
USER-LLM: Efficient LLM contextualization with user embeddings
May 28, 2024
Luyang Liu and Lin Ning, Software Engineers, Google Research
Quick links
Large language models (LLMs) have revolutionized the field of natural language processing (NLP). With their ability to learn and adapt from massive amounts of textual data, LLMs offer significant opportunities to better understand user behavior and to improve personalization services. With consent from users, it's possible to understand how people interact with digital systems (e.g., smart devices, assistive technologies, etc.) and how they can better leverage LLMs for summarization, question answering, and recommendations in ways that are highly relevant and engaging.
The way users interact with digital systems holds valuable insights for better modeling of user behavior. One straightforward approach to leveraging such interaction data is to directly fine-tune LLMs on the textual components, using the interaction history as the text prompt. However, interaction data is often complex, spanning multiple journeys with sparse data points, various interaction types (multimodal), and potential noise or inconsistencies. This complexity can hinder an LLM's ability to identify and focus on the most relevant patterns. Moreover, effective personalization often requires a deep understanding of the context and latent intent behind user actions, which can pose difficulties for LLMs trained predominantly on vast, surface-level language corpora. Additionally, user interaction data, like extended histories, can be very lengthy. Processing and modeling such long sequences (e.g., a year's worth of history) with LLMs can strain computational resources, making it practically infeasible. Addressing these challenges is key to unlocking the full potential of LLMs in user behavior modeling and personalization.
To address the inherent complexities and limitations of leveraging raw user interaction data with LLMs, we introduce “User-LLM: Efficient LLM Contextualization with User Embeddings”. USER-LLM distills compressed representations from diverse and noisy user interactions, effectively capturing the essence of a user's behavioral patterns and preferences across various interaction modalities. By contextualizing the LLM with user embeddings during fine-tuning or inference, we aim to: 1) enhance its ability to identify relevant patterns navigating complexity and noise, 2) facilitate understanding and adaptation to the latent intent, dynamic context, and temporal evolution behind user actions, and 3) mitigate the computational demands of processing extensive interaction histories by working with condensed representations. This approach empowers LLMs with a deeper understanding of users' historical patterns and latent intent, enabling LLMs to tailor responses and generate personalized outcomes.
USER-LLM design
USER-LLM first uses a Transformer-based encoder to create user embeddings from multi-modal ID-based features, where each feature (such as unique restaurant identifiers, restaurant categories, and ratings) has a mapping table with unique embedding representations for each ID. Features are combined into single embeddings and input to the encoder. We use an autoregressive transformer to predict subsequent tokens from previous ones in user activity sequences with multiple modalities. Each token is processed by a decoder and projected back to the original feature space to compute feature specific reconstruction loss.. The output embeddings from the autoregressive transformer provide user context for personalized LLM responses in the next stage.
Secondly, USER-LLM integrates user embeddings with LLMs using cross-attention. The output embeddings from the pretrained user encoder are cross-attended with intermediate text representations within the LLM. Note that our framework remains adaptable to different integration mechanisms including prepending embeddings as soft-prompts. In addition, USER-LLM integrates Perceiver units into its projection layers, which compresses the user embedding to further optimize its inference efficiency.
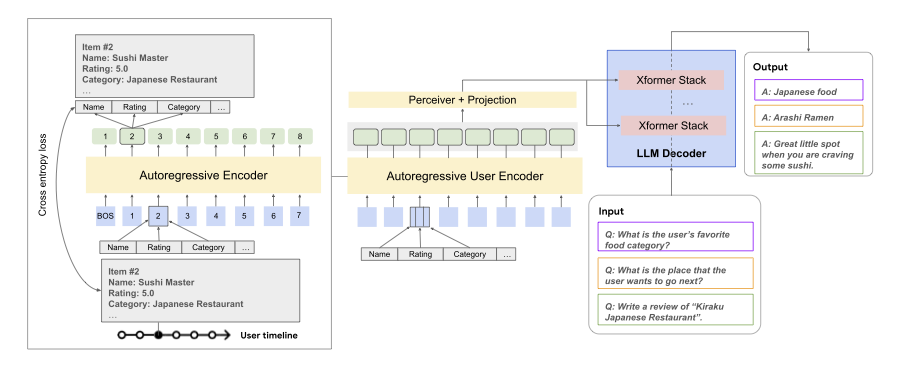
Overview of USER-LLM. Left: Multimodal autoregressive transformer encoder pretraining. Right: LLM contextualization with user embeddings. Features from user interactions are encoded by the autoregressive user encoder and then integrated into the language model via cross-attention.
Performance and efficiency benefits of USER-LLM
We designed a study to examine the performance and efficiency benefits of USER-LLM. The study spans three public datasets (MovieLens20M, Google Local Review, Amazon Review) and various tasks, including next item prediction, favorite category prediction, and next review generation. We meticulously evaluate USER-LLM against state-of-the-art task-specific baselines, demonstrating notable performance improvements in tasks requiring deep understanding of user behavior and long-context inputs. Our approach combines personalization with computational efficiency, surpassing traditional text-prompt–based contextualization. It is important to emphasize that any user data employed for training purposes is utilized exclusively with explicit user consent.
In the next movie prediction task on MovieLens20M, USER-LLM outperforms text-prompt–based LLM fine-tuning for longer sequences. The figure below demonstrates that USER-LLM consistently outperforms the text-prompt baseline across all sequence lengths. Importantly, USER-LLM exhibits enhanced performance as the sequence length increases, contrary to the declining performance observed in the text-prompt baseline. This discrepancy can be attributed to the inherent limitations of LLMs in handling extensive input contexts. As sequences become longer, the increased data diversity and potential noise hinder the effectiveness of text-prompt approaches.
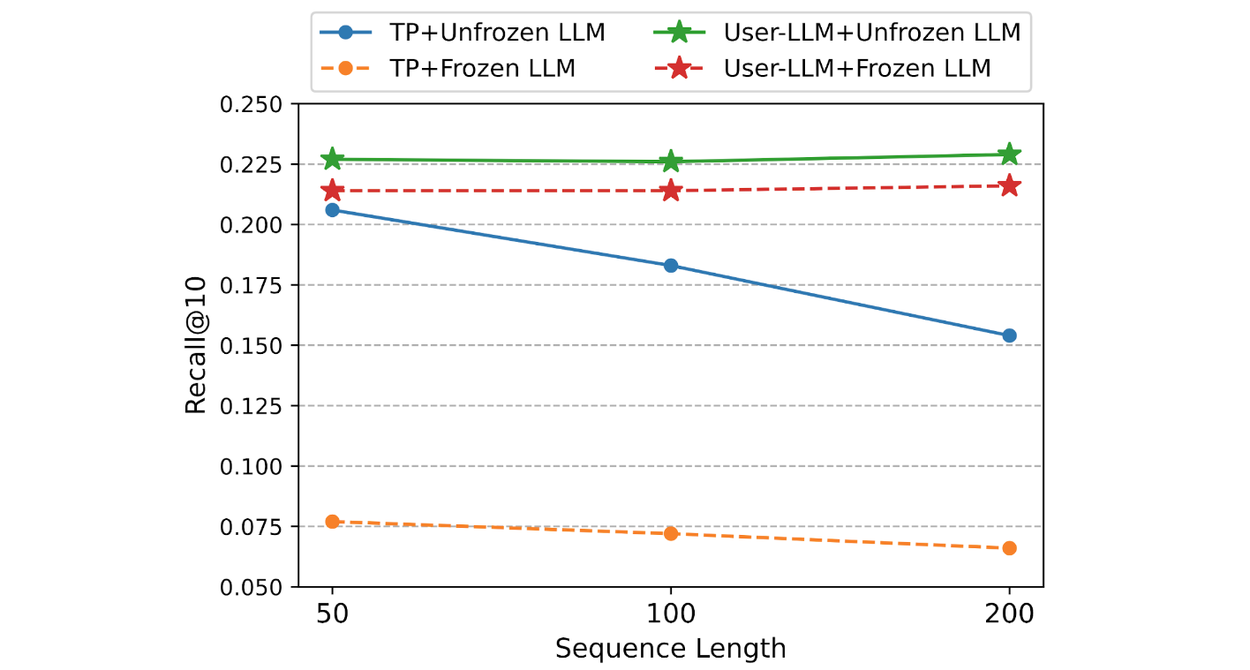
User-LLM consistently outperforms the text-prompt baseline across all sequence lengths.
On the other hand, the computation cost and memory requirements of text-prompt approaches become increasingly prohibitive with increasing input sequence length. The figure below highlights USER-LLM's computational efficiency. The user encoder distills ID-based user activity sequences into compact user embeddings, enabling the LLM to process a fixed-length 32-token input query regardless of input sequence length. Conversely, the text-prompt-based approach requires LLM input token lengths to be scaled proportionally with the input sequence.
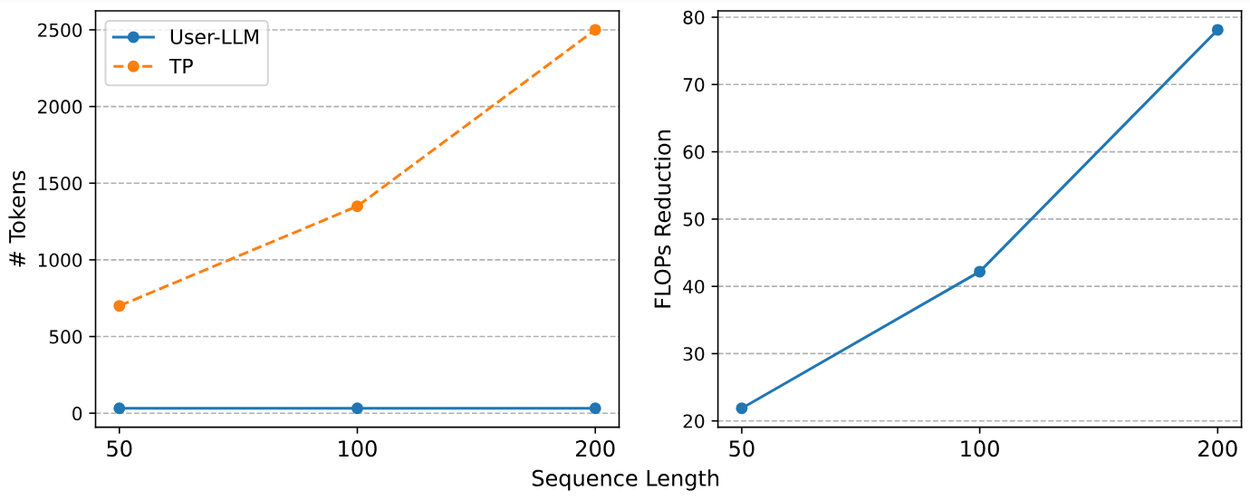
LLM input token counts (left) for USER-LLM vs. Text Prompt (TP) and FLOPs reduction (right) achieved by USER-LLM. FLOPs reduction refers to FLOPsTP / FLOPs-USE-LLM.
When comparing USER-LLM with other baselines that do not use LLMs (e.g., dual encoder and Bert4Rec) for next item prediction tasks, USER-LLM shows the best recall@1 across all datasets. USER-LLM also shows competitive performance on favorite genre/category prediction and review generation tasks, compared with dual encoder and text-prompt based baselines.
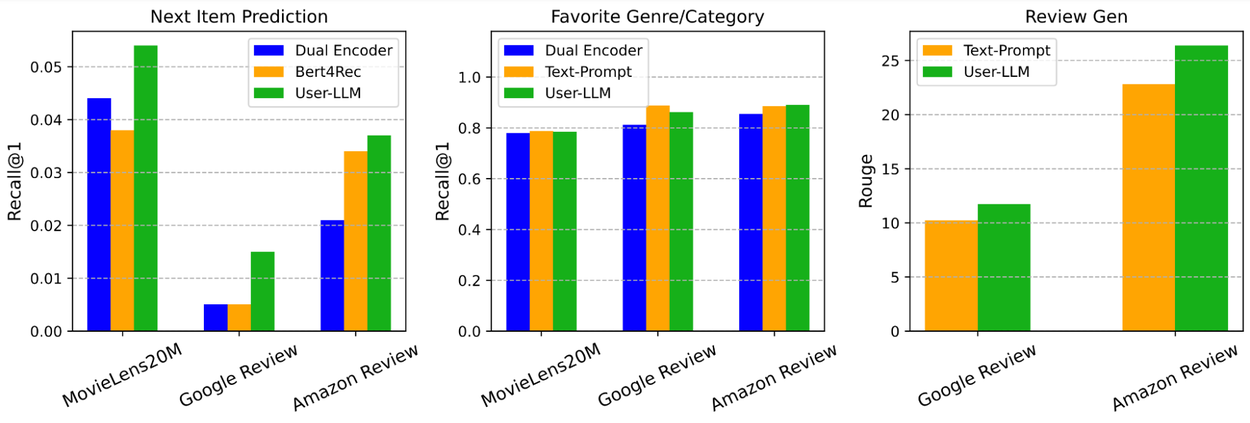
Performance comparison between USER-LLM and baselines (Bert4Rec, Dual Encoder, and Text Prompt) on next item prediction, favorite genre/category prediction, and review generation tasks.
Conclusion
This study introduces USER-LLM, a novel framework that leverages user embeddings to contextualize LLMs. Through self-supervised pre-training, these embeddings capture user preferences and their evolution. By seamlessly integrating them with language models, USER-LLM empowers LLMs to adapt dynamically to a variety of user contexts. Extensive evaluation across multiple datasets showcases significant performance enhancements, particularly in tasks requiring deep user understanding and long sequence modeling. Notably, USER-LLM maintains computational efficiency and preserves LLM knowledge, making it an ideal solution for practical user modeling applications. Future exploration in optimizing user embeddings, aligning them with LLM space, and training on diverse tasks holds the potential to further enhance USER-LLM's robustness and versatility, solidifying its position as a powerful framework for user modeling and LLM personalization.
Acknowledgments
This research was conducted by Lin Ning, Luyang Liu, Jiaxing Wu, Neo Wu, Devora Berlowitz, Sushant Prakash, Bradley Green, Shawn O'Banion, and Jun Xie. Thanks to Matt Barnes, Tim Strother, CJ Park, and Xiang Zhai for building the initial infrastructure and helping with baselines. Philip Mansfield and Rif A. Saurous for reviewing the paper. Ewa Dominowska and Jay Yagnik for their support on this project.
Quick links
Other posts of interest
-

July 22, 2026
Towards a quantum computer that learns from its errors- Machine Intelligence ·
- Quantum
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

July 9, 2026
SensorFM: Towards a general intelligence and interface for wearable health data- Generative AI ·
- Machine Intelligence

User-LLM consistently outperforms the text-prompt baseline across all sequence lengths.

Overview of USER-LLM. Left: Multimodal autoregressive transformer encoder pretraining. Right: LLM contextualization with user embeddings. Features from user interactions are encoded by the autoregressive user encoder and then integrated into the language model via cross-attention.

Performance comparison between USER-LLM and baselines (Bert4Rec, Dual Encoder, and Text Prompt) on next item prediction, favorite genre/category prediction, and review generation tasks.

LLM input token counts (left) for USER-LLM vs. Text Prompt (TP) and FLOPs reduction (right) achieved by USER-LLM. FLOPs reduction refers to FLOPsTP / FLOPs-USE-LLM.