Project Euphonia’s Personalized Speech Recognition for Non-Standard Speech
August 13, 2019
Posted by Joel Shor and Dotan Emanuel, Research Engineers, Google Research, Tel Aviv
Quick links
The utility of technology is dependent on its accessibility. One key component of accessibility is automatic speech recognition (ASR), which can greatly improve the ability of those with speech impairments to interact with every-day smart devices. However, ASR systems are most often trained from 'typical' speech, which means that underrepresented groups, such as those with speech impairments or heavy accents, don't experience the same degree of utility. For example, amyotrophic lateral sclerosis (ALS) is a disease that can adversely affect a person’s speech—about 25% of people with ALS experiencing slurred speech as their first symptom. In addition, most people with ALS eventually lose the ability to walk, so being able to interact with automated devices from a distance can be very important. Yet current state-of-the-art ASR models can yield high word error rates (WER) for speakers with only a moderate speech impairment from ALS, effectively barring access to ASR reliant technologies.
In “Personalizing ASR for Dysarthric and Accented Speech with Limited Data,” to be presented at Interspeech 2019, we describe some of the research behind Project Euphonia, an ASR platform that performs speech-to-text transcription. This work presents an approach to improve ASR for people with ALS that may also be applicable to many other types of non-standard speech. Using a two-step training approach that starts with a baseline “standard” corpus and then fine-tunes the training with a personalized speech dataset, we have demonstrated significant improvements for speakers with atypical speech over current state-of-the-art models.
A Two-Phased Approach to Training
In order to create ASR models that work on non-standard speech, one needs to overcome two challenges. The first is that within a particular class of atypical speech, be it a regional accent or a speech impairment, for example, individuals can exhibit very different ways of speaking. Our approach deals with this sub-group heterogeneity by training the ASR model in two phases. We start with a high-quality ASR model trained on thousands of hours of standard speech and then we fine-tune parts of the model to an individual with non-standard speech. This approach is similar to that of Parrotron: both systems use end-to-end neural networks to help improve communication and accessibility, but Parrotron focuses exclusively on speech-to-speech, where a person’s speech is converted directly into synthesized speech, rather than text.
The second challenge arises from the difficulty in collecting enough data to train a state-of-the-art recognizer for individuals. Typical speech recognizers are trained on thousands of hours of speech from many different speakers. Acquiring this much data from a single speaker is nearly impossible, especially if the speaker may experience exhaustion from speaking due to a medical condition. Our approach overcomes this issue by first training a base model on a large corpus of typical speech, and then training a personalized model using a much smaller dataset with the targeted non-standard speech characteristics.
The Neural Network Architecture
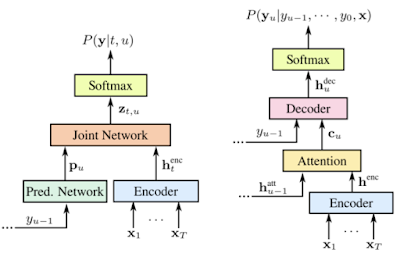
When developing the models used for training data on atypical speech, we explored two different neural architectures. The first is the RNN-Transducer (RNN-T), a neural network architecture consisting of encoder and decoder networks that has shown good results on numerous ASR tasks. The encoder is bidirectional (i.e., it looks at the entire sentence at once in order to provide context), and thus it requires the entire audio sample to perform speech recognition.
The other architecture we explored was Listen, Attend, and Spell (LAS), which is an attention-based, sequence-to-sequence model that maps sequences of acoustic properties to sequences of languages. This model uses an encoder to convert the sequence of acoustic frames to a sequence of internal representations, and a decoder to convert the sequence of internal representations to linguistic output. The network produces “word pieces”, which are a linguistic representation between graphemes and words.
 |
| Comparison of the RNN-Transducer (left) and Listen, Attend, Spell (right) architectures. From Prabhavalkar et al. 2017. |
We also tested accented speech, using the open source L2 Arctic dataset of non-native speech, which consists of 20 speakers with approximately 1 hour of speech per speaker. Each speaker recorded a set of 1150 utterances from the CMU Arctic prompts.
| Audio | Euphonia Model | Standard Speech Model |
|---|---|---|
| Did I have anything to say about it? | Dictatorship angels to think about it | |
| Come right back please | Cameras object | |
| Let’s try that again | It extracts | |
| Turn it down a little bit please | Turning down a little bit please |
| The audio (left) are recordings of a speaker with ALS. The text transcriptions are output from the Euphonia model (center) and the Standard Speech model (right). Incorrectly transcribed text is underlined. |
The absolute word error rates on the language-restricted test set is shown below. There is an improvement over the baseline model for very non-standard speech (heavy accents and ALS speech below 3 on the ALS Functional Rating Scale) and moderate improvements in ALS speech that is similar to typical speech. The relative difference between the base model and the fine-tuned model demonstrates that the majority of the improvement comes from the fine-tuning process, except in the case of the RNN-T on the Arctic dataset, where the RNN-T baseline is already strong.
 |
| 1 Non-native English speech from the L2-Arctic dataset. 2 Low FRS (ALS Functional Rating Scale) speech; intelligible with repeating (FRS 2); Speech combined with non-vocal communication (FRS 1). 3 FRS 3; detectable speech disturbance. |
Most of the performance gains were achieved early in training. The models we trained were tested on a relatively limited domain of vocabulary and linguistic complexity, so the performance numbers are not necessarily related to how well the models perform on more general tasks. We hope that just fine-tuning part of the network allows it to retain the acoustic and linguistic information from the general speech model, while needing minimal modifications to adapt to a single new speaker. Future work will test this hypothesis.
 |
| Low FRS corresponds to the ALS speakers with low intelligibility (FRS 2, 1), while high FRS corresponds to ALS speakers with less severely impacted speech (FRS 3). |
To better understand how our models improved after fine-tuning, we looked at the pattern of phoneme mistakes. We started by comparing the distribution of phoneme mistakes made by the base ASR model on standard speech to the mistakes made on ALS speech. The SAMPA phonemes with the five largest differences between the ALS data and standard speech are p, U, f, k, and Z, which account for 20% of the deletion mistakes. Similarly, the n and m phonemes together account for 17% of the insertion / substitution mistakes. The same analysis on our fine-tuned models verifies that the unrecognized phoneme distribution is more similar to that of standard speech.
Our analysis shows that there are two aspects to every mistake: which phoneme the system doesn’t understand, and which phoneme the system thinks was said. Imagine having two systems with identical accuracy: one system always thinks that the f phoneme is actually the g phoneme, while another doesn't know what the f phoneme is and randomly guesses. These two systems will have identical performance and identical distributions of phoneme mistakes, but very different distributions of the predicted phoneme when a mistake is made. Surprisingly, ASR mistakes on ALS speech are far more similar to regular speech mistakes after Euphonia fine-tuning.
 |
| Deletion / substitution mistakes per SAMPA phoneme on ALS speech before fine-tuning, ALS speech after fine-tuning, and on typical speech (Librispeech dataset). |
In the future, we intend to explore additional techniques that can be helpful in the low data regime. We also hope to use phoneme mistakes to weight certain examples during training, or to pick training sentences for people with ALS to record that contain the most common phoneme mistakes. We would like to explore pooling data from multiple speakers with similar conditions.
We hope that continued research in this area will help voice interfaces become accessible to more people, especially those who need it most. One key component to this is collecting data. Anyone 18 or older can help us build better personalized models by donating audio data. If you’re interested, you can fill out this form to allow Google to contact you.
Acknowledgements
This work would not have been possible without the extraordinary effort and support of the ALS Therapy Development Institute and the ALS community, especially Fernando Vieira, Maeve McNally, Taylor Charbonneau, Melissa Nollstadt, and the individuals with ALS who kindly and patiently volunteered their audio. This work builds on the pioneering advances in speech recognition made by Google's speech team, in particular the recent development and deployment of end-to-end speech recognition models. We are grateful to the Google speech team for advice and collaboration, particularly to Anshuman Tripathi and Hasim Sak who guided us in training the initial models. We’d also like to thank Oran Lang, Omry Tuval, Michael Brenner, Julie Cattiau, Tara Sainath, Ding Zhao, Qiao Liang, Chung-Cheng Chiu, Dan Liebling, Ron Weiss, Anjuli Kannan, Dimitri Kanevsky, Ryan He, Gabor Simko, Benjamin Lee, Françoise Beaufays, Khe Chai Sim, Jimmy Tobin, Chet Gnegy, Jacqueline Huang, Ye Jia, Yu Zhang, Yonghui Wu, Michelle Ramanovich, Rus Heywood, Katrin Tomanek, Bob MacDonald, Pan-Pan Jiang, Ronnie Maor, Rif A. Saurous, Trevor Strohman, Dick Lyon, Avinatan Hassidim, Philip Nelson, and Yossi Matias for their technical contributions and project guidance.
Quick links
Other posts of interest
-

June 12, 2026
Research into how AI can help users understand skin conditions- Health & Bioscience ·
- Human-Computer Interaction and Visualization
-

June 4, 2026
Towards passive heart health monitoring via smartphone camera- Health & Bioscience ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
×
❮
❯



