A Structured Approach to Unsupervised Depth Learning from Monocular Videos
November 27, 2018
Posted by Anelia Angelova, Research Scientist, Robotics at Google
Quick links
Perceiving the depth of a scene is an important task for an autonomous robot — the ability to accurately estimate how far from the robot objects are, is crucial for obstacle avoidance, safe planning and navigation. While depth can be obtained (and learned) from sensor data, such as LIDAR, it is also possible to learn it in an unsupervised manner from a monocular camera only, relying on the motion of the robot and the resulting different views of the scene. In doing so, the “ego-motion” (the motion of the robot/camera between two frames) is also learned, which provides localization of the robot itself. While this approach has a long history — coming from the structure-from-motion and multi-view geometry paradigms — new learning based techniques, more specifically for unsupervised learning of depth and ego-motion by using deep neural networks, have advanced the state of the art, including work by Zhou et al., and our own prior research which aligns 3D point clouds of the scene during training.
Despite these efforts, learning to predict scene depth and ego-motion remains an ongoing challenge, specifically when handling highly dynamic scenes and estimating proper depth of moving objects. Because previous research efforts for unsupervised monocular learning do not model moving objects, it can result in consistent misestimation of objects’ depth, often resulting in mapping their depth to infinity.
In “Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular Videos”, to appear in AAAI 2019, we propose a novel approach which is able to model moving objects and produces high quality depth estimation results. Our approach is able to recover the correct depth for moving objects compared to previous methods for unsupervised learning from monocular videos. In our paper, we also propose a seamless online refinement technique that can further improve quality and be applied for transfer across datasets. Furthermore, to encourage even more advanced approaches of onboard robotics learning, we have open sourced the code in TensorFlow.
 |
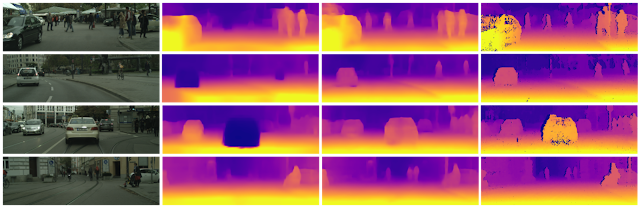
| Previous work (middle row) has not been able to correctly estimate depth of moving objects mapping them to infinity (dark blue regions in the heatmap). Our approach (right) provides much better depth estimates. |
A key idea in our approach is to introduce structure into the learning framework. That is, instead of relying on a neural network to learn depth directly, we treat the monocular scene as 3D, composed of moving objects, including the robot itself. The respective motions are modeled as independent transformations — rotations and translations — in the scene, which is then used to model the 3D geometry and estimate all the objects’ motions. Additionally, knowing which objects may potentially move (e.g., cars, people, bicycles, etc.) helps us learn separate motion vectors for them even if they may be static. By decomposing the scene into 3D and individual objects, better depth and ego-motion in the scene is learned, especially on very dynamic scenes.
We tested this method on both KITTI and Cityscapes urban driving datasets, and found that it outperforms state-of-the-art approaches, and is approaching in quality methods which used stereo pair videos as training supervision. Importantly, we are able to recover correctly the depth of a car moving at the same speed as the ego-motion vehicle. This has been challenging previously — in this case, the moving vehicle appears (in a monocular input) as static, exhibiting the same behavior as the static horizon, resulting in an inferred infinite depth. While stereo inputs can solve that ambiguity, our approach is the first one that is able to correctly infer that from a monocular input.
 |
| Previous work with monocular inputs were not able to extract moving objects and incorrectly map them to infinity. |
 |
| Example depth results for a dynamic scene together with estimates of the motion vectors of the individual objects (rotation angles are estimated too, but for simplicity are not shown). |
 |
| Depth prediction from monocular video input on the KITTI dataset, middle row, compared to ground truth depth from a Lidar sensor; the latter does not cover the full scene and has missing and noisy values. Ground truth depth is not used during training. |
 |
| Depth prediction on the Cityscapes dataset. Left to right: image, baseline, our method and ground truth provided by stereo. Note the missing values in the stereo ground truth. Also note that our algorithm is able to achieve these results without any ground truth depth supervision. |
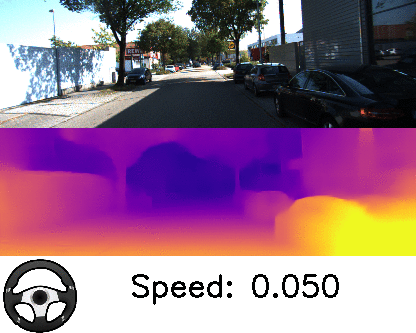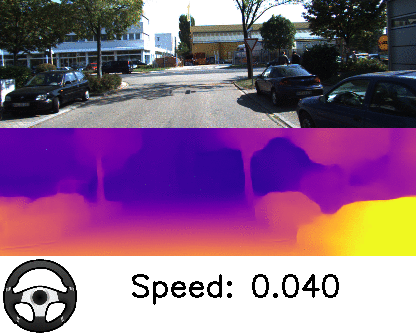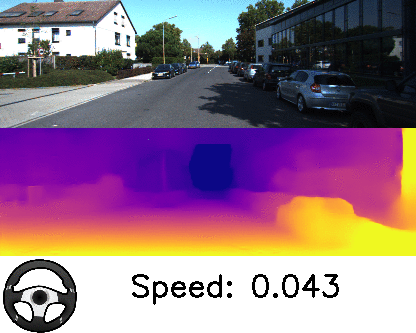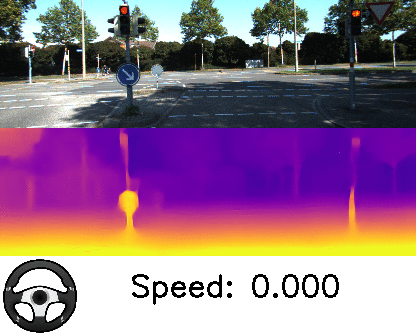
Our results also provide the best among the state-of-the-art estimates in ego-motion, which is crucial for autonomous robots, as it provides localization of the robots while moving in the environment. The video below shows results from our method that visualizes the speed and turning angle, obtained from the inferred ego-motion. While the outputs of both depth and ego-motion are valid up to a scalar, we can see that it is able to estimate its relative speed when slowing down and stopping.
 |
| Depth and ego-motion prediction. Follow the speed and the turning angle indicator to see the estimates when the car is taking a turn or stopping for a red light. |
An important characteristic of a learning algorithm is its adaptability when moved to an unknown environment. In this work we further introduce an online refinement approach which continues to learn online while collecting new data. Below are examples of improvement of the estimated depth quality, after training on Cityscapes and online refinement on KITTI.
 |
| Online refinement when training on the Cityscapes Data and testing on KITTI. The images show depth prediction of the trained model, and of the trained model with online refinement. Depth prediction with online refinement better outlines the objects in the scene. |
 |
| Results of online adaptation when transferring the learning model from Cityscapes (an outdoors dataset collected from a moving car) to a dataset collected indoors by the Fetch robot. The bottom row shows improved depth after applying online refinement. |
Acknowledgements
This research was conducted by Vincent Casser, Soeren Pirk, Reza Mahjourian and Anelia Angelova. We would like to thank Ayzaan Wahid for his help with data collection and Martin Wicke and Vincent Vanhoucke for their support and encouragement.
Quick links
Other posts of interest
-

July 22, 2026
Towards a quantum computer that learns from its errors- Machine Intelligence ·
- Quantum
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

July 9, 2026
SensorFM: Towards a general intelligence and interface for wearable health data- Generative AI ·
- Machine Intelligence
×
❮
❯