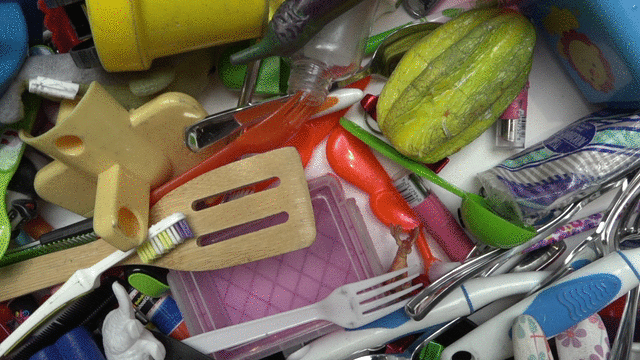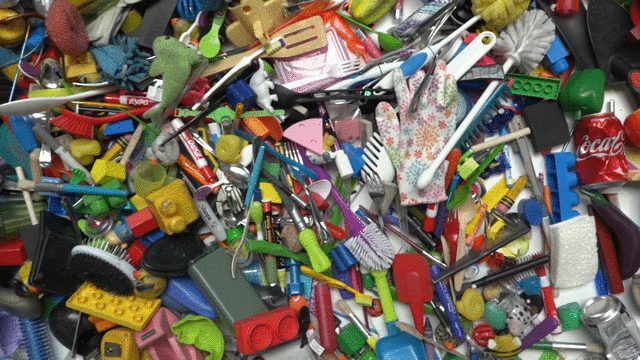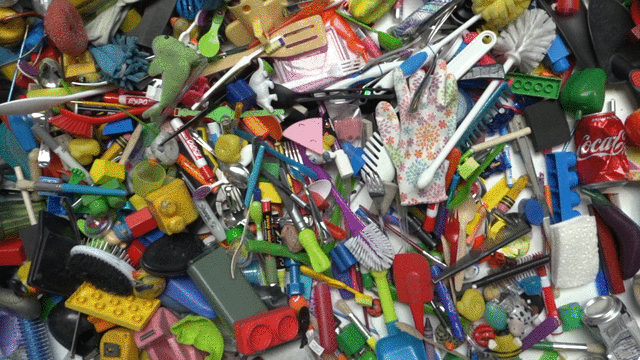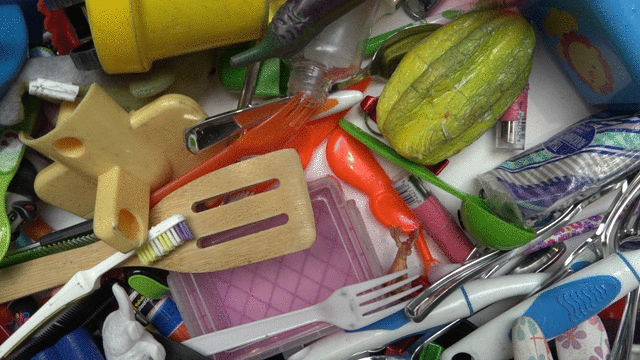Scalable Deep Reinforcement Learning for Robotic Manipulation
June 28, 2018
Posted Alex Irpan, Software Engineer, Google Brain Team and Peter Pastor, Senior Roboticist, X
Quick links
How can robots acquire skills that generalize effectively to diverse, real-world objects and situations? While designing robotic systems that effectively perform repetitive tasks in controlled environments, like building products on an assembly line, is fairly routine, designing robots that can observe their surroundings and decide the best course of action while reacting to unexpected outcomes is exceptionally difficult. However, there are two tools that can help robots acquire such skills from experience: deep learning, which is excellent at handling unstructured real-world scenarios, and reinforcement learning, which enables longer-term reasoning while exhibiting more complex and robust sequential decision making. Combining these two techniques has the potential to enable robots to learn continuously from their experience, allowing them to master basic sensorimotor skills using data rather than manual engineering.
Designing reinforcement learning algorithms for robot learning introduces its own set of challenges: real-world objects span a wide variety of visual and physical properties, subtle differences in contact forces can make predicting object motion difficult and objects of interest can be obstructed from view. Furthermore, robotic sensors are inherently noisy, adding to the complexity. All of these factors makes it incredibly difficult to learn a general solution, unless there is enough variety in the training data, which takes time to collect. This motivates exploring learning algorithms that can effectively reuse past experience, similar to our previous work on grasping which benefited from large datasets. However, this previous work could not reason about the long-term consequences of its actions, which is important for learning how to grasp. For example, if multiple objects are clumped together, pushing one of them apart (called “singulation”) will make the grasp easier, even if doing so does not directly result in a successful grasp.
 |
 |
To be more efficient, we need to use off-policy reinforcement learning, which can learn from data that was collected hours, days, or weeks ago. To design such an off-policy reinforcement learning algorithm that can benefit from large amounts of diverse experience from past interactions, we combined large-scale distributed optimization with a new fitted deep Q-learning algorithm that we call QT-Opt. A preprint is available on arXiv.
QT-Opt is a distributed Q-learning algorithm that supports continuous action spaces, making it well-suited to robotics problems. To use QT-Opt, we first train a model entirely offline, using whatever data we’ve already collected. This doesn’t require running the real robot, making it easier to scale. We then deploy and finetune that model on the real robot, further training it on newly collected data. As we run QT-Opt, we accumulate more offline data, letting us train better models, which lets us collect better data, and so on.
To apply this approach to robotic grasping, we used 7 real-world robots, which ran for 800 total robot hours over the course of 4 months. To bootstrap collection, we started with a hand-designed policy that succeeded 15-30% of the time. Data collection switched to the learned model when it started performing better. The policy takes a camera image and returns how the arm and gripper should move. The offline data contained grasps on over 1000 different objects.
 |
| Some of the training objects used. |
In the past, we’ve seen that sharing experience across robots can accelerate learning. We scaled this training and data gathering process to ten GPUs, seven robots, and many CPUs, allowing us to collect and process a large dataset of over 580,000 grasp attempts. At the end of this process, we successfully trained a grasping policy that runs on a real world robot and generalizes to a diverse set of challenging objects that were not seen at training time.
 |
| Seven robots collecting grasp data. |
Quantitatively, the QT-Opt approach succeeded in 96% of the grasp attempts across 700 trial grasps on previously unseen objects. Compared to our previous supervised-learning based grasping approach, which had a 78% success rate, our method reduced the error rate by more than a factor of five.
 |
 |
Notably, the policy exhibits a variety of closed-loop, reactive behaviors that are often not found in standard robotic grasping systems:
- When presented with a set of interlocking blocks that cannot be picked up together, the policy separates one of the blocks from the rest before picking it up.
- When presented with a difficult-to-grasp object, the policy figures out it should reposition the gripper and regrasp it until it has a firm hold.
- When grasping in clutter, the policy probes different objects until the fingers hold one of them firmly, before lifting.
- When we perturbed the robot by intentionally swatting the object out of the gripper -- something it had not seen during training -- it automatically repositioned the gripper for another attempt.
Crucially, none of these behaviors were engineered manually. They emerged automatically from self-supervised training with QT-Opt, because they improve the model’s long-term grasp success.
 |
 |
Additionally, we’ve found that QT-Opt reaches this higher success rate using less training data, albeit with taking longer to converge. This is especially exciting for robotics, where the bottleneck is usually collecting real robot data, rather than training time. Combining this with other data efficiency techniques (such as our prior work on domain adaptation for grasping) could open several interesting avenues in robotics. We’re also interested in combining QT-Opt with recent work on learning how to self-calibrate, which could further improve the generality.
Overall, the QT-Opt algorithm is a general reinforcement learning approach that’s giving us good results on real world robots. Besides the reward definition, nothing about QT-Opt is specific to robot grasping. We see this as a strong step towards more general robot learning algorithms, and are excited to see what other robotics tasks we can apply it to. You can learn more about this work in the short video below.
Acknowledgements
This research was conducted by Dmitry Kalashnikov, Alex Irpan, Peter Pastor, Julian Ibarz, Alexander Herzog, Eric Jang, Deirdre Quillen, Ethan Holly, Mrinal Kalakrishnan, Vincent Vanhoucke, and Sergey Levine. We’d also like to give special thanks to Iñaki Gonzalo and John-Michael Burke for overseeing the robot operations, Chelsea Finn, Timothy Lillicrap, and Arun Nair for valuable discussions, and other people at Google and X who’ve contributed their expertise and time towards this research. A preprint is available on arXiv.
Quick links
Other posts of interest
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

July 9, 2026
SensorFM: Towards a general intelligence and interface for wearable health data- Generative AI ·
- Machine Intelligence
-

June 30, 2026
Introducing TabFM: A zero-shot foundation model for tabular data- Data Management ·
- Machine Intelligence ·
- Product