SPICE: Self-Supervised Pitch Estimation
November 14, 2019
Posted by Marco Tagliasacchi, Research Scientist, Google Research
Quick links
A sound’s pitch is a qualitative measure of its frequency, where a sound with a high pitch is higher in frequency than one of low pitch. Through tracking relative differences in pitch, our auditory system is able to recognize audio features, such as a song’s melody. Pitch estimation has received a great deal of attention over the past decades, due to its central importance in several domains, ranging from music information retrieval to speech analysis.
Traditionally, simple signal processing pipelines were proposed to estimate pitch, working either in the time domain (e.g., pYIN) or in the frequency domain (e.g., SWIPE). But until recently, machine learning methods have not been able to outperform such hand-crafted signal processing pipelines. This was due to the lack of annotated data, which is particularly tedious and difficult to obtain at the temporal and frequency resolution required to train fully supervised models. The CREPE model was able to overcome these limitations to achieve state-of-the-art results by training on a synthetically generated dataset combined with other manually annotated datasets.
In our recent paper, we present a different approach to training pitch estimation models in the absence of annotated data. Inspired by the observation that for humans, including professional musicians, it is typically much easier to estimate relative pitch (the frequency interval between two notes) than absolute pitch (the true fundamental frequency), we designed SPICE (Self-supervised PItCh Estimation) to solve a similar task. This approach relies on self-supervision by defining an auxiliary task (also known as a pretext task) that can be learned in a completely unsupervised way.
 |
| Constant-Q transform of an audio clip, superimposed on a representation of pitch as estimated by SPICE (video). |
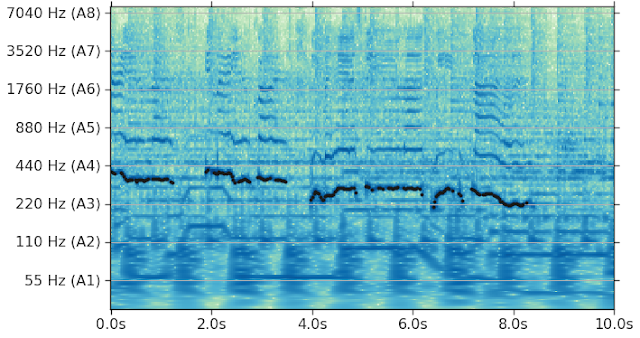
Pitch is well defined only when the underlying signal is harmonic, i.e., when it contains components with integer multiples of the fundamental frequency. So, an important function of the model is to determine when the output is meaningful and reliable. For example, in the figure below, there is no harmonic signal in the interval between 1.2s and 2s resulting in low enough confidence in the pitch estimation that no pitch estimate is generated. SPICE is designed to learn the level of confidence of the pitch estimation in a self-supervised fashion, instead of relying on handcrafted solutions.
 |
| SPICE model architecture (simplified). Two pitch-shifted versions of the same CQT frame are fed to two encoders with shared weights. The loss is designed to make the difference between the outputs of the encoders proportional to the relative pitch difference. In addition (not shown), a reconstruction loss is added to regularize the model. The model also learns to produce the confidence of the pitch estimation. |
 |
| Evaluation on the MIR-1k dataset, mixing in background music at different signal-to-noise ratios. |
Acknowledgments
The work described here was authored by Beat Gfeller, Christian Frank, Dominik Roblek, Matt Sharifi, Marco Tagliasacchi and Mihajlo Velimirović. We are grateful for all discussions and feedback on this work that we received from our colleagues at Google. The SingingVoices dataset used for training the models in this work has been collected by Alexandra Gherghina as part of FreddieMeter, which is using SPICE and a vocal timbre similarity model to understand how closely a singer matches Freddie Mercury.
Quick links
Other posts of interest
-

July 30, 2026
Science One Framework: A verifiable autonomous research framework via Chain-of-Evidence- General Science ·
- Machine Intelligence ·
- Natural Language Processing
-

July 22, 2026
Towards a quantum computer that learns from its errors- Machine Intelligence ·
- Quantum
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
×
❮
❯


