Retrieval-augmented visual-language pre-training
June 1, 2023
Posted by Ziniu Hu, Student Researcher, and Alireza Fathi, Research Scientist, Google Research, Perception Team
Quick links
Large-scale models, such as T5, GPT-3, PaLM, Flamingo and PaLI, have demonstrated the ability to store substantial amounts of knowledge when scaled to tens of billions of parameters and trained on large text and image datasets. These models achieve state-of-the-art results on downstream tasks, such as image captioning, visual question answering and open vocabulary recognition. Despite such achievements, these models require a massive volume of data for training and end up with a tremendous number of parameters (billions in many cases), resulting in significant computational requirements. Moreover, the data used to train these models can become outdated, requiring re-training every time the world's knowledge is updated. For example, a model trained just two years ago might yield outdated information about the current president of the United States.
In the fields of natural language processing (RETRO, REALM) and computer vision (KAT), researchers have attempted to address these challenges using retrieval-augmented models. Typically, these models use a backbone that is able to process a single modality at a time, e.g., only text or only images, to encode and retrieve information from a knowledge corpus. However, these retrieval-augmented models are unable to leverage all available modalities in a query and knowledge corpora, and may not find the information that is most helpful for generating the model’s output.
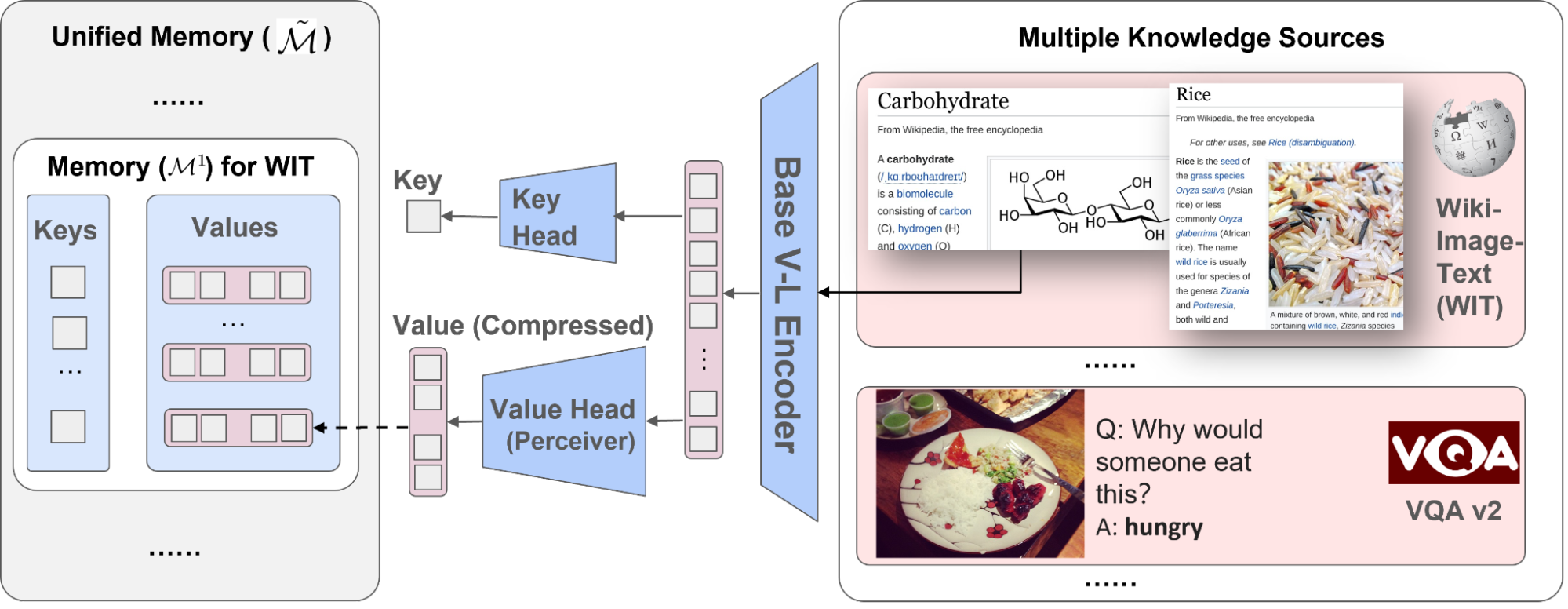
To address these issues, in “REVEAL: Retrieval-Augmented Visual-Language Pre-Training with Multi-Source Multimodal Knowledge Memory”, to appear at CVPR 2023, we introduce a visual-language model that learns to utilize a multi-source multi-modal “memory” to answer knowledge-intensive queries. REVEAL employs neural representation learning to encode and convert diverse knowledge sources into a memory structure consisting of key-value pairs. The keys serve as indices for the memory items, while the corresponding values store pertinent information about those items. During training, REVEAL learns the key embeddings, value tokens, and the ability to retrieve information from this memory to address knowledge-intensive queries. This approach allows the model parameters to focus on reasoning about the query, rather than being dedicated to memorization.
 |
| We augment a visual-language model with the ability to retrieve multiple knowledge entries from a diverse set of knowledge sources, which helps generation. |
Memory construction from multimodal knowledge corpora
Our approach is similar to REALM in that we precompute key and value embeddings of knowledge items from different sources and index them in a unified knowledge memory, where each knowledge item is encoded into a key-value pair. Each key is a d-dimensional embedding vector, while each value is a sequence of token embeddings representing the knowledge item in more detail. In contrast to previous work, REVEAL leverages a diverse set of multimodal knowledge corpora, including the WikiData knowledge graph, Wikipedia passages and images, web image-text pairs and visual question answering data. Each knowledge item could be text, an image, a combination of both (e.g., pages in Wikipedia) or a relationship or attribute from a knowledge graph (e.g., Barack Obama is 6’ 2” tall). During training, we continuously re-compute the memory key and value embeddings as the model parameters get updated. We update the memory asynchronously at every thousand training steps.
Scaling memory using compression
A naïve solution for encoding a memory value is to keep the whole sequence of tokens for each knowledge item. Then, the model could fuse the input query and the top-k retrieved memory values by concatenating all their tokens together and feeding them into a transformer encoder-decoder pipeline. This approach has two issues: (1) storing hundreds of millions of knowledge items in memory is impractical if each memory value consists of hundreds of tokens and (2) the transformer encoder has a quadratic complexity with respect to the total number of tokens times k for self-attention. Therefore, we propose to use the Perceiver architecture to encode and compress knowledge items. The Perceiver model uses a transformer decoder to compress the full token sequence into an arbitrary length. This lets us retrieve top-k memory entries for k as large as a hundred.
The following figure illustrates the procedure of constructing the memory key-value pairs. Each knowledge item is processed through a multi-modal visual-language encoder, resulting in a sequence of image and text tokens. The key head then transforms these tokens into a compact embedding vector. The value head (perceiver) condenses these tokens into fewer ones, retaining the pertinent information about the knowledge item within them.
 |
| We encode the knowledge entries from different corpora into unified key and value embedding pairs, where the keys are used to index the memory and values contain information about the entries. |
Large-scale pre-training on image-text pairs
To train the REVEAL model, we begin with the large-scale corpus, collected from the public Web with three billion image alt-text caption pairs, introduced in LiT. Since the dataset is noisy, we add a filter to remove data points with captions shorter than 50 characters, which yields roughly 1.3 billion image caption pairs. We then take these pairs, combined with the text generation objective used in SimVLM, to train REVEAL. Given an image-text example, we randomly sample a prefix containing the first few tokens of the text. We feed the text prefix and image to the model as input with the objective of generating the rest of the text as output. The training goal is to condition the prefix and autoregressively generate the remaining text sequence.
To train all components of the REVEAL model end-to-end, we need to warm start the model to a good state (setting initial values to model parameters). Otherwise, if we were to start with random weights (cold-start), the retriever would often return irrelevant memory items that would never generate useful training signals. To avoid this cold-start problem, we construct an initial retrieval dataset with pseudo–ground-truth knowledge to give the pre-training a reasonable head start.
We create a modified version of the WIT dataset for this purpose. Each image-caption pair in WIT also comes with a corresponding Wikipedia passage (words surrounding the text). We put together the surrounding passage with the query image and use it as the pseudo ground-truth knowledge that corresponds to the input query. The passage provides rich information about the image and caption, which is useful for initializing the model.
To prevent the model from relying on low-level image features for retrieval, we apply random data augmentation to the input query image. Given this modified dataset that contains pseudo-retrieval ground-truth, we train the query and memory key embeddings to warm start the model.
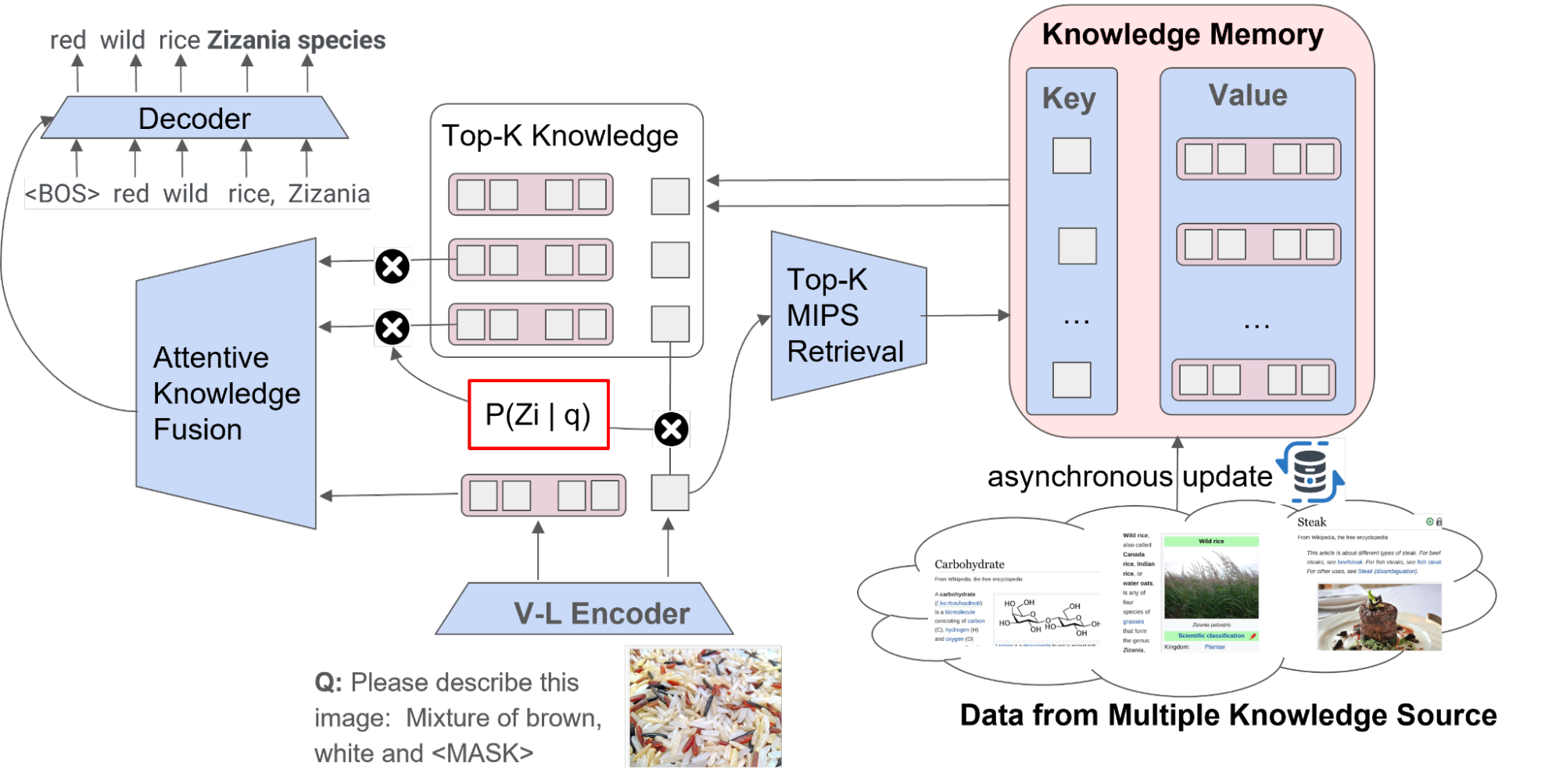
REVEAL workflow
The overall workflow of REVEAL consists of four primary steps. First, REVEAL encodes a multimodal input into a sequence of token embeddings along with a condensed query embedding. Then, the model translates each multi-source knowledge entry into unified pairs of key and value embeddings, with the key being utilized for memory indexing and the value encompassing the entire information about the entry. Next, REVEAL retrieves the top-k most related knowledge pieces from multiple knowledge sources, returns the pre-processed value embeddings stored in memory, and re-encodes the values. Finally, REVEAL fuses the top-k knowledge pieces through an attentive knowledge fusion layer by injecting the retrieval score (dot product between query and key embeddings) as a prior during attention calculation. This structure is instrumental in enabling the memory, encoder, retriever and the generator to be concurrently trained in an end-to-end fashion.
 |
| Overall workflow of REVEAL. |
Results
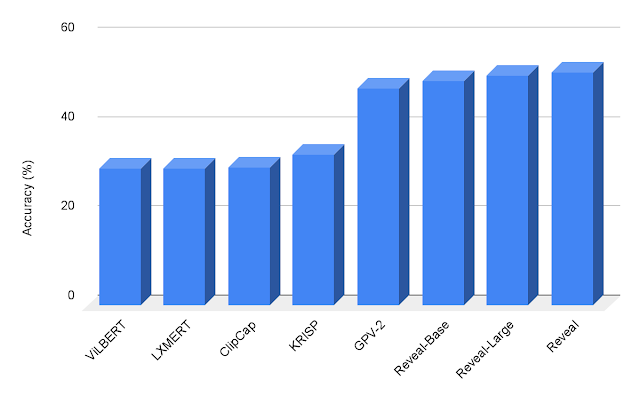
We evaluate REVEAL on knowledge-based visual question answering tasks using OK-VQA and A-OKVQA datasets. We fine-tune our pre-trained model on the VQA tasks using the same generative objective where the model takes in an image-question pair as input and generates the text answer as output. We demonstrate that REVEAL achieves better results on the A-OKVQA dataset than earlier attempts that incorporate a fixed knowledge or the works that utilize large language models (e.g., GPT-3) as an implicit source of knowledge.
 |
| Visual question answering results on A-OKVQA. REVEAL achieves higher accuracy in comparison to previous works including ViLBERT, LXMERT, ClipCap, KRISP and GPV-2. |
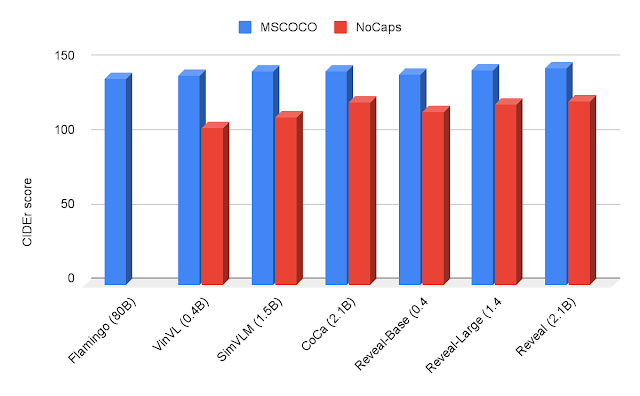
We also evaluate REVEAL on the image captioning benchmarks using MSCOCO and NoCaps dataset. We directly fine-tune REVEAL on the MSCOCO training split via the cross-entropy generative objective. We measure our performance on the MSCOCO test split and NoCaps evaluation set using the CIDEr metric, which is based on the idea that good captions should be similar to reference captions in terms of word choice, grammar, meaning, and content. Our results on MSCOCO caption and NoCaps datasets are shown below.
 |
| Image Captioning results on MSCOCO and NoCaps using the CIDEr metric. REVEAL achieves a higher score in comparison to Flamingo, VinVL, SimVLM and CoCa. |
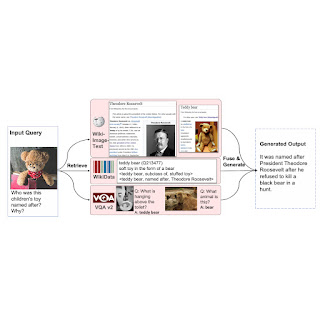
Below we show a couple of qualitative examples of how REVEAL retrieves relevant documents to answer visual questions.
 |
| REVEAL can use knowledge from different sources to correctly answer the question. |
Conclusion
We present an end-to-end retrieval-augmented visual language (REVEAL) model, which contains a knowledge retriever that learns to utilize a diverse set of knowledge sources with different modalities. We train REVEAL on a massive image-text corpus with four diverse knowledge corpora, and achieve state-of-the-art results on knowledge-intensive visual question answering and image caption tasks. In the future we would like to explore the ability of this model for attribution, and apply it to a broader class of multimodal tasks.
Acknowledgements
This research was conducted by Ziniu Hu, Ahmet Iscen, Chen Sun, Zirui Wang, Kai-Wei Chang, Yizhou Sun, Cordelia Schmid, David A. Ross and Alireza Fathi.
Quick links
Other posts of interest
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

July 9, 2026
SensorFM: Towards a general intelligence and interface for wearable health data- Generative AI ·
- Machine Intelligence
-

June 30, 2026
Introducing TabFM: A zero-shot foundation model for tabular data- Data Management ·
- Machine Intelligence ·
- Product