Quantization for Fast and Environmentally Sustainable Reinforcement Learning
September 27, 2022
Posted by Srivatsan Krishnan, Student Researcher, and Aleksandra Faust, Senior Staff Research Scientist, Google Research, Brain Team
Quick links
Deep reinforcement learning (RL) continues to make great strides in solving real-world sequential decision-making problems such as balloon navigation, nuclear physics, robotics, and games. Despite its promise, one of its limiting factors is long training times. While the current approach to speed up RL training on complex and difficult tasks leverages distributed training scaling up to hundreds or even thousands of computing nodes, it still requires the use of significant hardware resources which makes RL training expensive, while increasing its environmental impact. However, recent work [1, 2] indicates that performance optimizations on existing hardware can reduce the carbon footprint (i.e., total greenhouse gas emissions) of training and inference.
RL can also benefit from similar system optimization techniques that can reduce training time, improve hardware utilization and reduce carbon dioxide (CO2) emissions. One such technique is quantization, a process that converts full-precision floating point (FP32) numbers to lower precision (int8) numbers and then performs computation using the lower precision numbers. Quantization can save memory storage cost and bandwidth for faster and more energy-efficient computation. Quantization has been successfully applied to supervised learning to enable edge deployments of machine learning (ML) models and achieve faster training. However, there remains an opportunity to apply quantization to RL training.
To that end, we present “QuaRL: Quantization for Fast and Environmentally Sustainable Reinforcement Learning”, published in the Transactions of Machine Learning Research journal, which introduces a new paradigm called ActorQ that applies quantization to speed up RL training by 1.5-5.4x while maintaining performance. Additionally, we demonstrate that compared to training in full-precision, the carbon footprint is also significantly reduced by a factor of 1.9-3.8x.
Applying Quantization to RL Training
In traditional RL training, a learner policy is applied to an actor, which uses the policy to explore the environment and collect data samples. The samples collected by the actor are then used by the learner to continuously refine the initial policy. Periodically, the policy trained on the learner side is used to update the actor's policy. To apply quantization to RL training, we develop the ActorQ paradigm. ActorQ performs the same sequence described above, with one key difference being that the policy update from learner to actors is quantized, and the actor explores the environment using the int8 quantized policy to collect samples.
Applying quantization to RL training in this fashion has two key benefits. First, it reduces the memory footprint of the policy. For the same peak bandwidth, less data is transferred between learners and actors, which reduces the communication cost for policy updates from learners to actors. Second, the actors perform inference on the quantized policy to generate actions for a given environment state. The quantized inference process is much faster when compared to performing inference in full precision.
 |
| An overview of traditional RL training (left) and ActorQ RL training (right). |
In ActorQ, we use the ACME distributed RL framework. The quantizer block performs uniform quantization that converts the FP32 policy to int8. The actor performs inference using optimized int8 computations. Though we use uniform quantization when designing the quantizer block, we believe that other quantization techniques can replace uniform quantization and produce similar results. The samples collected by the actors are used by the learner to train a neural network policy. Periodically the learned policy is quantized by the quantizer block and broadcasted to the actors.
Quantization Improves RL Training Time and Performance
We evaluate ActorQ in a range of environments, including the Deepmind Control Suite and the OpenAI Gym. We demonstrate the speed-up and improved performance of D4PG and DQN. We chose D4PG as it was the best learning algorithm in ACME for Deepmind Control Suite tasks, and DQN is a widely used and standard RL algorithm.
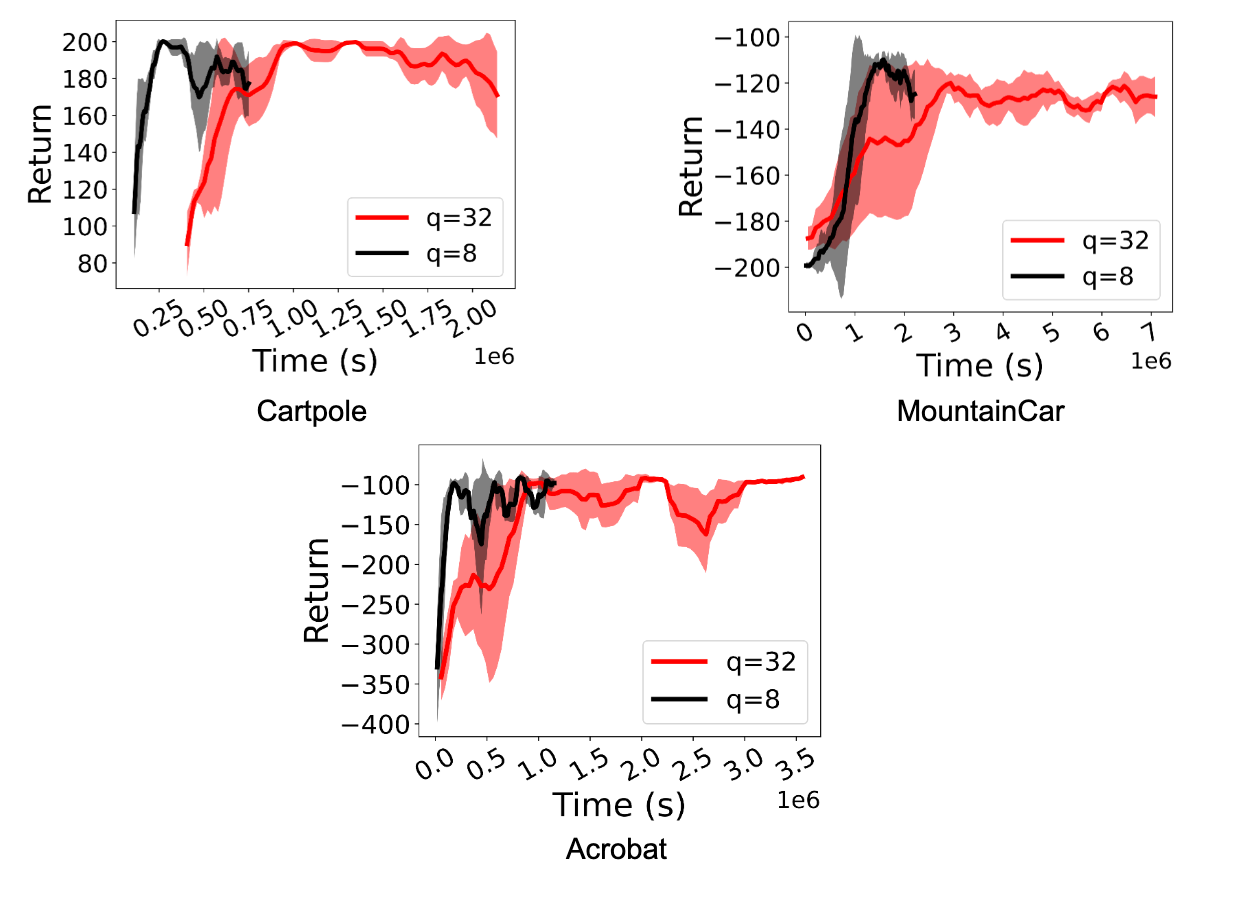
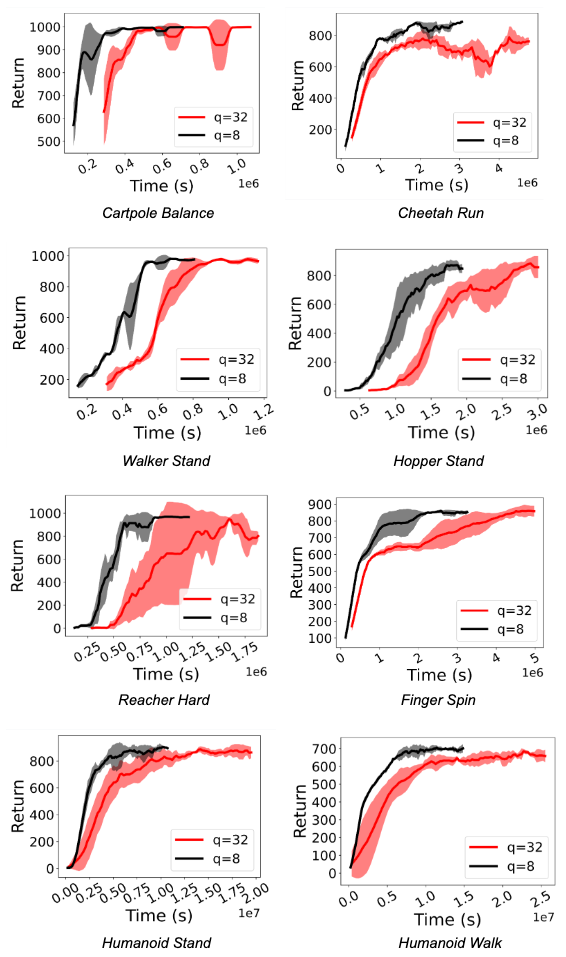
We observe a significant speedup (between 1.5x and 5.41x) in training RL policies. More importantly, performance is maintained even when actors perform int8 quantized inference. The figures below demonstrate this for the D4PG and DQN agents for Deepmind Control Suite and OpenAI Gym tasks.
 |
| A comparison of RL training using the FP32 policy (q=32) and the quantized int8 policy (q=8) for D4PG agents on various Deepmind Control Suite tasks. Quantization achieves speed-ups of 1.5x to 3.06x. |
 |
| A comparison of RL training using the FP32 policy (q=32) and the quantized int8 policy (q=8) for DQN agents in the OpenAI Gym environment. Quantization achieves a speed-up of 2.2x to 5.41x. |
Quantization Reduces Carbon Emission
Applying quantization in RL using ActorQ improves training time without affecting performance. The direct consequence of using the hardware more efficiently is a smaller carbon footprint. We measure the carbon footprint improvement by taking the ratio of carbon emission when using the FP32 policy during training over the carbon emission when using the int8 policy during training.
In order to measure the carbon emission for the RL training experiment, we use the experiment-impact-tracker proposed in prior work. We instrument the ActorQ system with carbon monitor APIs to measure the energy and carbon emissions for each training experiment.
Compared to the carbon emission when running in full precision (FP32), we observe that the quantization of policies reduces the carbon emissions anywhere from 1.9x to 3.76x, depending on the task. As RL systems are scaled to run on thousands of distributed hardware cores and accelerators, we believe that the absolute carbon reduction (measured in kilograms of CO2) can be quite significant.
 |
| Carbon emission comparison between training using a FP32 policy and an int8 policy. The X-axis scale is normalized to the carbon emissions of the FP32 policy. Shown by the red bars greater than 1, ActorQ reduces carbon emissions. |
Conclusion and Future Directions
We introduce ActorQ, a novel paradigm that applies quantization to RL training and achieves speed-up improvements of 1.5-5.4x while maintaining performance. Additionally, we demonstrate that ActorQ can reduce RL training’s carbon footprint by a factor of 1.9-3.8x compared to training in full-precision without quantization.
ActorQ demonstrates that quantization can be effectively applied to many aspects of RL, from obtaining high-quality and efficient quantized policies to reducing training times and carbon emissions. As RL continues to make great strides in solving real-world problems, we believe that making RL training sustainable will be critical for adoption. As we scale RL training to thousands of cores and GPUs, even a 50% improvement (as we have experimentally demonstrated) will generate significant savings in absolute dollar cost, energy, and carbon emissions. Our work is the first step toward applying quantization to RL training to achieve efficient and environmentally sustainable training.
While our design of the quantizer in ActorQ relied on simple uniform quantization, we believe that other forms of quantization, compression and sparsity can be applied (e.g., distillation, sparsification, etc.). We hope that future work will consider applying more aggressive quantization and compression methods, which may yield additional benefits to the performance and accuracy tradeoff obtained by the trained RL policies.
Acknowledgments
We would like to thank our co-authors Max Lam, Sharad Chitlangia, Zishen Wan, and Vijay Janapa Reddi (Harvard University), and Gabriel Barth-Maron (DeepMind), for their contribution to this work. We also thank the Google Cloud team for providing research credits to seed this work.
Quick links