System performance
We develop the methodology that informs the roadmap, architecture and design of all computer systems deployed in Google data centers, enabling efficient utilization of our software and hardware infrastructure.
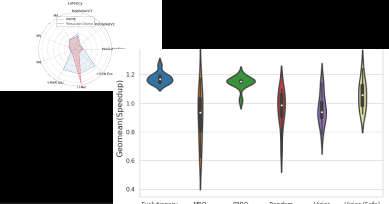
We develop the methodology that informs the roadmap, architecture and design of all computer systems deployed in Google data centers, enabling efficient utilization of our software and hardware infrastructure.
About the team
Our team guides the roadmap, architecture and design of Google’s global computer infrastructure. We bring together experts in computer architecture, machine learning, software systems, compilers and operating systems to define and build the next generation of technology that powers Google.
Our research encompasses the entire system stack, from distributed software and runtime systems to microarchitecture and circuits. We seek to propose new computing substrates and accelerators, build and optimize large-scale real-world systems, research techniques to maximize code efficiency and define new machine-learning-based systems and paradigms. Research and open-ended exploration are key aspects of our work and we seek to share this work externally with the broader research community. We publish at a wide array of conferences, including ISCA, ASPLOS, MICRO, NeurIPS, ICML and ICLR.
Team focus summaries
The combination of the end of Moore’s law and exponential increases in demand for computing and data has created an opportunity to redefine many of the layers that power computing. We architect state-of-the-art hardware accelerators, define new microarchitectures, and drive hardware and software co-design for Google-scale workloads.
Using machine learning to improve computing systems enables us to replace many traditional heuristics within Google’s large-scale systems in the short-term, and a longer-term focus to automate the processes that we use to architect computer systems. We research, propose, and prototype ML-based techniques and then seek to deploy those techniques at scale across Google.
Google’s data centers operate on a global scale. We seek to understand how to optimize a wide range of workloads and computing resources to ensure that Google’s workloads operate at peak performance and efficiency. Research into runtime systems at Google exposes us to the scale and complexity of warehouse computing.
To optimize Google’s workloads, we must understand how they execute at the datacenter scale, which requires cutting-edge research focused on code efficiency, new profiling techniques and co-design across layers of the stack, including operating systems and compilers.
Featured publications
Highlighted work
-
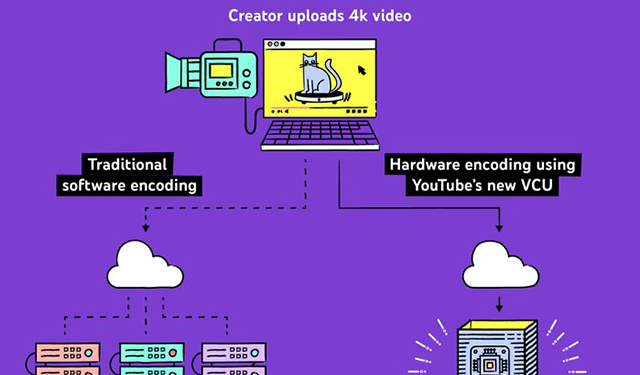 Reimagining video infrastructure to empower YouTubeVideo infrastructure for YouTube
Reimagining video infrastructure to empower YouTubeVideo infrastructure for YouTube -
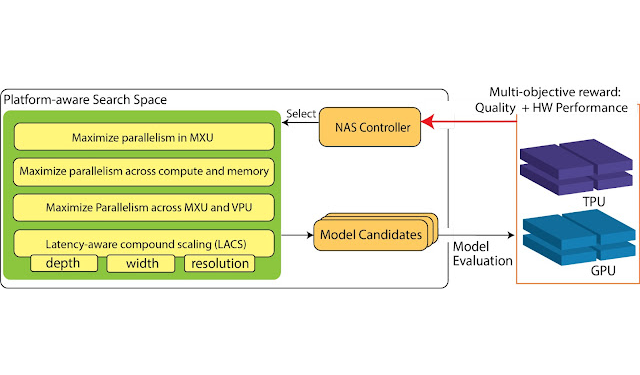 Unlocking the Full Potential of Datacenter ML Accelerators with Platform-Aware Neural ArchitectureHardware-specific ML models
Unlocking the Full Potential of Datacenter ML Accelerators with Platform-Aware Neural ArchitectureHardware-specific ML models -
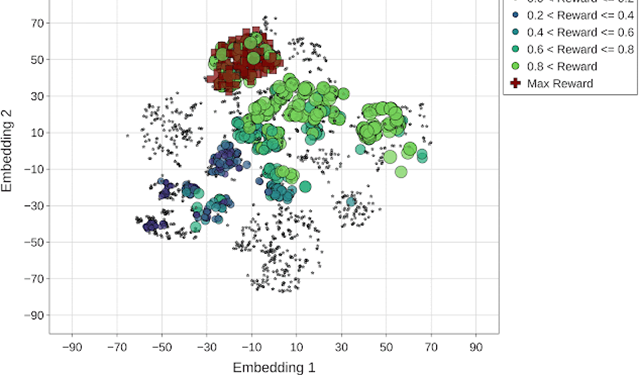 Machine Learning for Computer ArchitectureAutomating computer architecture using machine learning
Machine Learning for Computer ArchitectureAutomating computer architecture using machine learning -
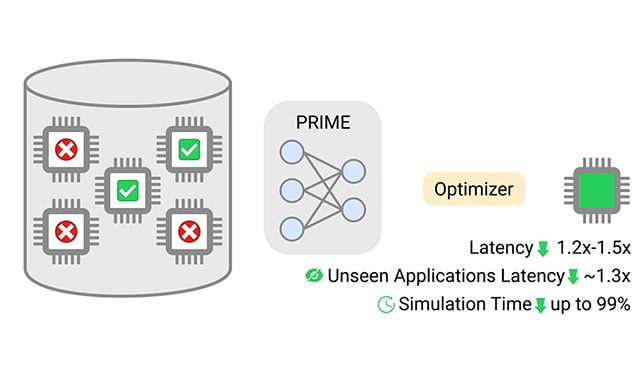 Offline Optimization for Architecting Hardware AcceleratorsLearned models for microarchitectural simulation
Offline Optimization for Architecting Hardware AcceleratorsLearned models for microarchitectural simulation
Some of our locations


Some of our people
-

Milad Hashemi
- Distributed Systems and Parallel Computing
- Hardware and Architecture
- Machine Intelligence
- +1 more
-

Marisabel Guevara Hechtman
- Hardware and Architecture
-

Sundar Dev
- Distributed Systems and Parallel Computing
- Hardware and Architecture
- Software Systems
-

Liqun Cheng
- Distributed Systems and Parallel Computing
- Hardware and Architecture
-

Rama Govindaraju
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
- +5 more
-

Parthasarathy Ranganathan
- Distributed Systems and Parallel Computing
- Hardware and Architecture
- Software Systems
-

Jichuan Chang
- Distributed Systems and Parallel Computing
- Hardware and Architecture
-

Sheng Li
- Distributed Systems and Parallel Computing
- Hardware and Architecture
- Machine Intelligence
-

Kun Lin
- Data Mining and Modeling
- Human-Computer Interaction and Visualization
- Machine Intelligence
- +1 more
