Applying Advanced Speech Enhancement in Cochlear Implants
July 23, 2021
Posted by Samuel J. Yang, Research Scientist and Dick Lyon, Principal Scientist, Google Research
Quick links
For the ~466 million people in the world who are deaf or hard of hearing, the lack of easy access to accessibility services can be a barrier to participating in spoken conversations encountered daily. While hearing aids can help alleviate this, simply amplifying sound is insufficient for many. One additional option that may be available is the cochlear implant (CI), which is an electronic device that is surgically inserted into a part of the inner ear, called the cochlea, and stimulates the auditory nerve electrically via external sound processors. While many individuals with these cochlear implants can learn to interpret these electrical stimulations as audible speech, the listening experience can be quite varied and particularly challenging in noisy environments.
Modern cochlear implants drive electrodes with pulsatile signals (i.e., discrete stimulation pulses) that are computed by external sound processors. The main challenge still facing the CI field is how to best process sounds — to convert sounds to pulses on electrodes — in a way that makes them more intelligible to users. Recently, to stimulate progress on this problem, scientists in industry and academia organized a CI Hackathon to open the problem up to a wider range of ideas.
In this post, we share exploratory research demonstrating that a speech enhancement preprocessor — specifically, a noise suppressor — can be used at the input of a CI’s processor to enhance users’ understanding of speech in noisy environments. We also discuss how we built on this work in our entry for the CI Hackathon and how we will continue developing this work.
Improving CIs with Noise Suppression
In 2019, a small internal project demonstrated the benefits of noise suppression at the input of a CI’s processor. In this project, participants listened to 60 pre-recorded and pre-processed audio samples and ranked them by their listening comfort. CI users listened to the audio using their devices' existing strategy for generating electrical pulses.
| Audio without background noise | ||
| Audio with background noise | ||
| Audio with background noise + noise suppression | ||
| Background audio clip from “IMG_0991.MOV” by Kenny MacCarthy, license: CC-BY 2.0. |
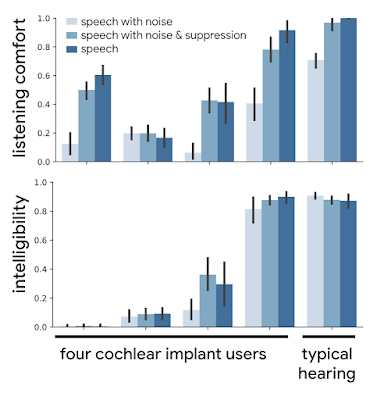
As shown below, both listening comfort and intelligibility usually increased, sometimes dramatically, when speech with noise (the lightest bar) was processed with noise suppression.
 |
| CI users in an early research study have improved listening comfort — qualitatively scored from "very poor" (0.0) to "OK" (0.5) to "very good" (1.0) — and speech intelligibility (i.e., the fraction of words in a sentence correctly transcribed) when trying to listen to noisy audio samples of speech with noise suppression applied. |
For the CI Hackathon, we built on the project above, continuing to leverage our use of a noise suppressor while additionally exploring an approach to compute the pulses too
Overview of the Processing Approach
The hackathon considered a CI with 16 electrodes. Our approach decomposes the audio into 16 overlapping frequency bands, corresponding to the positions of the electrodes in the cochlea. Next, because the dynamic range of sound easily spans multiple orders of magnitude more than what we expect the electrodes to represent, we aggressively compress the dynamic range of the signal by applying "per-channel energy normalization" (PCEN). Finally, the range-compressed signals are used to create the electrodogram (i.e., what the CI displays on the electrodes).
In addition, the hackathon required a submission be evaluated in multiple audio categories, including music, which is an important but notoriously difficult category of sounds for CI users to enjoy. However, the speech enhancement network was trained to suppress non-speech sounds, including both noise and music, so we needed to take extra measures to avoid suppressing instrumental music (note that in general, music suppression might be preferred by some users in certain contexts). To do this, we created a “mix” of the original audio with the noise-suppressed audio so that enough of the music would pass through to remain audible. We varied in real-time the fraction of original audio mixed from 0% to 40% (0% if all of the input is estimated as speech, up to 40% as more of the input is estimated as non-speech) based on the estimate from the open-source YAMNet classifier on every ~1 second window of audio of whether the input is speech or non-speech.
The Conv-TasNet Speech Enhancement Model
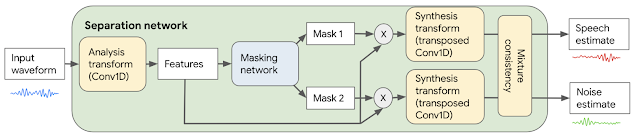
To implement a speech enhancement module that suppresses non-speech sounds, such as noise and music, we use the Conv-TasNet model, which can separate different kinds of sounds. To start, the raw audio waveforms are transformed and processed into a form that can be used by a neural network. The model transforms short, 2.5 millisecond frames of input audio with a learnable analysis transform to generate features optimized for sound separation. The network then produces two “masks” from those features: one mask for speech and one mask for noise. These masks indicate the degree to which each feature corresponds to either speech or noise. Separated speech and noise are reconstructed back to the audio domain by multiplying the masks with the analysis features, applying a synthesis transform back to audio-domain frames, and stitching the resulting short frames together. As a final step, the speech and noise estimates are processed by a mixture consistency layer, which improves the quality of the estimated waveforms by ensuring that they sum up to the original input mixture waveform.
 |
| Block diagram of the speech enhancement system, which is based on Conv-TasNet. |
The model is both causal and low latency: for each 2.5 milliseconds of input audio, the model produces estimates of separated speech and noise, and thus could be used in real-time. For the hackathon, to demonstrate what could be possible with increased compute power in future hardware, we chose to use a model variant with 2.9 million parameters. This model size is too large to be practically implemented in a CI today, but demonstrates what kind of performance would be possible with more capable hardware in the future.
Listening to the Results
As we optimized our models and overall solution, we used the hackathon-provided vocoder (which required a fixed temporal spacing of electrical pulses) to produce audio simulating what CI users might perceive. We then conducted blind A-B listening tests as typical hearing users.
Listening to the vocoder simulations below, the speech in the reconstructed sounds — from the vocoder processing the electrodograms — is reasonably intelligible when the input sound doesn't contain too much background noise, however there is still room to improve the clarity of the speech. Our submission performed well in the speech-in-noise category and achieved second place overall.
| Simulated audio with fixed temporal spacing |
| Vocoder simulation of what CI users might perceive from audio from an electrodogram with fixed temporal spacing, with background noise and noise suppression applied. |
A bottleneck on quality is that the fixed temporal spacing of stimulation pulses sacrifices fine-time structure in the audio. A change to the processing to produce pulses timed to peaks in the filtered sound waveforms captures more information about the pitch and structure of sound than is conventionally represented in implant stimulation patterns.
| Simulated audio with adaptive spacing and fine time structure |
| Vocoder simulation, using the same vocoder as above, but on an electrodogram from the modified processing that synchronizes stimulation pulses to peaks of the sound waveform. |
It's important to note that this second vocoder output is overly optimistic about how well it might sound to a real CI user. For instance, the simple vocoder used here does not model how current spread in the cochlea blurs the stimulus, making it harder to resolve different frequencies. But this at least suggests that preserving fine-time structure is valuable and that the electrodogram itself is not the bottleneck.
Ideally, all processing approaches would be evaluated by a broad range of CI users, with the electrodograms implemented directly on their CIs rather than relying upon vocoder simulations.
Conclusion and a Call to Collaborate
We are planning to follow up on this experience in two main directions. First, we plan to explore the application of noise suppression to other hearing-accessibility modalities, including hearing aids, transcription, and vibrotactile sensory substitution. Second, we'll take a deeper dive into the creation of electrodogram patterns for cochlear implants, exploiting fine temporal structure that is not accommodated in the usual CIS (continous interleaved sampling) patterns that are standard in the industry. According to Louizou: “It remains a puzzle how some single-channel patients can perform so well given the limited spectral information they receive''. Therefore, using fine temporal structure might be a critical step towards achieving an improved CI experience.
Google is committed to building technology with and for people with disabilities. If you are interested in collaborating to improve the state of the art in cochlear implants (or hearing aids), please reach out to ci-collaborators@googlegroups.com.
Acknowledgements
We would like to thank the Cochlear Impact hackathon organizers for giving us this opportunity and partnering with us. The participating team within Google is Samuel J. Yang, Scott Wisdom, Pascal Getreuer, Chet Gnegy, Mihajlo Velimirović, Sagar Savla, and Richard F. Lyon with guidance from Dan Ellis and Manoj Plakal.
Quick links
Other posts of interest
-

July 22, 2026
SymptomAI: Towards a conversational AI agent for everyday symptom assessment- General Science ·
- Health & Bioscience ·
- Natural Language Processing ·
- Responsible AI
-

July 22, 2026
Towards a quantum computer that learns from its errors- Machine Intelligence ·
- Quantum
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence