Distributed differential privacy for federated learning
March 2, 2023
Posted by Florian Hartmann, Software Engineer, and Peter Kairouz, Research Scientist, Google Research
Federated learning is a distributed way of training machine learning (ML) models where data is locally processed and only focused model updates and metrics that are intended for immediate aggregation are shared with a server that orchestrates training. This allows the training of models on locally available signals without exposing raw data to servers, increasing user privacy. In 2021, we announced that we are using federated learning to train Smart Text Selection models, an Android feature that helps users select and copy text easily by predicting what text they want to select and then automatically expanding the selection for them.
Since that launch, we have worked to improve the privacy guarantees of this technology by carefully combining secure aggregation (SecAgg) and a distributed version of differential privacy. In this post, we describe how we built and deployed the first federated learning system that provides formal privacy guarantees to all user data before it becomes visible to an honest-but-curious server, meaning a server that follows the protocol but could try to gain insights about users from data it receives. The Smart Text Selection models trained with this system have reduced memorization by more than two-fold, as measured by standard empirical testing methods.
Scaling secure aggregation
Data minimization is an important privacy principle behind federated learning. It refers to focused data collection, early aggregation, and minimal data retention required during training. While every device participating in a federated learning round computes a model update, the orchestrating server is only interested in their average. Therefore, in a world that optimizes for data minimization, the server would learn nothing about individual updates and only receive an aggregate model update. This is precisely what the SecAgg protocol achieves, under rigorous cryptographic guarantees.
Important to this work, two recent advancements have improved the efficiency and scalability of SecAgg at Google:
- An improved cryptographic protocol: Until recently, a significant bottleneck in SecAgg was client computation, as the work required on each device scaled linearly with the total number of clients (N) participating in the round. In the new protocol, client computation now scales logarithmically in N. This, along with similar gains in server costs, results in a protocol able to handle larger rounds. Having more users participate in each round improves privacy, both empirically and formally.
- Optimized client orchestration: SecAgg is an interactive protocol, where participating devices progress together. An important feature of the protocol is that it is robust to some devices dropping out. If a client does not send a response in a predefined time window, then the protocol can continue without that client’s contribution. We have deployed statistical methods to effectively auto-tune such a time window in an adaptive way, resulting in improved protocol throughput.
The above improvements made it easier and faster to train Smart Text Selection with stronger data minimization guarantees.
Aggregating everything via secure aggregation
A typical federated training system not only involves aggregating model updates but also metrics that describe the performance of the local training. These are important for understanding model behavior and debugging potential training issues. In federated training for Smart Text Selection, all model updates and metrics are aggregated via SecAgg. This behavior is statically asserted using TensorFlow Federated, and locally enforced in Android’s Private Compute Core secure environment. As a result, this enhances privacy even more for users training Smart Text Selection, because unaggregated model updates and metrics are not visible to any part of the server infrastructure.
Differential privacy
SecAgg helps minimize data exposure, but it does not necessarily produce aggregates that guarantee against revealing anything unique to an individual. This is where differential privacy (DP) comes in. DP is a mathematical framework that sets a limit on an individual's influence on the outcome of a computation, such as the parameters of a ML model. This is accomplished by bounding the contribution of any individual user and adding noise during the training process to produce a probability distribution over output models. DP comes with a parameter (ε) that quantifies how much the distribution could change when adding or removing the training examples of any individual user (the smaller the better).
Recently, we announced a new method of federated training that enforces formal and meaningfully strong DP guarantees in a centralized manner, where a trusted server controls the training process. This protects against external attackers who may attempt to analyze the model. However, this approach still relies on trust in the central server. To provide even greater privacy protections, we have created a system that uses distributed differential privacy (DDP) to enforce DP in a distributed manner, integrated within the SecAgg protocol.
Distributed differential privacy
DDP is a technology that offers DP guarantees with respect to an honest-but-curious server coordinating training. It works by having each participating device clip and noise its update locally, and then aggregating these noisy clipped updates through the new SecAgg protocol described above. As a result, the server only sees the noisy sum of the clipped updates.
However, the combination of local noise addition and use of SecAgg presents significant challenges in practice:
- An improved discretization method: One challenge is properly representing model parameters as integers in SecAgg's finite group with integer modular arithmetic, which can inflate the norm of the discretized model and require more noise for the same privacy level. For example, randomized rounding to the nearest integers could inflate the user's contribution by a factor equal to the number of model parameters. We addressed this by scaling the model parameters, applying a random rotation, and rounding to nearest integers. We also developed an approach for auto-tuning the discretization scale during training. This led to an even more efficient and accurate integration between DP and SecAgg.
- Optimized discrete noise addition: Another challenge is devising a scheme for choosing an arbitrary number of bits per model parameter without sacrificing end-to-end privacy guarantees, which depend on how the model updates are clipped and noised. To address this, we added integer noise in the discretized domain and analyzed the DP properties of sums of integer noise vectors using the distributed discrete Gaussian and distributed Skellam mechanisms.
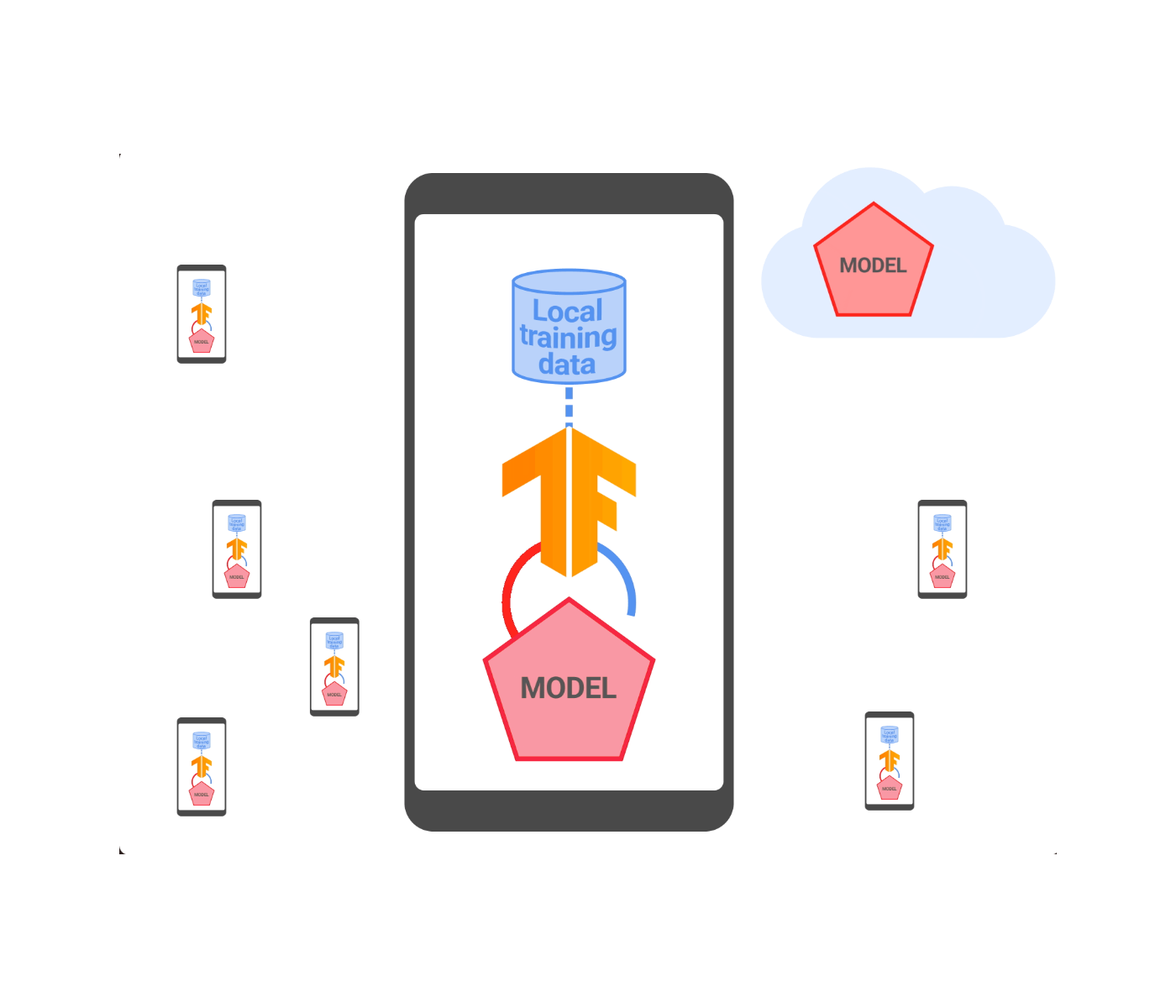
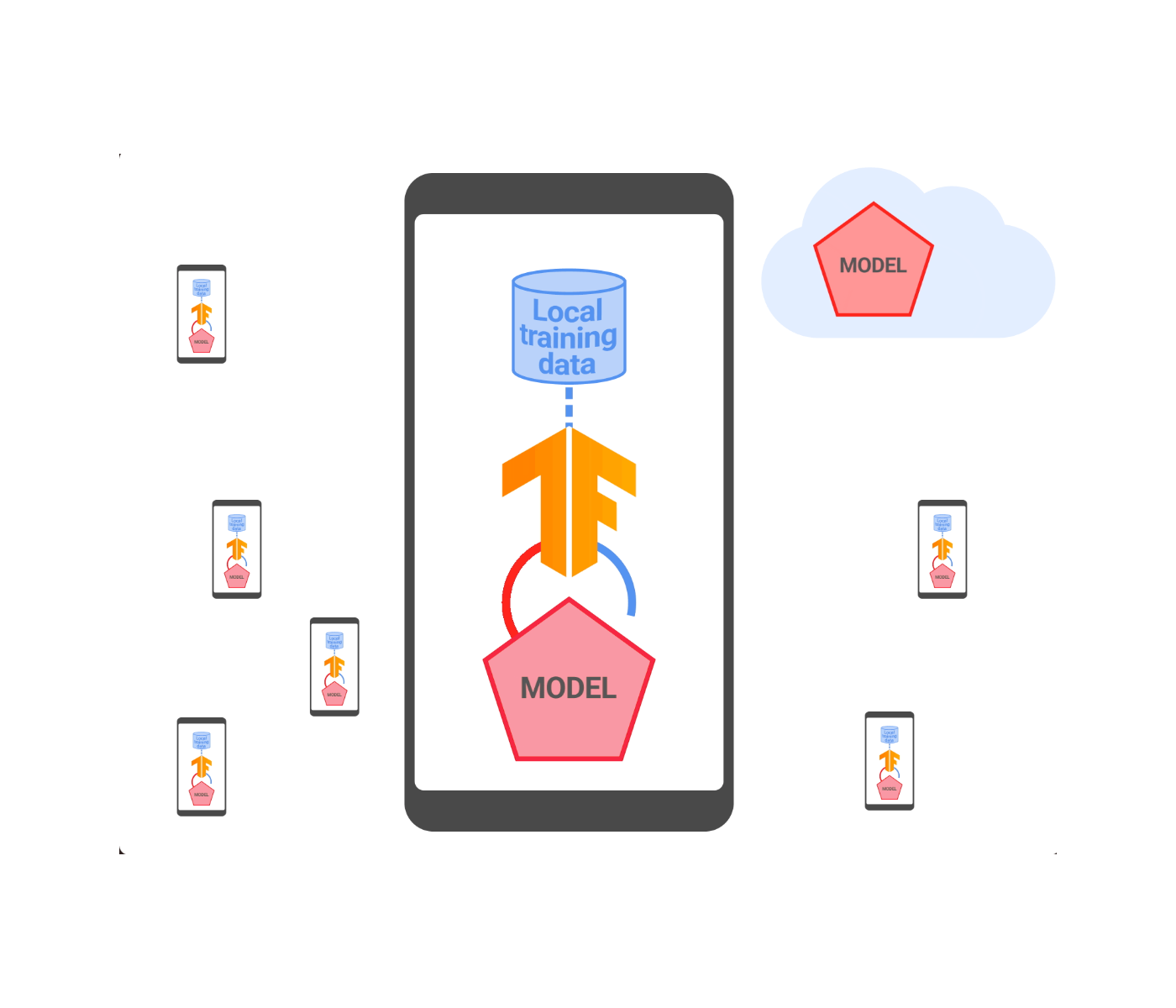
 |
| An overview of federated learning with distributed differential privacy. |
We tested our DDP solution on a variety of benchmark datasets and in production and validated that we can match the accuracy to central DP with a SecAgg finite group of size 12 bits per model parameter. This meant that we were able to achieve added privacy advantages while also reducing memory and communication bandwidth. To demonstrate this, we applied this technology to train and launch Smart Text Selection models. This was done with an appropriate amount of noise chosen to maintain model quality. All Smart Text Selection models trained with federated learning now come with DDP guarantees that apply to both the model updates and metrics seen by the server during training. We have also open sourced the implementation in TensorFlow Federated.
Empirical privacy testing
While DDP adds formal privacy guarantees to Smart Text Selection, those formal guarantees are relatively weak (a finite but large ε, in the hundreds). However, any finite ε is an improvement over a model with no formal privacy guarantee for several reasons: 1) A finite ε moves the model into a regime where further privacy improvements can be quantified; and 2) even large ε’s can indicate a substantial decrease in the ability to reconstruct training data from the trained model. To get a more concrete understanding of the empirical privacy advantages, we performed thorough analyses by applying the Secret Sharer framework to Smart Text Selection models. Secret Sharer is a model auditing technique that can be used to measure the degree to which models unintentionally memorize their training data.
To perform Secret Sharer analyses for Smart Text Selection, we set up control experiments which collect gradients using SecAgg. The treatment experiments use distributed differential privacy aggregators with different amounts of noise.
We found that even low amounts of noise reduce memorization meaningfully, more than doubling the Secret Sharer rank metric for relevant canaries compared to the baseline. This means that even though the DP ε is large, we empirically verified that these amounts of noise already help reduce memorization for this model. However, to further improve on this and to get stronger formal guarantees, we aim to use even larger noise multipliers in the future.
Next steps
We developed and deployed the first federated learning and distributed differential privacy system that comes with formal DP guarantees with respect to an honest-but-curious server. While offering substantial additional protections, a fully malicious server might still be able to get around the DDP guarantees either by manipulating the public key exchange of SecAgg or by injecting a sufficient number of "fake" malicious clients that don’t add the prescribed noise into the aggregation pool. We are excited to address these challenges by continuing to strengthen the DP guarantee and its scope.
Acknowledgements
The authors would like to thank Adria Gascon for significant impact on the blog post itself, as well as the people who helped develop these ideas and bring them to practice: Ken Liu, Jakub Konečný, Brendan McMahan, Naman Agarwal, Thomas Steinke, Christopher Choquette, Adria Gascon, James Bell, Zheng Xu, Asela Gunawardana, Kallista Bonawitz, Mariana Raykova, Stanislav Chiknavaryan, Tancrède Lepoint, Shanshan Wu, Yu Xiao, Zachary Charles, Chunxiang Zheng, Daniel Ramage, Galen Andrew, Hugo Song, Chang Li, Sofia Neata, Ananda Theertha Suresh, Timon Van Overveldt, Zachary Garrett, Wennan Zhu, and Lukas Zilka. We’d also like to thank Tom Small for creating the animated figure.
-
Labels:
- Mobile Systems
Other posts of interest
-

February 21, 2024
Advances in private training for production on-device language models- Mobile Systems ·
- Product ·
- Responsible AI ·
- Security, Privacy and Abuse Prevention
-

January 31, 2024
MobileDiffusion: Rapid text-to-image generation on-device- Machine Intelligence ·
- Machine Perception ·
- Mobile Systems
-

September 15, 2023
MediaPipe FaceStylizer: On-device real-time few-shot face stylization- Machine Perception ·
- Mobile Systems