Improving Holistic Scene Understanding with Panoptic-DeepLab
July 21, 2020
Posted by Bowen Cheng, Student Researcher and Liang-Chieh Chen, Research Scientist, Google Research
Quick links
Real-world computer vision applications, such as self-driving cars and robotics, rely on two core tasks — instance segmentation and semantic segmentation. Instance segmentation identifies the class and extent of individual “things” in an image (i.e., countable objects such as people, animals, cars, etc.) and assigns unique identifiers to each (e.g., car_1 and car_2). This is complemented by semantic segmentation, which labels all pixels in an image, including the “things” that are present as well as the surrounding “stuff” (e.g., amorphous regions of similar texture or material, such as grass, sky or road). This latter task, however, does not differentiate between pixels of the same class that belong to different instances of that class.
Panoptic segmentation represents the unification of these two approaches with the goal of assigning a unique value to every pixel in an image that encodes both semantic label and instance ID. Most existing panoptic segmentation algorithms are based on Mask R-CNN, which treats semantic and instance segmentation separately. The instance segmentation step identifies objects in an image, but it often produces object instance masks that overlap one another. To settle the conflict between overlapping instance masks, one commonly employs an heuristic that resolves the discrepancy either based on the mask with a higher confidence score or by use of a pre-defined pairwise relationship between categories (e.g., a tie should always be worn on a person’s front). Additionally, the discrepancies between semantic and instance segmentation results are sorted out by favoring the instance predictions. While these methods generally produce good results, they also introduce heavy latency, which makes it challenging to apply them in real-time applications.
Driven by the need of a real-time panoptic segmentation model, we propose “Panoptic-DeepLab: a simple, fast and strong system for panoptic segmentation”, accepted to CVPR 2020. In this work, we extend the commonly used modern semantic segmentation model, DeepLab, to perform panoptic segmentation using only a small number of additional parameters with the addition of marginal computation overhead. The resulting model, Panoptic-DeepLab, produces semantic and instance segmentation in parallel and without overlap, avoiding the need for the manually designed heuristics adopted by other methods. Additionally, we develop a computationally efficient operation that merges the semantic and instance segmentation results, enabling near real-time end-to-end panoptic segmentation prediction. Unlike methods based on Mask R-CNN, Panoptic-DeepLab does not generate bounding box predictions and requires only three loss functions during training, significantly fewer than current state-of-the-art methods, such as UPSNet, which can have up to eight. Finally, Panoptic-DeepLab has demonstrated state-of-the-art performance on several academic datasets.
 |
| Panoptic segmentation results obtained by Panoptic-DeepLab. Left: Video frames used as input to the panoptic segmentation model. Right: Results overlaid on video frames. Each object instance has a unique label, e.g., car_1, car_2, etc. |
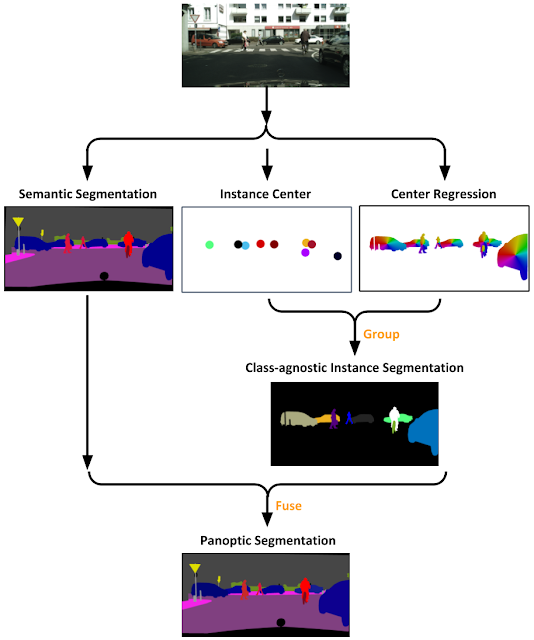
Panoptic-DeepLab is simple both conceptually and architecturally. At a high-level, it predicts three outputs. The first is semantic segmentation, in which it assigns a semantic class (e.g., car or grass) to each pixel. However, it does not differentiate between multiple instances of the same class. So, for example, if one car is partly behind another, the pixels associated with both would have the same associated class and would be indistinguishable from one another. This can be addressed by the second two outputs from the model: a center-of-mass prediction for each instance and instance center regression, where the model learns to regress each instance pixel to its center of mass. This latter step ensures that the model associates pixels of a given class to the appropriate instance. The class-agnostic instance segmentation, obtained by grouping predicted foreground pixels to their closest predicted instance centers, is then fused with semantic segmentation by majority-vote rule to generate the final panoptic segmentation.
 |
| Overview of Panoptic-DeepLab. Semantic segmentation associates pixels in the image with general classes, while the class-agnostic instance segmentation step identifies the pixels associated with an individual object, regardless of the class. Taken together one gets the final panoptic segmentation image. |
Panoptic-DeepLab consists of four components: (1) an encoder backbone pre-trained on ImageNet, shared by both the semantic segmentation and instance segmentation branches of the architecture; (2) atrous spatial pyramid pooling (ASPP) modules, similar to that used by DeepLab, which are deployed independently in each branch in order to perform segmentation at a range of spatial scales; (3) similarly decoupled decoder modules specific to each segmentation task; and (4) task-specific prediction heads.
The encoder backbone (1), which has been pre-trained on ImageNet, extracts feature maps that are shared by both the semantic segmentation and instance segmentation branches of the architecture. Typically, the feature map is generated by the backbone model using a standard convolution, which reduces the resolution of the output map to 1/32nd that of the input image and is too coarse for accurate image segmentation. In order to preserve the details of object boundaries, we instead employ atrous convolution, which better retains important features like edges, to generate a feature map with a resolution of 1/16th the original. This is then followed by two ASPP modules (2), one for each branch, which captures multi-scale information for segmentation.
The light-weight decoder modules (3) follow those used in the most recent DeepLab version (DeepLabV3+), but with two modifications. First, we reintroduce an additional low-level feature map (1/8th scale) to the decoder, which helps to preserve spatial information from the original image (e.g., object boundaries) that can be significantly degraded in the final feature map output by the backbone. Second, instead of using the typical 3 × 3 kernel, the decoder employs a 5 × 5 depthwise-separable convolution, which yields somewhat better performance at only a minimal cost in additional overhead.
The two prediction heads (4) are tailored to their task. The semantic segmentation head employs a weighted version of the standard bootstrapped cross entropy loss function, which weights each pixel differently and has proven to be more effective for segmentation of small-scale objects. The instance segmentation head is trained to predict the offsets between the center of mass of an object instance and the surrounding pixels, without knowledge of the object class, forming the class-agnostic instance masks.
Results
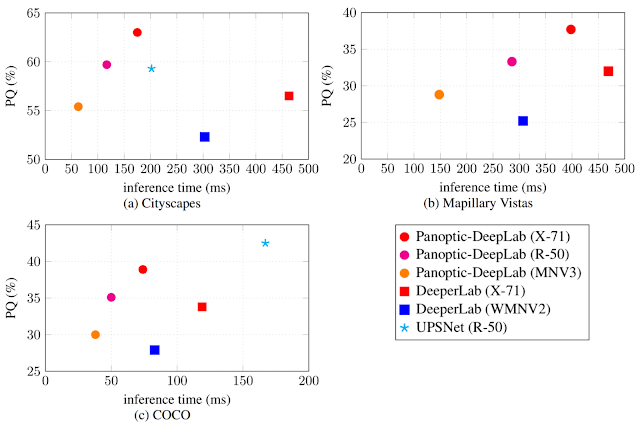
To demonstrate the effectiveness of Panoptic-DeepLab, we conduct experiments on three popular academic datasets, Cityscapes, Mapillary Vistas, and COCO datasets. With a simple architecture, Panoptic-DeepLab ranks first in Cityscapes for all three tasks (semantic, instance and panoptic segmentation) without any task-specific fine-tuning. Additionally, Panoptic-DeepLab won the Best Result, Best Paper, and Most Innovative awards on the Mapillary Panoptic Segmentation track at ICCV 2019 Joint COCO and Mapillary Recognition Challenge Workshop. It outperforms the winner of 2018 by a healthy margin of 1.5%. Finally, Panoptic-DeepLab sets new state-of-the-art bottom-up (i.e., box-free) panoptic segmentation results on the COCO dataset, and is also comparable to other methods based on Mask R-CNN.
 |
| Accuracy (PQ) vs. Speed (GPU inference time) across three datasets. |
With a simple architecture and only three training loss functions, Panoptic-DeepLab achieves state-of-the-art performance while being faster than other methods based on Mask R-CNN. To summarize, we develop the first single-shot panoptic segmentation model that attains state-of-the-art performance on several public benchmarks, and delivers near real time end-to-end inference speed. We hope our simple and effective Panoptic-DeepLab could establish a solid baseline and further benefit the research community.
Acknowledgements
We would like to thank the support and valuable discussions with Maxwell D. Collins, Yukun Zhu, Ting Liu, Thomas S. Huang, Hartwig Adam, Florian Schroff as well as the Google Mobile Vision team.
Quick links
Other posts of interest
-

February 17, 2026
Teaching AI to read a map- Machine Perception ·
- Open Source Models & Datasets
-

January 22, 2026
Small models, big results: Achieving superior intent extraction through decomposition- Generative AI ·
- Machine Perception ·
- Mobile Systems
-

December 12, 2025
Spotlight on innovation: Google-sponsored Data Science for Health Ideathon across Africa- Conferences & Events ·
- Generative AI ·
- Global ·
- Health & Bioscience
×
❮
❯