Unlocking 7B+ language models in your browser: A deep dive with Google AI Edge's MediaPipe
August 22, 2024
Tyler Mullen, Software Engineer, Google Core ML
Learn how we redesigned model-loading code for the web in order to overcome several memory restrictions and enable running larger (7B+) LLMs in the browser using our cross-platform inference framework.
Quick links
Large language models (LLMs) are incredible tools that enable new ways for humans to interact with computers and devices. These models are frequently run on specialized server farms, with requests and responses ferried over an internet connection. Running models fully on-device is an appealing alternative, as this can eliminate server costs, ensure a higher degree of user privacy, and even allow for offline usage. However, doing so is a true stress test for machine learning infrastructure: even “small” LLMs usually have billions of parameters and sizes measured in the gigabytes (GB), which can easily overload memory and compute capabilities.
Earlier this year, Google AI Edge’s MediaPipe (a framework for efficient on-device pipelines) launched a new experimental cross-platform LLM inference API that can utilize device GPUs to run small LLMs across Android, iOS, and web with maximal performance. At launch, it was capable of running four openly available LLMs fully on-device: Gemma, Phi 2, Falcon, and Stable LM. These models range in size from 1 to 3 billion parameters.
At the time, these were also the largest models our system was capable of running in the browser. To achieve such broad platform reach, our system first targeted mobile devices. We then upgraded it to run in the browser, preserving speed but also gaining complexity in the process, due to the upgrade’s additional limitations on usage and memory. Loading larger models would have overrun several of these new memory limits (discussed more below). In addition, our mitigation options were limited substantially by two key system requirements: (1) a single library that could adapt to many models and (2) the ability to consume the single-file .tflite format used across many of our products.
Today, we are eager to share an update to our web API. This includes a web-specific redesign of our model loading system to address these challenges, which enables us to run much larger models like Gemma 1.1 7B. Comprising 7 billion parameters, this 8.6GB file is several times larger than any model we’ve run in a browser previously, and the quality improvement in its responses is correspondingly significant — try it out for yourself in MediaPipe Studio!
Video of a conversation between a user and Gemma 1.1 7B running in the browser. The user asks for birthday card message ideas, eliciting several templates in response. Follow-up details are offered, which the model then incorporates.
Running LLMs on the web
Google AI Edge’s MediaPipe is fundamentally cross-platform, so most of our code is written in C++, which can be nicely compiled for many target platforms and architectures. To run this in the browser, we compile our entire codebase (everything non-web-specific, including dependencies) into WebAssembly, a special assembly code that can be efficiently run in all major browsers. This gives us great performance and scalability, but also imposes a few extra restrictions, because the browser runs WebAssembly in a sandboxed virtual machine (i.e., emulating a separate physical computer).
One noteworthy detail is that while WebAssembly affects our C++ code and our CPU memory limits, it does not limit our GPU capabilities. That’s because we use the WebGPU API for all our GPU-related tasks, which was designed to run natively in browsers, giving us more direct access to the GPU and its compute capabilities than ever before. For peak performance, our machine learning inference engine uploads the model weights and runs the model operations entirely on the GPU.
Overcoming memory limitations
In contrast, when loading an LLM from hard disk or network, the raw data must travel through several layers to reach the GPU:
- File reading memory
- JavaScript memory
- WebAssembly memory
- WebGPU device memory
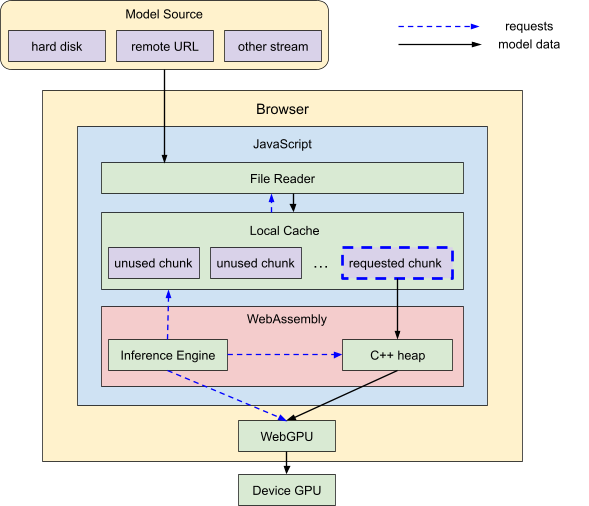
Specifically, we use a browser-based file reading API to bring the raw data into JavaScript, pass it to our C++ WebAssembly memory, and finally upload it to WebGPU, where everything will be run. Each of these layers has memory limits we need to consider (discussed below), so we design our system architecture to accommodate.
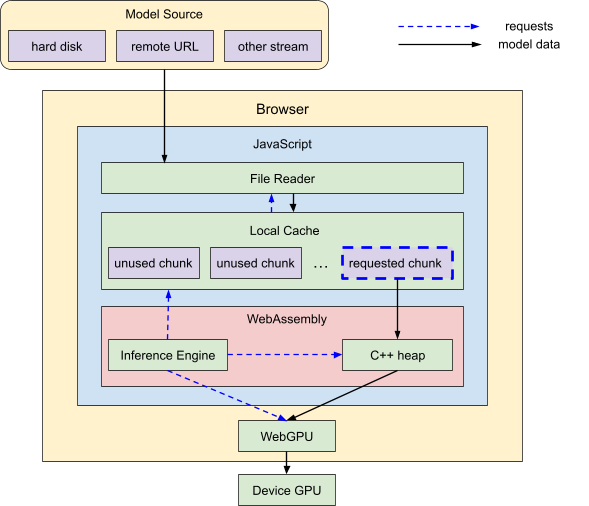
Loading system architecture. The WebAssembly inference engine directs chunks of model data to be moved from a local cache to C++ memory and then to the GPU. As needed, the local cache requests additional model data from a JavaScript file reader, which is streaming this data from the model source.
WebGPU device memory
WebGPU device limits are hardware-specific, but thankfully most modern laptops and desktops have plenty of GPU memory for our purposes. So we focused on removing the other three memory limitations — all CPU — to leave this as the only true restriction.
File reading memory
Our earlier MediaPipe web APIs make heavy use of JavaScript primitives like ArrayBuffer when we load data, but many of these cannot support sizes past ~2GB. For the initial web LLM launch, we worked around the 2GB limitation by creating custom data copying routines that rely on more flexible objects like ReadableStreamDefaultReader. Now for our latest update, we built upon this earlier work in order to break up our massive file into smaller chunks, which are streamed on demand when we copy them into working memory.
WebAssembly memory
The main technical challenge we faced is that WebAssembly currently uses 32-bit integers (from 0 to 232-1) to index addresses in its memory space, which would overflow the indexing scheme if we used more than 232 bytes (≅ 4.3GB). In fact, even getting access to that much memory required some workarounds.
Fortunately, the structure of LLMs can be leveraged to our advantage. LLMs involve lots of pieces, but the majority of the binary size rests in the transformer stack. This is a tall pile of similarly-shaped models, which are run in consecutive layers, one after the next.
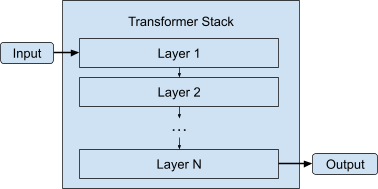
Transformer stack. The input enters the stack as an input to layer 1, whose output is given to layer 2 as input. This process continues until the output from the final layer leaves the stack.
Gemma 1.1 7B has 28 such layers, which means that if we are able to load our layers one at a time into WebAssembly memory, we should have a 28-fold memory usage improvement for this step. Therefore, we changed our synchronous loading pipeline to an asynchronous one, where the C++ code calls out to JavaScript to request and wait for each weight buffer it needs, in turn.
In practice, the results for Gemma 1.1 7B loading were even better than expected: the layers themselves contain many weight buffers, none of which are very large, so by loading individual weight buffers on demand, our peak WebAssembly memory usage for transformer stack loading is now less than 1% of what it would have been!
JavaScript memory
There is one major downside, however, to these upgrades: we now parse the massive model file in a single extended scan over the course of our loading process, which does not let us “jump” to particular spots in the file on demand (often colloquially referred to as random access). This means that the order in which we load pieces is now important. If we ask for a buffer from the end of the file, we can’t then request one from the beginning.
The clear solution is to have the model weights stored in the same order that the loading code requests them. But the only way to fully guarantee this would be to either make ordering part of the model format, or else to empower our internal loading code to dynamically reshuffle itself to match the model ordering. These are both longer-term solutions, so for now, we need a backup plan so we can handle arbitrary model weight orderings.
Scanning over the file multiple times would be prohibitively slow, and we know we never need to load the same data twice, so instead we create a temporary local cache. As we scan over the data, we break it into small chunks, keeping those that haven’t been used yet and discarding the rest. This approach degrades gracefully: if the model’s ordering is ideal, nothing is cached, and only if the ordering is precisely “backward” will we need to temporarily cache the entire file. The latter case should never happen in practice, but even if it did, our solution would still work for 7B-parameter–sized models because our local cache is kept in JavaScript memory, for which most browsers provide a rather generous per-tab limit (about 16GB in Chrome).
What’s next
In our quest to remove CPU-side memory-related friction, another solution for using less memory is just to make smaller models. This is often done by applying more aggressive quantization strategies, which means keeping the same number of weights but compressing those weights into fewer bits. For our earlier Gemma 1.1 2B model, we released an “int4” version which manages to retain quality while being only half the size of the original “int8” version. We hope to soon repeat this feat for Gemma 1.1 7B as well.
In addition to relieving memory pressures and expanding model coverage, we’re always optimizing performance and adding exciting new features, like dynamic LoRA support for fine-tuning and customizing on-the-fly. In particular, multimodal support and cancellation are two popular feature requests we’d love to deliver. We’re working hard to include Gemma 2 as well — stay tuned for more updates!
Acknowledgements
We’d like to thank everyone who contributed to this breakthrough: Clark Duvall, Lin Chen, Sebastian Schmidt, Pulkit Bhuwalka, Mark Sherwood, Mig Gerard, Zichuan Wei, Linkun Chen, Yu-hui Chen, Juhyun Lee, Ho Ko, Kristen Wright, Sachin Kotwani, Cormac Brick, Lu Wang, Chuo-Ling Chang, Ram Iyengar, and Matthias Grundmann.
Quick links
Other posts of interest
-

April 8, 2026
Improving the academic workflow: Introducing two AI agents for better figures and peer review- Generative AI ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
