LANISTR: Multimodal learning from structured and unstructured data
May 22, 2024
Sayna Ebrahimi, Research Scientist, and Yihe Dong, Software Engineer, Cloud AI Team
Quick links
Recent multimodal learning breakthroughs have predominantly focused on unstructured data, spanning vision, language, video, and audio modalities (Flamingo, PaLI, CLIP, VATT, etc.). However, learning joint representations with structured data, including tabular or time-series formats, remains relatively underexplored, despite structured data being the prevalent data type in the real world. Real-world scenarios often demand the integration of structured and unstructured data, for example, in healthcare diagnostics or retail demand forecasting. This highlights the need to learn two seemingly disparate data types together in a multimodal fashion, using a unified architecture and unique pretraining strategies that align structured and unstructured modalities.
Unlocking the potential benefits of multimodal learning with structured and unstructured data requires addressing two challenges that become increasingly prominent as the number of modalities, input size, and data heterogeneity increase. First, as the input feature dimensionality and heterogeneity increase, deep neural networks can become susceptible to overfitting and suboptimal generalization, particularly when trained on datasets of limited scale. This challenge is exacerbated when using unstructured and structured data together, such as time series data that often exhibit non-stationary behavior (fashion trends, sensory measurements, etc.), which, unlike other more independent and identically distributed (i.i.d.) modalities, makes it difficult to build well-generalisable models. Similarly, tabular data often include numerous columns (features) containing minimal information, leading to overfitting to spurious correlations. Second, problems caused by the absence of some modalities become more pronounced in multimodal data with more than two modalities (e.g., image+text+tabular+time series), where each sample may not include some modalities. To the best of our knowledge, a systematic study addressing these challenges in learning from unstructured and structured data remains absent from current literature.
To address these challenges, in “LANISTR: Multimodal Learning from Structured and Unstructured Data”, we introduce a novel framework to learn from LANguage, Image, and STRuctured data. LANISTR enables multimodal learning by ingesting unstructured (image, text) and structured (time series, tabular) data, performing alignment and fusion, and ultimately generating predictions. Using two publicly available healthcare and retail datasets, LANISTR demonstrates remarkable improvements when fine-tuned with 0.1% and 0.01% of labeled data, respectively. Notably, these improvements are observed even with a very high ratio of samples (35.7% and 99.8%, respectively) that don’t contain all modalities, underlining the robustness of LANISTR to practical missing modality challenges.
Model architecture
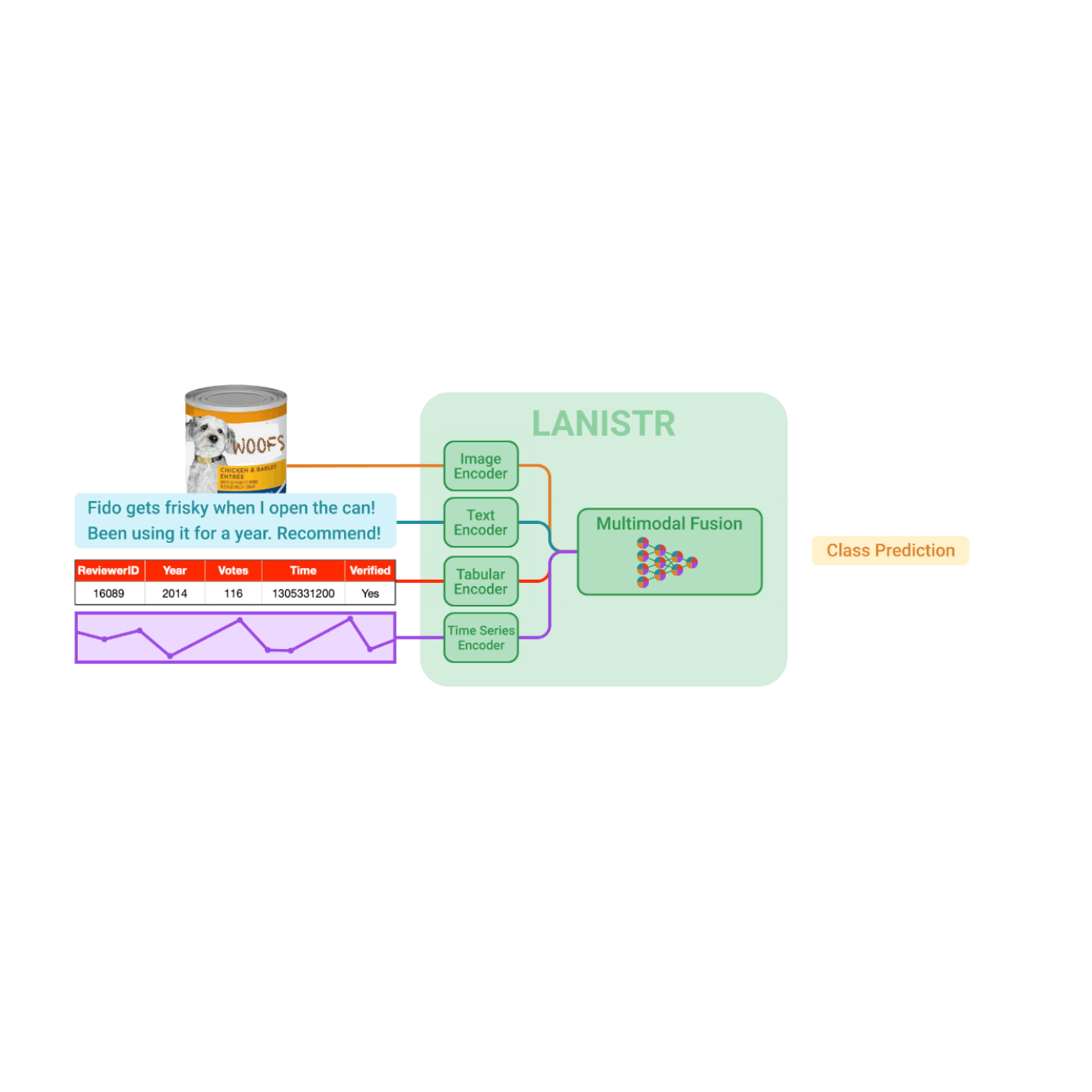
LANISTR’s architecture is composed of modality-specific encoders and a multimodal encoder-decoder module, which acts as the fusion mechanism. First, raw inputs are encoded with a language encoder, an image encoder, and a structured data encoder. Depending on the dataset, we can have two separate structured data encoders, one for tabular data and one for time-series data. These modality-specific encoders are all chosen to be attention-based architectures.
After the inputs are encoded, we project them using modality-specific encoders with a single layer projection head and concatenate their embeddings together before feeding them into the multimodal fusion module.
A common bottleneck when working with multimodal data is extracting meaningful representations that reflect cross-modal interactions between individual modalities. We leverage cross-attention, which has been predominantly used to capture cross-modal relationships, when creating a fusion encoder with six Transformer layers.
The figure below illustrates the LANISTR architecture using a toy example from a retail application. The goal is to predict the star rating a product will receive. In this example, the product is a can of dog food (image), accompanied by a user review (text), numerical and categorical specifications (tabular features), and the user's purchase history (time sequence). LANISTR integrates these different modalities to produce a star rating prediction.
LANISTR enables multimodal learning by ingesting unstructured (image, text) and structured (time series, tabular) data, performing alignment and fusion, and ultimately generating predictions.
The core of LANISTR's methodology is rooted in masking-based training applied across both unimodal and multimodal levels. LANISTR is pre-trained with two types of objectives:
- Unimodal masking objectives.
We use masked language, image, time series, and tabular features modeling as a general self-supervised learning strategy for all the unimodal encoders in LANISTR. This allows the utilization of data with missing modalities for unimodal encoders, since masked inputs are fed to encoders, a form of reconstruction or prediction task can be used for training. - Similarity-based multimodal masking loss.
Prior work on multimodal learning with vision and language, such as FLAVA, focuses on reconstructing one modality (e.g., text) or both image and text modalities from the masked multimodal inputs. In this work, we propose a novel masked multimodal learning loss that maximizes the similarities between masked and unmasked multimodal data representations. This objective resembles an idea that originated from Siamese networks, where the goal is to maximize the similarity between two augmented versions of an image. However, in our framework, the goal is to maximize the similarity between the embeddings generated by a masked and a non-masked input. As shown below, this objective encourages the model to learn cross-modal relations, such that the cosine similarity between the embeddings of a masked and a non-masked data is maximized.
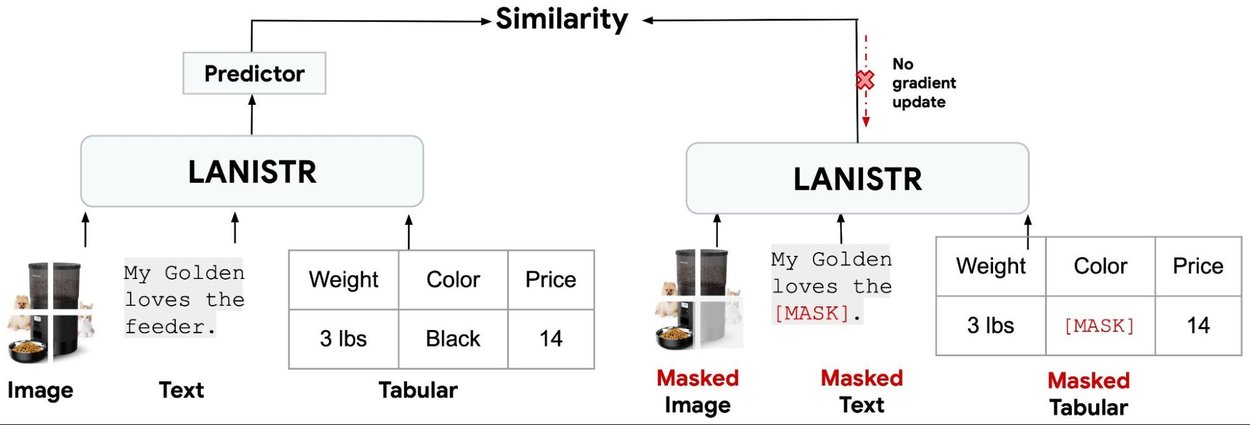
Illustration of similarity-based multimodal masking objective in LANISTR. The goal is to maximize the similarity between the embeddings of a masked and a non-masked input.
After pre-training, we use pre-trained weights to initialize both the unimodal encoders and the multimodal encoder. A multi-layer classification module is then attached to the multimodal encoder for the downstream task. The LANISTR model comprises 300M parameters. During fine-tuning, we maintain the unimodal encoders in a frozen state while concentrating on training the multimodal encoder and the classification module. This accounts for training approximately 15% of the entire architecture. It's worth noting that LANISTR’s versatility extends to other tasks, such as regression or retrieval, by incorporating suitable heads and objective functions, provided labeled data is accessible.
Results
We compare LANISTR’s performance against various competitive baselines, including AutoGluon, ALBEF, and MedFuse, using MIMIC-IV (a widely-used medical dataset for clinical prediction tasks) and Amazon Review Data. With its novel architecture and objective functions, LANISTR achieves state-of-the art results on several challenging tasks.
The plot below highlights the results for mortality prediction using the MIMIC-IV dataset. LANISTR achieves 87.37% in area under the receiver operating characteristic curve (AUROC) on average, significantly outperforming baseline models FLAVA and CoCa, which can only use image and text, and the MedFuse model, which only uses image and time series modalities. The late fusion baseline is a simple fusion mechanism that concatenates all three modality embeddings.
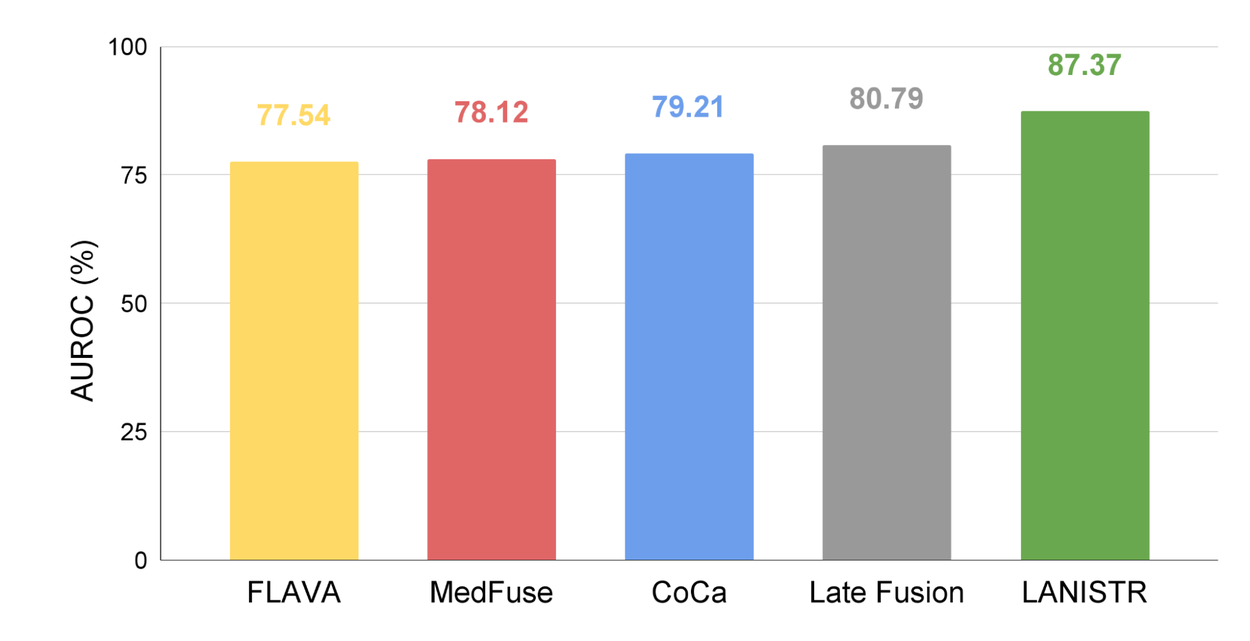
AUROC for in-hospital mortality prediction using the MIMIC-IV dataset.
For predicting product ratings using the Amazon Review dataset, we pre-train methods that can use unlabeled data (LANISTR and ALBEF) from the office products category and fine-tune them using the beauty products category. LANISTR outperforms competitive baselines by a significant margin, achieving an average of 76.27% accuracy. Notably, even without pre-training, LANISTR's unique fusion mechanism surpasses both late fusion and AutoGluon, neither of which support pre-training. For ALBEF, we explored a "Tab2Txt'' approach that incorporates tabular features as additional text input, while the original ALBEF baseline only utilized image and text modalities. We demonstrate that both are significantly outperformed by LANISTR. Our results confirm the importance of learning structured and unstructured data using unlabeled and labeled data together.
Ablation studies and the particular challenges of these tasks illustrate LANISTR’s ability to actively ingest all modalities as they are, take advantage of large quantities of unlabeled data during unsupervised pre-training, and handle missing modalities seamlessly.
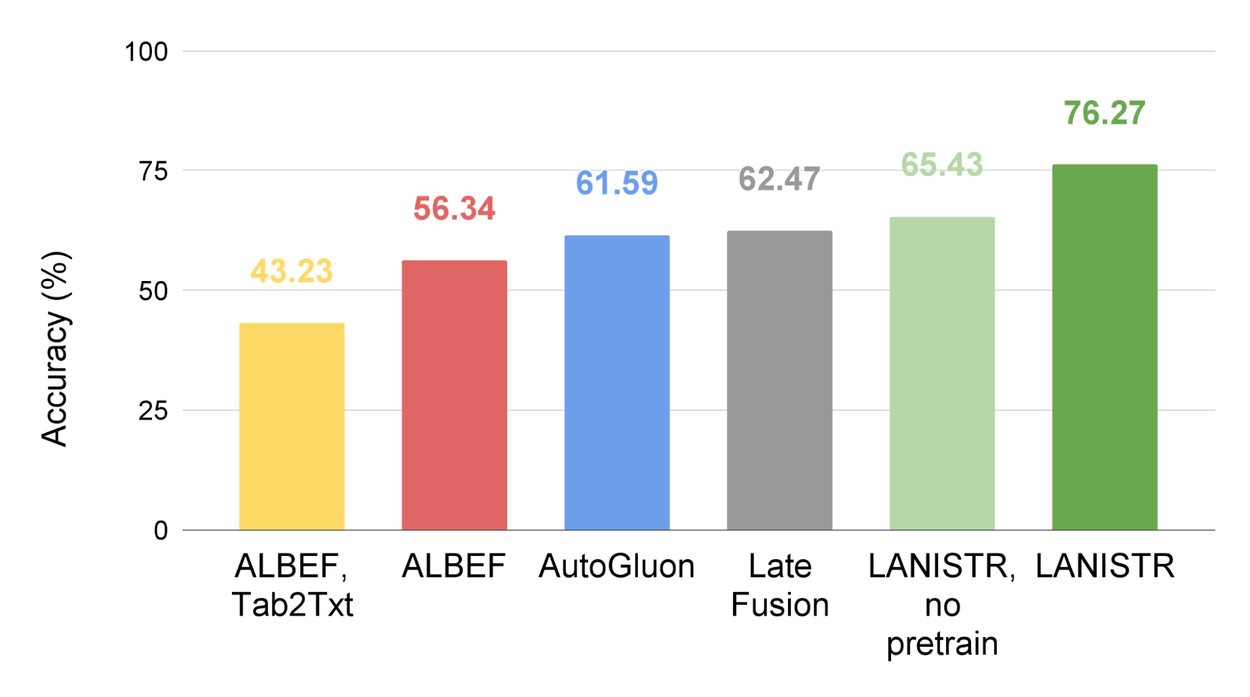
Results using the Amazon Review dataset for star rating prediction tasks on the beauty products category.
Conclusion
LANISTR is a novel framework for language, image, and structured data (tabular and time series). With its unimodal and novel similarity-based multimodal masking strategy, LANISTR tackles challenges including missing modalities and limited labeled data, and achieves state-of-the-art performance across diverse domains.
Acknowledgements
We gratefully acknowledge the contributions of our co-authors, Sercan Arik and Tomas Pfister. Special thanks to Tom Small for creating the animated figure featuring the essence of our research in this blog post.
Quick links
Other posts of interest
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

July 9, 2026
SensorFM: Towards a general intelligence and interface for wearable health data- Generative AI ·
- Machine Intelligence
-

June 30, 2026
Introducing TabFM: A zero-shot foundation model for tabular data- Data Management ·
- Machine Intelligence ·
- Product

AUROC for in-hospital mortality prediction using the MIMIC-IV dataset.

Results using the Amazon Review dataset for star rating prediction tasks on the beauty products category.

Illustration of similarity-based multimodal masking objective in LANISTR. The goal is to maximize the similarity between the embeddings of a masked and a non-masked input.