Off-Policy Estimation for Infinite-Horizon Reinforcement Learning
April 17, 2020
Posted by Ali Mousavi, AI Resident and Lihong Li, Research Scientist, Google Research
Quick links
In conventional reinforcement learning (RL) settings, an agent interacts with an environment in an online fashion, meaning that it collects data from its interaction with the environment that is then used to inform changes to the policy governing its behavior. In contrast, offline RL refers to the setting where historical data are used to either learn good policies for acting in an environment, or to evaluate the performance of new policies. As RL is increasingly applied to crucial real-life problems like robotics and recommendation systems, evaluating new policies in the offline setting — estimating the expected reward of a target policy given historical data generated from actions that are based on a behavior policy — becomes more critical. However, despite its importance, evaluating the overall effectiveness of a target policy based on historical behavior policies can be a bit tricky, due to the difficulty in building high-fidelity simulators and also the mismatch in data distributions.
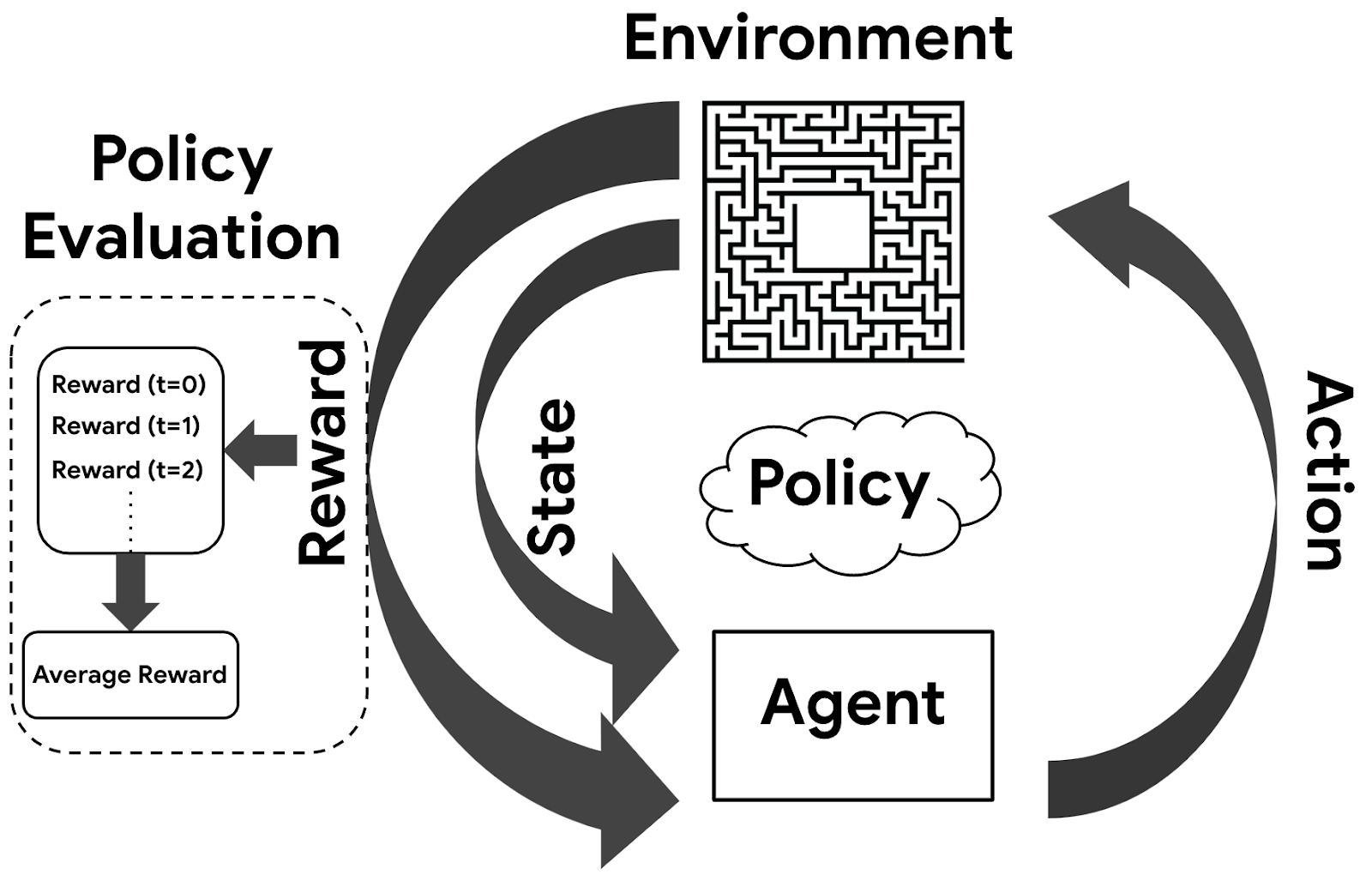 |
| Agent-environment interaction in reinforcement learning. At each step, an agent takes an action based on a policy, receives a reward and makes a transition to a new state. |
 |
| In off-policy evaluation, unlike the behavior policy, we do not have any data from the target policy. Therefore, we cannot compute the expected reward of the target policy without using information from the behavior policy. |
Background
In general, one approach to solve the off-policy evaluation problem is to build a simulator that mimics the interaction of the agent with the environment, and then evaluate the target policy against the simulation. While the idea is natural, building a high-fidelity simulator for many domains can be extremely challenging, particularly those that involve human interactions.
An alternative approach is to use the weighted average of rewards from the off-policy data as an estimate of the average reward of the target policy. This approach can be more robust than using a simulator as it does not require modeling assumptions about real world dynamics. Indeed, most previous efforts using this approach have found success on short-horizon problems where the number of time steps (i.e., the length of data trajectory) is limited. However, as the horizon is extended, the variance in predictions made by most of the previous estimators often grows exponentially, necessitating novel solutions for long-horizon problems, and even more so in the extreme case of the infinite-horizon problem.
Our Approach for Infinite-Horizon RL
Our method of OPE leverages a well-known statistical technique called importance sampling through which one can estimate the properties of a particular distribution (e.g., the mean) from samples generated by another distribution. In particular, we estimate the long-term average reward of the target policy using the weighted average of rewards from the behavior policy data. The difficulty in this approach is how to choose the weights in order to remove the bias between the off-policy data distribution and that of the target policy while achieving the best estimate of the target policy’s average reward.
One important point is that if the weights are normalized to be positive and sum up to one, then they define a probability distribution over the set of possible states and actions of the agent. On the other hand, an individual policy defines a distribution on how often an agent visits a particular state or performs a particular action. In other words, it defines a unique distribution on states and actions. Under reasonable assumptions, this distribution does not change over time, and is called a stationary distribution. Since we are using importance sampling, we naturally want to optimize weights of the estimator such that the stationary distribution of the target policy matches the distribution induced by the weights of our estimator. However, the problem remains that we do not know the stationary distribution of the target policy, since we do not have any data generated by that policy.
One way to overcome this problem is to make sure that the distribution of weights satisfies properties that the target policy distribution has, without actually knowing what this distribution is. Luckily, we can take advantage of some mathematical "trickery" to solve this. While the full details are found in our paper, the upshot is that while we do not know the stationary distribution of the target policy (since we have no data collected from it) we can determine that distribution by solving an optimization problem involving a backward operator, which describes how an agent transitions from other states and actions to a particular state and action using probability distributions as both input and output. Once we are done, the weighted average of rewards from historic data gives us an estimate of the expected reward of the target policy.
Experimental Results
Using a toy environment called ModelWin that has three states and two actions, we compare our work with a previous state-of-the-art approach (labeled “IPS”), along with a naive method in which we simply average rewards from the behavior policy data. The figure below shows the log of the root-mean-square error (RMSE) with respect to the target policy reward as we change the number of steps collected by the behavior policy. The naive method suffers from a large bias and its error does not change even with more data collected by increasing the length of the episode. The estimation error of the IPS method decreases with increasing horizon length. On the other hand, the error exhibited by our method is small, even for short horizon length.
 |
| Left: The ModelWin environment with three states (s1-s3) and two actions (a1, a2). Right: RMSE of different approaches on the ModelWin problem in logarithmic scale. Our approach has converged very quickly in this simple problem, compared to the previous state-of-the-art method (IPS) that needs longer horizon length to converge. |
 |  |
 |  |
 |  |
| Comparison of different methods on three environments: Cartpole, Pendulum, and Mountaincar. The left column shows the environments. The right column shows the log of the RMSE with respect to the target policy reward as the number of trajectories collected by the behavior policy changes. The results are based on 50 runs. |
Acknowledgements.
Special thanks to Qiang Liu and Denny Zhou for contributing to this project.
Quick links
×
❮
❯








