The Machine Learning Behind Android Smart Linkify
August 9, 2018
Posted by Lukas Zilka, Software Engineer, Google AI, Zürich
Quick links
Earlier this week we launched Android 9 Pie, the latest release of Android that uses machine learning to make your phone simpler to use. One of the features in Android 9 is Smart Linkify, a new API that adds clickable links when certain types of entities are detected in text. This is useful when, for example, you receive an address from a friend in a messaging app and want to look it up on a map. With a Smart Linkify-annotated text, it’s a lot easier!

Smart Linkify is available as an open-source TextClassifier API in Android (as the generateLinks method). The models were trained using TensorFlow and exported to a custom inference library backed by TensorFlow Lite and FlatBuffers. The C++ inference library for the models is available as part of Android Open-Source framework here, and runs on each text selection and Smart Linkify API calls.
Finding Entities
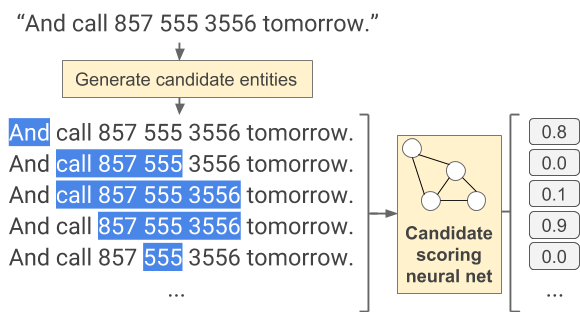
Looking for phone numbers and postal addresses in text is a difficult problem. Not only are there many variations in how people write them, but it’s also often ambiguous what type of entity is being represented (e.g. “Confirmation number: 857-555-3556” is not a phone number even though it it takes a similar form to one). As a solution, we designed an inference algorithm with two small feedforward neural networks at its heart. This algorithm is general enough to perform all kinds of entity chunking beyond just addresses and phone numbers.
Overall, the system architecture is as follows: A given input text is first split into words (based on space separation), then all possible word subsequences of certain maximum length (15 words in our case) are generated, and for each candidate the scoring neural net assigns a value (between 0 and 1) based on whether it represents a valid entity:
 |
| For the given text string, the first network assigns low scores to non-entities and a high score for the candidate that correctly selects the whole phone number. |
In our example, the only non-conflicting entities are “And call 857 555 3556tomorrow.” (with “857 555 3556” classified as a phone number), and “And call 857 555 3556 tomorrow.” (with “And” classified as a non-entity).

Now that we have the only non-conflicting entities, “And call 857 555 3556 tomorrow.” (with “857 555 3556” classified as a phone number) and “And call 857 555 3556 tomorrow.” (with “And” classified as a non-entity), we are easily able to underline them in the displayed text on the screen, and run the right app when clicked.
Textual Features
So far, we’ve given a general description of the way Smart Linkify locates and classifies entities in a string of text. Here, we go into more detail on how the text is processed and fed to the network.
The task of the networks, given an entity candidate in the input text, is to determine whether the entity is valid, and then to classify it. To do this, the networks need to know the context surrounding the entity (in addition to the text string of the entity itself). In machine learning this is done by representing these parts as separate features. Effectively, the input text is split into several parts that are fed to the network separately:
 |
| Given a candidate entity span, we extract: Left context: five words before the entity, Entity start: first three words of the entity, Entity end: last three words of the entity (they can be duplicated with the previous feature if they overlap, or padded if there are not that many), Right context: five words after the entity, Entity content: bag of words inside the entity and Entity length: size of the entity in number of words. They are then concatenated together and fed as an input to the neural network. |
- Character N-grams. Instead of using the standard word embedding technique for representing words, which keeps a separate vector for each word in the model and thus would be infeasible for mobile devices because of their large storage size, we use the hashed charactergram embedding. This technique represents the word as a set of all character subsequences of certain length. We use lengths 1 to 5. These strings are additionally hashed and mapped to a fixed number of buckets (see here for more details on the technique). As a result, the final model only stores vectors for each of the hash buckets, not each word/character subsequence, and can be kept small. The embedding matrix for the hashed charactergrams that we use has 20,000 buckets and 12 dimensions.
- A binary feature that indicates whether the word starts with a capital letter. This is important for the network to know because the capitalization in postal addresses is quite distinct, and helps the networks to discriminate.
There is no obvious dataset for this task on which we could readily train the networks, so we came up with a training algorithm that generates synthetic examples out of realistic pieces. Concretely, we gathered lists of addresses, phone numbers and named entities (like product, place and business names) and other random words from the Web (using Schema.org annotations), and use them to synthesize the training data for the neural networks. We take the entities as they are and generate random textual contexts around them (from the list of random words on Web). Additionally, we add phrases like “Confirmation number:” or “ID:” to the negative training data for phone numbers, to teach the network to suppress phone number matches in these contexts.
Making it Work
There are a number of additional techniques that we had to use for training the network and making a practical mobile deployment:
- Quantizing the embedding matrix to 8 bits. We found that we could reduce the size of the model almost 4x without compromising the performance, by quantizing the embedding matrix values to 8-bit integers.
- Sharing embedding matrices between the selection and classification networks. This brings almost no loss and makes the model 2x smaller.
- Varying the size of the context before/after the entities. On mobile screens text is often short, with not enough context, so the network needs to be exposed to this during training as well.
- Creating artificial negative examples out of the positive ones for the classification network. For example for the positive example: “call me 857 555-3556 today” with a label “phone” we generate “call me 857 555-3556 today” as a negative example with a label “other”. This teaches the classification network to be more precise about the entity span. Without doing this, the network would be merely a detector whether there is a phone number somewhere in the input, regardless of the span.
The automatic data extraction we use makes it easier to train language-specific models. However, making them work for all languages is a challenge, requiring careful checking of language nuance by experts, as well as having an acceptable amount of training data. We found that having one model for all Latin-script languages works well (e.g. Czech, Polish, German, English), with individual models for each of Chinese, Japanese, Korean, Thai, Arabic and Russian. While Smark Linkify currently supports 16 languages, we are experimenting with models that support even more languages, which is especially challenging given the mobile model size constraints and trickiness with languages that do not split words on spaces.
Next Steps
While the technique described in this post enables the fast and accurate annotation of phone numbers and postal addresses in text, the recognition of flight numbers, date and time, or IBAN, is currently implemented with a more traditional technique using standard regular expressions. However, we are looking into creating ML models for date and time as well, particularly for recognizing informal relative date/time specifications prevalent in messaging context, like “next Thursday” or “in 3 weeks”.
The small model and binary size as well as low latency are very important for mobile deployment. The models and the code we developed are available open-source as part of Android framework. We believe that the architecture could extend to other on-device text annotation problems and we look forward to seeing new use cases from our developer community!
Quick links
Other posts of interest
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

July 9, 2026
SensorFM: Towards a general intelligence and interface for wearable health data- Generative AI ·
- Machine Intelligence
-

June 30, 2026
Introducing TabFM: A zero-shot foundation model for tabular data- Data Management ·
- Machine Intelligence ·
- Product
×
❮
❯