ·
- Data Management
-

June 5, 2026
Unlocking dependable responses with Gemini Enterprise Agent Platform’s Agentic RAG- Data Management ·
- Machine Intelligence ·
- Natural Language Processing ·
- Product
×
❮
❯


