The neural networks behind Google Voice transcription
August 11, 2015
Posted by Françoise Beaufays, Research Scientist
Quick links
Over the past several years, deep learning has shown remarkable success on some of the world’s most difficult computer science challenges, from image classification and captioning to translation to model visualization techniques. Recently we announced improvements to Google Voice transcription using Long Short-term Memory Recurrent Neural Networks (LSTM RNNs)—yet another place neural networks are improving useful services. We thought we’d give a little more detail on how we did this.
Since it launched in 2009, Google Voice transcription had used Gaussian Mixture Model (GMM) acoustic models, the state of the art in speech recognition for 30+ years. Sophisticated techniques like adapting the models to the speaker's voice augmented this relatively simple modeling method.
Then around 2012, Deep Neural Networks (DNNs) revolutionized the field of speech recognition. These multi-layer networks distinguish sounds better than GMMs by using “discriminative training,” differentiating phonetic units instead of modeling each one independently.
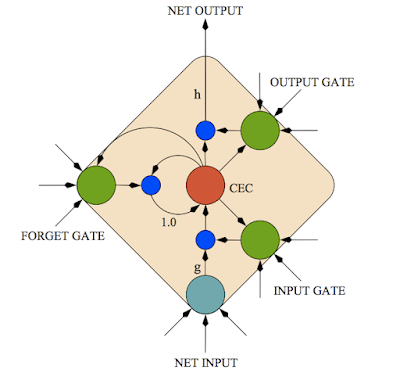
But things really improved rapidly with Recurrent Neural Networks (RNNs), and especially LSTM RNNs, first launched in Android’s speech recognizer in May 2012. Compared to DNNs, LSTM RNNs have additional recurrent connections and memory cells that allow them to “remember” the data they’ve seen so far—much as you interpret the words you hear based on previous words in a sentence.
By then, Google’s old voicemail system, still using GMMs, was far behind the new state of the art. So we decided to rebuild it from scratch, taking advantage of the successes demonstrated by LSTM RNNs. But there were some challenges.
 |
| An LSTM memory cell, showing the gating mechanisms that allow it to store and communicate information. Image credit: Jürgen Schmidhuber |
We decided to retrain both the acoustic and language models, and to do so using existing voicemails. We already had a small set of voicemails users had donated for research purposes and that we could transcribe for training and testing, but we needed much more data to retrain the language models. So we asked our users to donate their voicemails in bulk, with the assurance that the messages wouldn’t be looked at or listened to by anyone—only to be used by computers running machine learning algorithms. But how does one train models from data that’s never been human-validated or hand-transcribed?
We couldn’t just use our old transcriptions, because they were already tainted with recognition errors—garbage in, garbage out. Instead, we developed a delicate iterative pipeline to retrain the models. Using improved acoustic models, we could recognize existing voicemails offline to get newer, better transcriptions the language models could be retrained on, and with better language models we could recognize again the same data, and repeat the process. Step by step, the recognition error rate dropped, finally settling at roughly half what it was with the original system! That was an excellent surprise.
There were other (not so positive) surprises too. For example, sometimes the recognizer would skip entire audio segments; it felt as if it was falling asleep and waking up a few seconds later. It turned out that the acoustic model would occasionally get into a “bad state” where it would think the user was not speaking anymore and what it heard was just noise, so it stopped outputting words. When we retrained on that same data, we’d think all those spoken sounds should indeed be ignored, reinforcing that the model should do it even more. It took careful tuning to get the recognizer out of that state of mind.
It was also tough to get punctuation right. The old system relied on hand-crafted rules or “grammars,” which, by design, can’t easily take textual context into account. For example, in an early test our algorithms transcribed the audio “I got the message you left me” as “I got the message. You left me.” To try and tackle this, we again tapped into neural networks, teaching an LSTM to insert punctuation at the right spots. It’s still not perfect, but we’re continually working on ways to improve our accuracy.
In speech recognition as in many other complex services, neural networks are rapidly replacing previous technologies. There’s always room for improvement of course, and we’re already working on new types of networks that show even more promise!
Quick links
Other posts of interest
-

July 30, 2026
Science One Framework: A verifiable autonomous research framework via Chain-of-Evidence- General Science ·
- Machine Intelligence ·
- Natural Language Processing
-

July 22, 2026
Towards a quantum computer that learns from its errors- Machine Intelligence ·
- Quantum
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
×
❮
❯
