From Pixels to Actions: Human-level control through Deep Reinforcement Learning
February 25, 2015
Posted by Dharshan Kumaran and Demis Hassabis, Google DeepMind, London
Quick links
Remember the classic videogame Breakout on the Atari 2600? When you first sat down to try it, you probably learned to play well pretty quickly, because you already knew how to bounce a ball off a wall in real life. You may have even worked up a strategy to maximise your overall score at the expense of more immediate rewards. But what if you didn't possess that real-world knowledge — and only had the pixels on the screen, the control paddle in your hand, and the score to go on? How would you, or equally any intelligent agent faced with this situation, learn this task totally from scratch?
This is exactly the question that we set out to answer in our paper “Human-level control through deep reinforcement learning”, published in Nature this week. We demonstrate that a novel algorithm called a deep Q-network (DQN) is up to this challenge, excelling not only at Breakout but also a wide variety of classic videogames: everything from side-scrolling shooters (River Raid) to boxing (Boxing) and 3D car racing (Enduro). Strikingly, DQN was able to work straight “out of the box” across all these games – using the same network architecture and tuning parameters throughout and provided only with the raw screen pixels, set of available actions and game score as input.
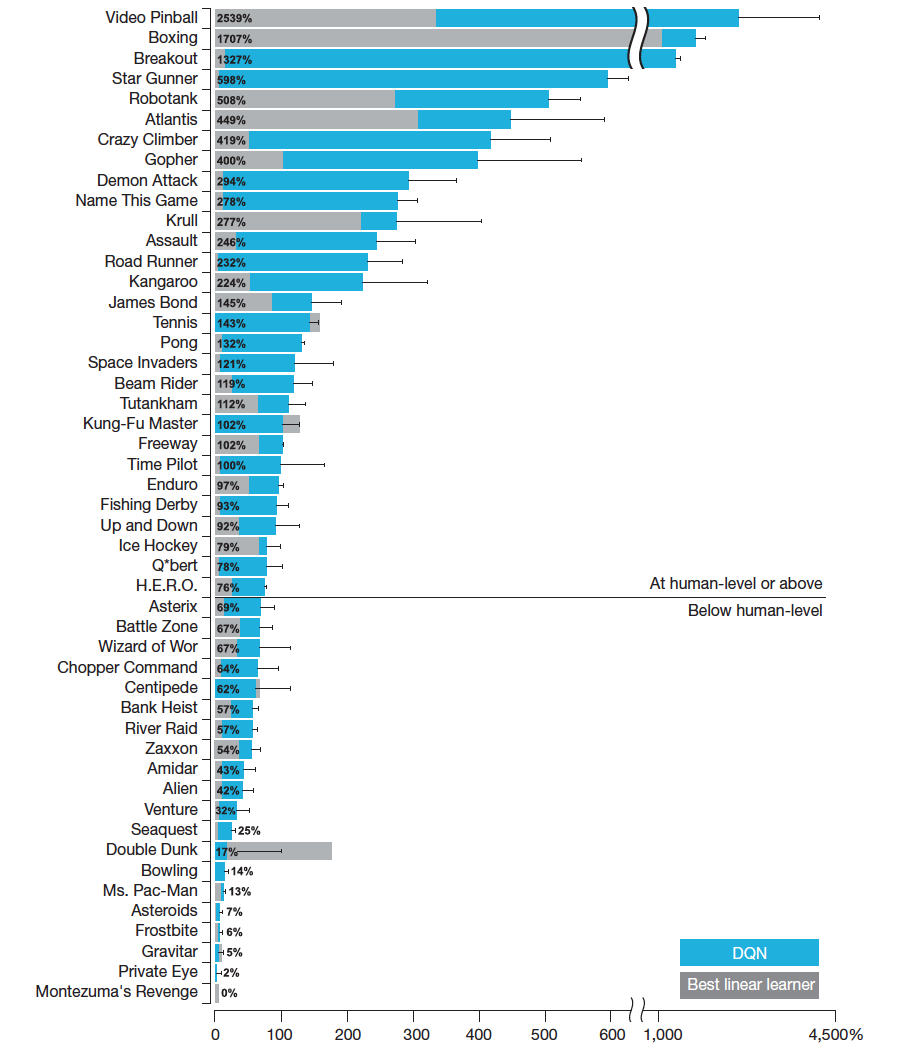
The results: DQN outperformed previous machine learning methods in 43 of the 49 games. In fact, in more than half the games, it performed at more than 75% of the level of a professional human player. In certain games, DQN even came up with surprisingly far-sighted strategies that allowed it to achieve the maximum attainable score—for example, in Breakout, it learned to first dig a tunnel at one end of the brick wall so the ball could bounce around the back and knock out bricks from behind.
So how does it work? DQN incorporated several key features that for the first time enabled the power of Deep Neural Networks (DNN) to be combined in a scalable fashion with Reinforcement Learning (RL)—a machine learning framework that prescribes how agents should act in an environment in order to maximize future cumulative reward (e.g., a game score). Foremost among these was a neurobiologically inspired mechanism, termed “experience replay,” whereby during the learning phase DQN was trained on samples drawn from a pool of stored episodes—a process physically realized in a brain structure called the hippocampus through the ultra-fast reactivation of recent experiences during rest periods (e.g., sleep). Indeed, the incorporation of experience replay was critical to the success of DQN: disabling this function caused a severe deterioration in performance.
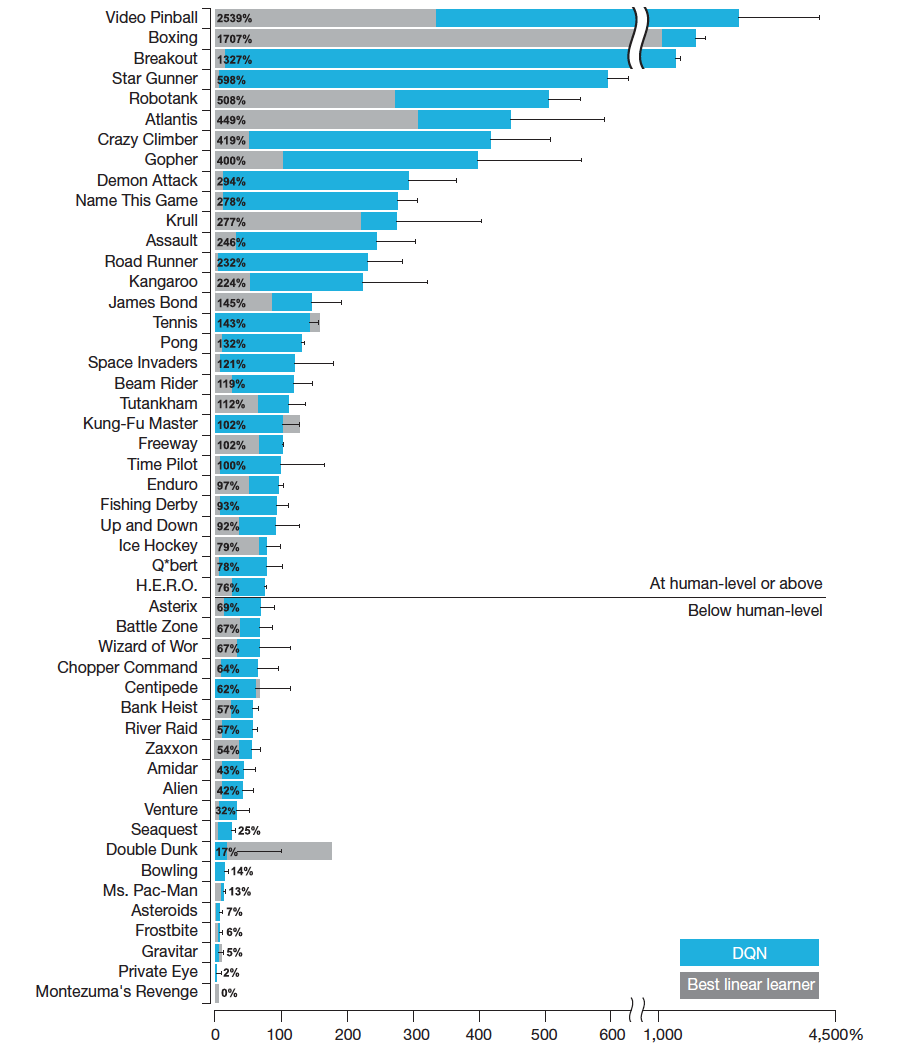 |
| Comparison of the DQN agent with the best reinforcement learning methods in the literature. The performance of DQN is normalized with respect to a professional human games tester (100% level) and random play (0% level). Note that the normalized performance of DQN, expressed as a percentage, is calculated as: 100 X (DQN score - random play score)/(human score - random play score). Error bars indicate s.d. across the 30 evaluation episodes, starting with different initial conditions. Figure courtesy of Mnih et al. “Human-level control through deep reinforcement learning”, Nature 26 Feb. 2015. |
This work offers the first demonstration of a general purpose learning agent that can be trained end-to-end to handle a wide variety of challenging tasks, taking in only raw pixels as inputs and transforming these into actions that can be executed in real-time. This kind of technology should help us build more useful products—imagine if you could ask the Google app to complete any kind of complex task (“Okay Google, plan me a great backpacking trip through Europe!”).
We also hope this kind of domain general learning algorithm will give researchers new ways to make sense of complex large-scale data creating the potential for exciting discoveries in fields such as climate science, physics, medicine and genomics. And it may even help scientists better understand the process by which humans learn. After all, as the great physicist Richard Feynman famously said: “What I cannot create, I do not understand.”
Quick links
Other posts of interest
-

July 30, 2026
Science One Framework: A verifiable autonomous research framework via Chain-of-Evidence- General Science ·
- Machine Intelligence ·
- Natural Language Processing
-

July 22, 2026
Towards a quantum computer that learns from its errors- Machine Intelligence ·
- Quantum
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence