Adding Sound Effect Information to YouTube Captions
March 23, 2017
Posted by Sourish Chaudhuri, Software Engineer, Sound Understanding
Quick links
The effect of audio on our perception of the world can hardly be overstated. Its importance as a communication medium via speech is obviously the most familiar, but there is also significant information conveyed by ambient sounds. These ambient sounds create context that we instinctively respond to, like getting startled by sudden commotion, the use of music as a narrative element, or how laughter is used as an audience cue in sitcoms.
Since 2009, YouTube has provided automatic caption tracks for videos, focusing heavily on speech transcription in order to make the content hosted more accessible. However, without similar descriptions of the ambient sounds in videos, much of the information and impact of a video is not captured by speech transcription alone. To address this, we announced the addition of sound effect information to the automatic caption track in YouTube videos, enabling greater access to the richness of all the audio content.
In this post, we discuss the backend system developed for this effort, a collaboration among the Accessibility, Sound Understanding and YouTube teams that used machine learning (ML) to enable the first ever automatic sound effect captioning system for YouTube.
| Click the CC button to see the sound effect captioning system in action. |
The application of ML – in this case, a Deep Neural Network (DNN) model – to the captioning task presented unique challenges. While the process of analyzing the time-domain audio signal of a video to detect various ambient sounds is similar to other well known classification problems (such as object detection in images), in a product setting the solution faces additional difficulties. In particular, given an arbitrary segment of audio, we need our models to be able to 1) detect the desired sounds, 2) temporally localize the sound in the segment and 3) effectively integrate it in the caption track, which may have parallel and independent speech recognition results.
A DNN Model for Ambient Sound
The first challenge we faced in developing the model was the task of obtaining enough labeled data suitable for training our neural network. While labeled ambient sound information is difficult to come by, we were able to generate a large enough dataset for training using weakly labeled data. But of all the ambient sounds in a given video, which ones should we train our DNN to detect?
For the initial launch of this feature, we chose [APPLAUSE], [MUSIC] and [LAUGHTER], prioritized based upon our analysis of human-created caption tracks that indicates that they are among the most frequent sounds that are manually captioned. While the sound space is obviously far richer and provides even more contextually relevant information than these three classes, the semantic information conveyed by these sound effects in the caption track is relatively unambiguous, as opposed to sounds like [RING] which raises the question of “what was it that rang – a bell, an alarm, a phone?”
Much of our initial work on detecting these ambient sounds also included developing the infrastructure and analysis frameworks to enable scaling for future work, including both the detection of sound events and their integration into the automatic caption track. Investing in the development of this infrastructure has the added benefit of allowing us to easily incorporate more sound types in the future, as we expand our algorithms to understand a wider vocabulary of sounds (e.g. [RING], [KNOCK], [BARK]). In doing so, we will be able to incorporate the detected sounds into the narrative to provide more relevant information (e.g. [PIANO MUSIC], [RAUCOUS APPLAUSE]) to viewers.
Dense Detections to Captions
When a video is uploaded to YouTube, the sound effect recognition pipeline runs on the audio stream in the video. The DNN looks at short segments of audio and predicts whether that segment contains any one of the sound events of interest – since multiple sound effects can co-occur, our model makes a prediction at each time step for each of the sound effects. The segment window is then slid to the right (i.e. a slightly later point in time) and the model is used to make a prediction again, and so on till it reaches the end. This results in a dense stream the (likelihood of) presence of each of the sound events in our vocabulary at 100 frames per second.
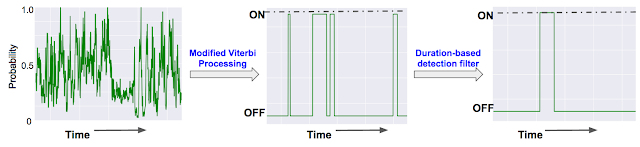
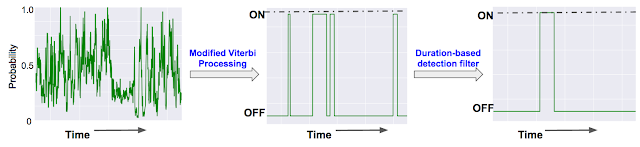
The dense prediction stream is not directly exposed to the user, of course, since that would result in captions flickering on and off, and because we know that a number of sound effects have some degree of temporal continuity when they occur; e.g. “music” and “applause” will usually be present for a few seconds at least. To incorporate this intuition, we smooth over the dense prediction stream using a modified Viterbi algorithm containing two states: ON and OFF, with the predicted segments for each sound effect corresponding to the ON state. The figure below provides an illustration of the process in going from the dense detections to the final segments determined to contain sound effects of interest.
 |
| (Left) The dense sequence of probabilities from our DNN for the occurrence over time of single sound category in a video. (Center) Binarized segments based on the modified Viterbi algorithm. (Right) The duration-based filter removes segments that are shorter in duration than desired for the class. |
A classification-based system such as this one will certainly have some errors, and needs to be able to trade off false positives against missed detections as per the product goals. For example, due to the weak labels in the training dataset, the model was often confused between events that tended to co-occur. For example, a segment labeled “laugh” would usually contain both speech and laughter and the model for “laugh” would have a hard time distinguishing them in test data. In our system, we allow further restrictions based on time spent in the ON state (i.e. do not determine sound X to be detected unless it was determined to be present for at least Y seconds) to push performance toward a desired point in the precision-recall curve.
Once we were satisfied with the performance of our system in temporally localizing sound effect captions based on our offline evaluation metrics, we were faced with the following: how do we combine the sound effect and speech captions to create a single automatic caption track, and how (or when) do we present sound effect information to the user to make it most useful to them?
Adding Sound Effect Information into the Automatic Captions Track
Once we had a system capable of accurately detecting and classifying the ambient sounds in video, we investigated how to convey that information to the viewer in an effective way. In collaboration with our User Experience (UX) research teams, we explored various design options and tested them in a qualitative pilot usability study. The participants of the study had different hearing levels and varying needs for captions. We asked participants a number of questions including whether it improved their overall experience, their ability to follow events in the video and extract relevant information from the caption track, to understand the effect of variables such as:
- Using separate parts of the screen for speech and sound effect captions.
- Interleaving the speech and sound effect captions as they occur.
- Only showing sound effect captions at the end of sentences or when there is a pause in speech (even if they occurred in the middle of speech).
- How hearing users perceive captions when watching with the sound off.
While it wasn’t surprising that almost all users appreciated the added sound effect information when it was accurate, we also paid specific attention to the feedback when the sound detection system made an error (a false positive when determining presence of a sound, or failing to detect an occurrence). This presented a surprising result: when sound effect information was incorrect, it did not detract from the participant’s experience in roughly 50% of the cases. Based upon participant feedback, the reasons for this appear to be:
- Participants who could hear the audio were able to ignore the inaccuracies.
- Participants who could not hear the audio interpreted the error as the presence of a sound event, and that they had not missed out on critical speech information.
Overall, users reported that they would be fine with the system making the occasional mistake as long as it was able to provide good information far more often than not.
Looking Forward
Our work toward enabling automatic sound effect captions for YouTube videos and the initial rollout is a step toward making the richness of content in videos more accessible to our users who experience videos in different ways and in different environments that require captions. We’ve developed a framework to enrich the automatic caption track with sound effects, but there is still much to be done here. We hope that this will spur further work and discussion in the community around improving captions using not only automatic techniques, but also around ways to make creator-generated and community-contributed caption tracks richer (including perhaps, starting with the auto-captions) and better to further improve the viewing experience for our users.
Quick links
Other posts of interest
-

July 30, 2026
Science One Framework: A verifiable autonomous research framework via Chain-of-Evidence- General Science ·
- Machine Intelligence ·
- Natural Language Processing
-

July 22, 2026
Towards a quantum computer that learns from its errors- Machine Intelligence ·
- Quantum
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence