KELM: Integrating Knowledge Graphs with Language Model Pre-training Corpora
May 20, 2021
Posted by Siamak Shakeri, Staff Software Engineer and Oshin Agarwal, Research Intern, Google Research
Large pre-trained natural language processing (NLP) models, such as BERT, RoBERTa, GPT-3, T5 and REALM, leverage natural language corpora that are derived from the Web and fine-tuned on task specific data, and have made significant advances in various NLP tasks. However, natural language text alone represents a limited coverage of knowledge, and facts may be contained in wordy sentences in many different ways. Furthermore, existence of non-factual information and toxic content in text can eventually cause biases in the resulting models.
Alternate sources of information are knowledge graphs (KGs), which consist of structured data. KGs are factual in nature because the information is usually extracted from more trusted sources, and post-processing filters and human editors ensure inappropriate and incorrect content are removed. Therefore, models that can incorporate them carry the advantages of improved factual accuracy and reduced toxicity. However, their different structural format makes it difficult to integrate them with the existing pre-training corpora in language models.
In “Knowledge Graph Based Synthetic Corpus Generation for Knowledge-Enhanced Language Model Pre-training” (KELM), accepted at NAACL 2021, we explore converting KGs to synthetic natural language sentences to augment existing pre-training corpora, enabling their integration into the pre-training of language models without architectural changes. To that end, we leverage the publicly available English Wikidata KG and convert it into natural language text in order to create a synthetic corpus. We then augment REALM, a retrieval-based language model, with the synthetic corpus as a method of integrating natural language corpora and KGs in pre-training. We have released this corpus publicly for the broader research community.
Converting KG to Natural Language Text
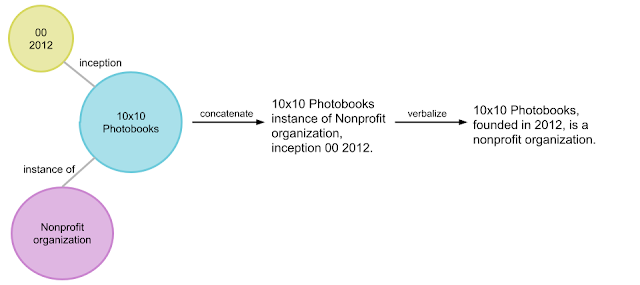
KGs consist of factual information represented explicitly in a structured format, generally in the form of [subject entity, relation, object entity] triples, e.g., [10x10 photobooks, inception, 2012]. A group of related triples is called an entity subgraph. An example of an entity subgraph that builds on the previous example of a triple is { [10x10 photobooks, instance of, Nonprofit Organization], [10x10 photobooks, inception, 2012] }, which is illustrated in the figure below. A KG can be viewed as interconnected entity subgraphs.
Converting subgraphs into natural language text is a standard task in NLP known as data-to-text generation. Although there have been significant advances on data-to-text-generation on benchmark datasets such as WebNLG, converting an entire KG into natural text has additional challenges. The entities and relations in large KGs are more vast and diverse than small benchmark datasets. Moreover, benchmark datasets consist of predefined subgraphs that can form fluent meaningful sentences. With an entire KG, such a segmentation into entity subgraphs needs to be created as well.
 |
| An example illustration of how the pipeline converts an entity subgraph (in bubbles) into synthetic natural sentences (far right). |
In order to convert the Wikidata KG into synthetic natural sentences, we developed a verbalization pipeline named “Text from KG Generator” (TEKGEN), which is made up of the following components: a large training corpus of heuristically aligned Wikipedia text and Wikidata KG triples, a text-to-text generator (T5) to convert the KG triples to text, an entity subgraph creator for generating groups of triples to be verbalized together, and finally, a post-processing filter to remove low quality outputs. The result is a corpus containing the entire Wikidata KG as natural text, which we call the Knowledge-Enhanced Language Model (KELM) corpus. It consists of ~18M sentences spanning ~45M triples and ~1500 relations.
 |
| Converting a KG to natural language, which is then used for language model augmentation |
Integrating Knowledge Graph and Natural Text for Language Model Pre-training
Our evaluation shows that KG verbalization is an effective method of integrating KGs with natural language text. We demonstrate this by augmenting the retrieval corpus of REALM, which includes only Wikipedia text.
To assess the effectiveness of verbalization, we augment the REALM retrieval corpus with the KELM corpus (i.e., “verbalized triples”) and compare its performance against augmentation with concatenated triples without verbalization. We measure the accuracy with each data augmentation technique on two popular open-domain question answering datasets: Natural Questions and Web Questions.
 |
Augmenting REALM with even the concatenated triples improves accuracy, potentially adding information not expressed in text explicitly or at all. However, augmentation with verbalized triples allows for a smoother integration of the KG with the natural language text corpus, as demonstrated by the higher accuracy. We also observed the same trend on a knowledge probe called LAMA that queries the model using fill-in-the-blank questions.
Conclusion
With KELM, we provide a publicly-available corpus of a KG as natural text. We show that KG verbalization can be used to integrate KGs with natural text corpora to overcome their structural differences. This has real-world applications for knowledge-intensive tasks, such as question answering, where providing factual knowledge is essential. Moreover, such corpora can be applied in pre-training of large language models, and can potentially reduce toxicity and improve factuality. We hope that this work encourages further advances in integrating structured knowledge sources into pre-training of large language models.
Acknowledgements
This work has been a collaborative effort involving Oshin Agarwal, Heming Ge, Siamak Shakeri and Rami Al-Rfou. We thank William Woods, Jonni Kanerva, Tania Rojas-Esponda, Jianmo Ni, Aaron Cohen and Itai Rolnick for rating a sample of the synthetic corpus to evaluate its quality. We also thank Kelvin Guu for his valuable feedback on the paper.
Other posts of interest
-

July 26, 2024
Smoothly editing material properties of objects with text-to-image models and synthetic data- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence ·
- Machine Perception
-

July 25, 2024
A step towards making heart health screening accessible for billions with PPG signals- Health & Bioscience ·
- Machine Intelligence
-
July 22, 2024
Fast, accurate climate modeling with NeuralGCM- Climate & Sustainability ·
- General Science ·
- Machine Intelligence ·
- Open Source Models & Datasets