EfficientDet: Towards Scalable and Efficient Object Detection
April 15, 2020
Posted by Mingxing Tan, Software Engineer and Adams Yu, Research Scientist, Google Research
Quick links
As one of the core applications in computer vision, object detection has become increasingly important in scenarios that demand high accuracy, but have limited computational resources, such as robotics and driverless cars. Unfortunately, many current high-accuracy detectors do not fit these constraints. More importantly, real-world applications of object detection are run on a variety of platforms, which often demand different resources. A natural question, then, is how to design accurate and efficient object detectors that can also adapt to a wide range of resource constraints?
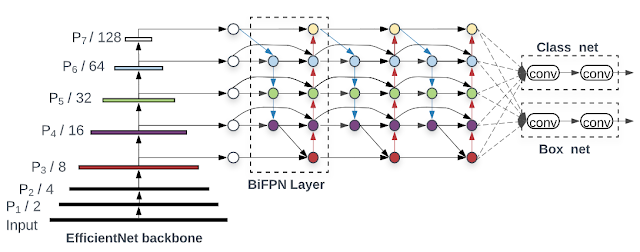
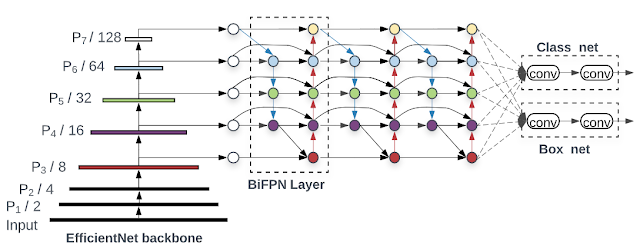
In “EfficientDet: Scalable and Efficient Object Detection”, accepted at CVPR 2020, we introduce a new family of scalable and efficient object detectors. Building upon our previous work on scaling neural networks (EfficientNet), and incorporating a novel bi-directional feature network (BiFPN) and new scaling rules, EfficientDet achieves state-of-the-art accuracy while being up to 9x smaller and using significantly less computation compared to prior state-of-the-art detectors. The following figure shows the overall network architecture of our models.
 |
| EfficientDet architecture. EfficientDet uses EfficientNet as the backbone network and a newly proposed BiFPN feature network. |
The idea behind EfficientDet arose from our effort to find solutions to improve computational efficiency by conducting a systematic study of prior state-of-the-art detection models. In general, object detectors have three main components: a backbone that extracts features from the given image; a feature network that takes multiple levels of features from the backbone as input and outputs a list of fused features that represent salient characteristics of the image; and the final class/box network that uses the fused features to predict the class and location of each object. By examining the design choices for these components, we identified several key optimizations to improve performance and efficiency:
Previous detectors mainly rely on ResNets, ResNeXt, or AmoebaNet as backbone networks, which are all either less powerful or have lower efficiency than EfficientNets. By first implementing an EfficientNet backbone, it is possible to achieve much better efficiency. For example, starting from a RetinaNet baseline that employs ResNet-50 backbone, our ablation study shows that simply replacing ResNet-50 with EfficientNet-B3 can improve accuracy by 3% while reducing computation by 20%.
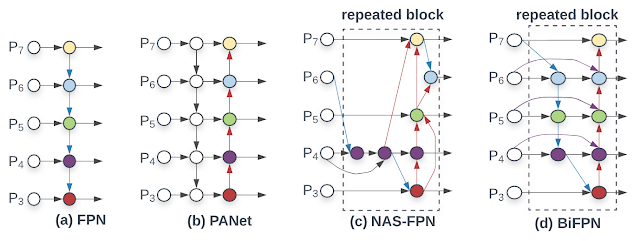
Another optimization is to improve the efficiency of the feature networks. While most previous detectors simply employ a top-down feature pyramid network (FPN), we find top-down FPN is inherently limited by the one-way information flow. Alternative FPNs, such as PANet, add an additional bottom-up flow at the cost of more computation. Recent efforts to leverage neural architecture search (NAS) discovered the more complex NAS-FPN architecture. However, while this network structure is effective, it is also irregular and highly optimized for a specific task, which makes it difficult to adapt to other tasks.
To address these issues, we propose a new bi-directional feature network, BiFPN, which incorporates the multi-level feature fusion idea from FPN/PANet/NAS-FPN that enables information to flow in both the top-down and bottom-up directions, while using regular and efficient connections.
 |
| A comparison between our BiFPN and previous feature networks. Our BiFPN allows features (from the low resolution P3 levels to high-resolution P7 levels) to repeatedly flow in both top-down and bottom-up ways. |
A third optimization involves achieving better accuracy and efficiency trade-offs under different resource constraints. Our previous work has shown that jointly scaling the depth, width and resolution of a network can significantly improve efficiency for image recognition. Inspired by this idea, we propose a new compound scaling method for object detectors, which jointly scales up the resolution/depth/width. Each network component, i.e., backbone, feature, and box/class prediction network, will have a single compound scaling factor that controls all scaling dimensions using heuristic-based rules. This approach enables one to easily determine how to scale the model by computing the scaling factor for the given target resource constraints.
Combining the new backbone and BiFPN, we first develop a small-size EfficientDet-D0 baseline, and then apply a compound scaling to obtain EfficientDet-D1 to D7. Each consecutive model has a higher compute cost, covering a wide range of resource constraints from 3 billion FLOPs to 300 billion FLOPS, and provides higher accuracy.
Model Performance
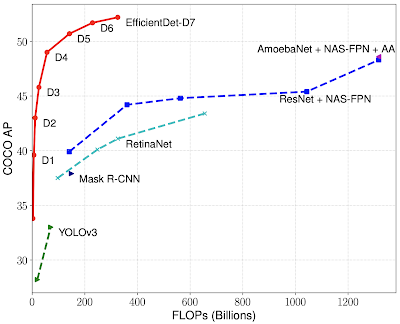
We evaluate EfficientDet on the COCO dataset, a widely used benchmark dataset for object detection. EfficientDet-D7 achieves a mean average precision (mAP) of 52.2, exceeding the prior state-of-the-art model by 1.5 points, while using 4x fewer parameters and 9.4x less computation.
 |
| EfficientDet achieves state-of-the-art 52.2 mAP, up 1.5 points from the prior state of the art (not shown since it is at 3045B FLOPs) on COCO test-dev under the same setting. Under the same accuracy constraint, EfficientDet models are 4x-9x smaller and use 13x-42x less computation than previous detectors. |
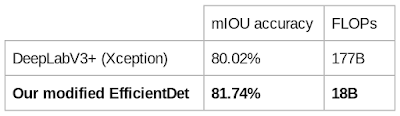
While the EfficientDet models are mainly designed for object detection, we also examine their performance on other tasks, such as semantic segmentation. To perform segmentation tasks, we slightly modify EfficientDet-D4 by replacing the detection head and loss function with a segmentation head and loss, while keeping the same scaled backbone and BiFPN. We compare this model with prior state-of-the-art segmentation models for Pascal VOC 2012, a widely used dataset for segmentation benchmark.
 |
| EfficientDet achieves better quality on Pascal VOC 2012 val than DeepLabV3+ with 9.8x less computation, under the same setting without COCO pre-training. |
Given their exceptional performance, we expect EfficientDet could serve as a new foundation of future object detection related research, and potentially make high-accuracy object detection models practically useful for many real-world applications. Therefore, we have open sourced all the code and pretrained model checkpoints on GitHub.
Acknowledgements
Thanks to the paper co-authors Ruoming Pang and Quoc V. Le. We thank Daiyi Peng, Golnaz Ghiasi, Tianjian Meng for their help on infrastructure and discussion. We also thank Adam Kraft, Barret Zoph, Ekin D. Cubuk, Hongkun Yu, Jeff Dean, Pengchong Jin, Samy Bengio, Tsung-Yi Lin, Xianzhi Du, Xiaodan Song, and the Google Brain team.
Quick links
Other posts of interest
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

July 7, 2026
The power of collaboration: How we can reduce traffic congestion- Algorithms & Theory ·
- Climate & Sustainability ·
- Data Mining & Modeling
-

June 25, 2026
Optimizing cloud economics with linear elastic caching- Algorithms & Theory ·
- Data Management
×
❮
❯