
Preprocessing for Machine Learning with tf.Transform
February 22, 2017
Posted by Kester Tong, David Soergel, and Gus Katsiapis, Software Engineers
Quick links
When applying machine learning to real world datasets, a lot of effort is required to preprocess data into a format suitable for standard machine learning models, such as neural networks. This preprocessing takes a variety of forms, from converting between formats, to tokenizing and stemming text and forming vocabularies, to performing a variety of numerical operations such as normalization.
Today we are announcing tf.Transform, a library for TensorFlow that allows users to define preprocessing pipelines and run these using large scale data processing frameworks, while also exporting the pipeline in a way that can be run as part of a TensorFlow graph. Users define a pipeline by composing modular Python functions, which tf.Transform then executes with Apache Beam, a framework for large-scale, efficient, distributed data processing. Apache Beam pipelines can be run on Google Cloud Dataflow with planned support for running with other frameworks. The TensorFlow graph exported by tf.Transform enables the preprocessing steps to be replicated when the trained model is used to make predictions, such as when serving the model with Tensorflow Serving.
A common problem encountered when running machine learning models in production is "training-serving skew", where the data seen at serving time differs in some way from the data used to train the model, leading to reduced prediction quality. tf.Transform ensures that no skew can arise during preprocessing, by guaranteeing that the serving-time transformations are exactly the same as those performed at training time, in contrast to when training-time and serving-time preprocessing are implemented separately in two different environments (e.g., Apache Beam and TensorFlow, respectively).
In addition to facilitating preprocessing, tf.Transform allows users to compute summary statistics for their datasets. Understanding the data is very important in every machine learning project, as subtle errors can arise from making wrong assumptions about what the underlying data look like. By making the computation of summary statistics easy and efficient, tf.Transform allows users to check their assumptions about both raw and preprocessed data.
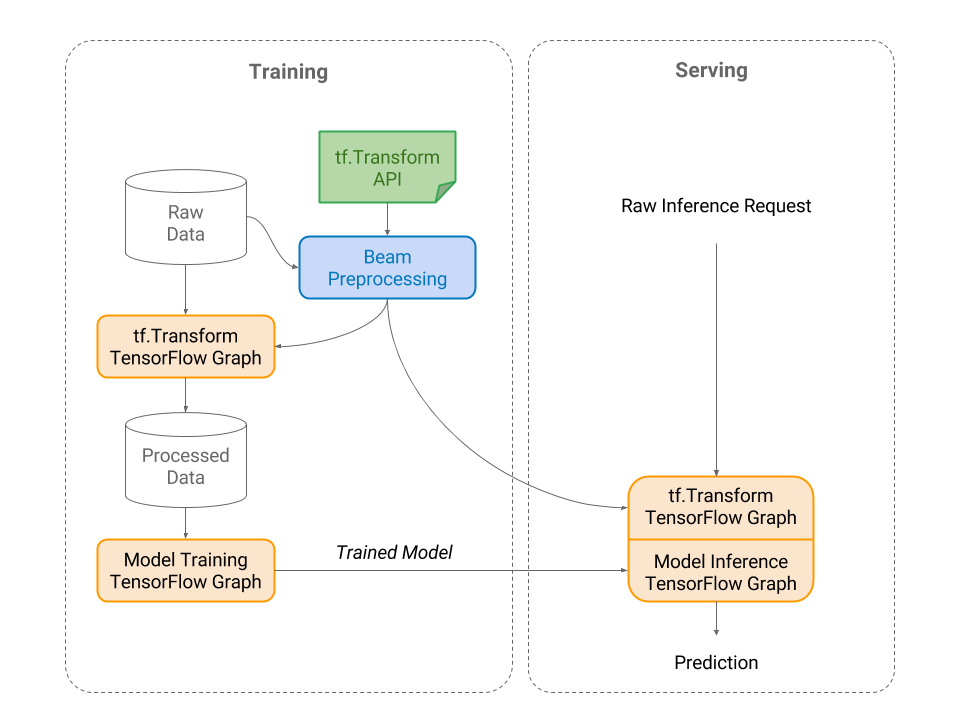 |
| tf.Transform allows users to define a preprocessing pipeline. Users can materialize the preprocessed data for use in TensorFlow training, and also export a tf.Transform graph that encodes the transformations as a TensorFlow graph. This transformation graph can then be incorporated into the model graph used for inference. |
Acknowledgements
We wish to thank the following members of the tf.Transform team for their contributions to this project: Clemens Mewald, Robert Bradshaw, Rajiv Bharadwaja, Elmer Garduno, Afshin Rostamizadeh, Neoklis Polyzotis, Abhi Rao, Joe Toth, Neda Mirian, Dinesh Kulkarni, Robbie Haertel, Cyril Bortolato and Slaven Bilac. We also wish to thank the TensorFlow, TensorFlow Serving and Cloud Dataflow teams for their support.
Quick links
Other posts of interest
-

July 9, 2026
SensorFM: Towards a general intelligence and interface for wearable health data- Generative AI ·
- Machine Intelligence
-

June 30, 2026
Introducing TabFM: A zero-shot foundation model for tabular data- Data Management ·
- Machine Intelligence ·
- Product
-

June 26, 2026
Accelerating Gemini Nano models on Pixel with frozen Multi-Token Prediction- Machine Intelligence ·
- Mobile Systems ·
- Natural Language Processing
×
❮
❯
