An Optimistic Perspective on Offline Reinforcement Learning
April 14, 2020
Posted by Rishabh Agarwal, AI Resident and Mohammad Norouzi, Research Scientist, Google Research
Quick links
| “The potential for off-policy learning remains tantalizing, the best way to achieve it still a mystery.” |
| — Sutton & Barto |
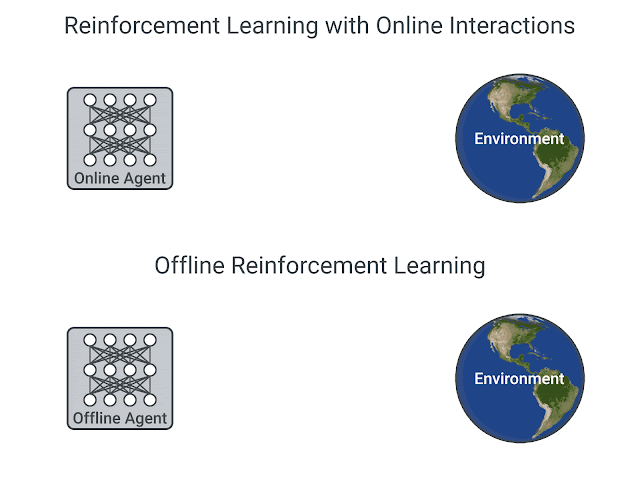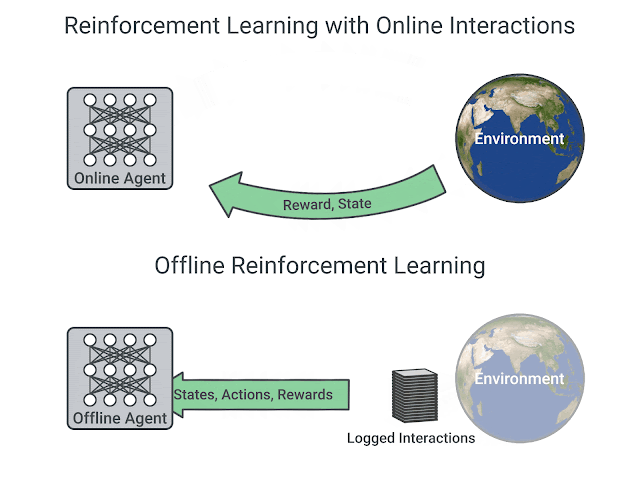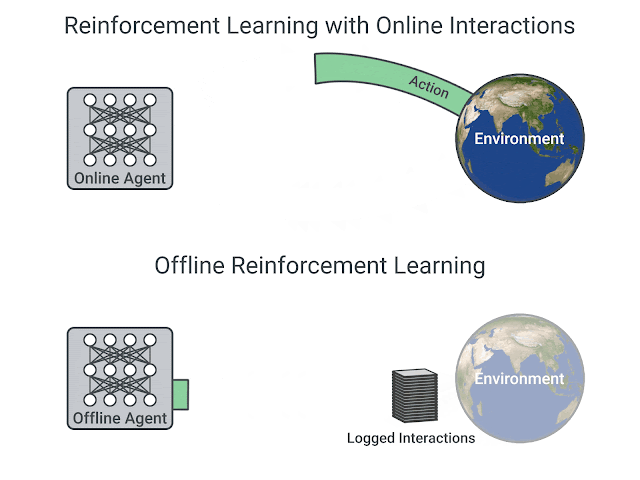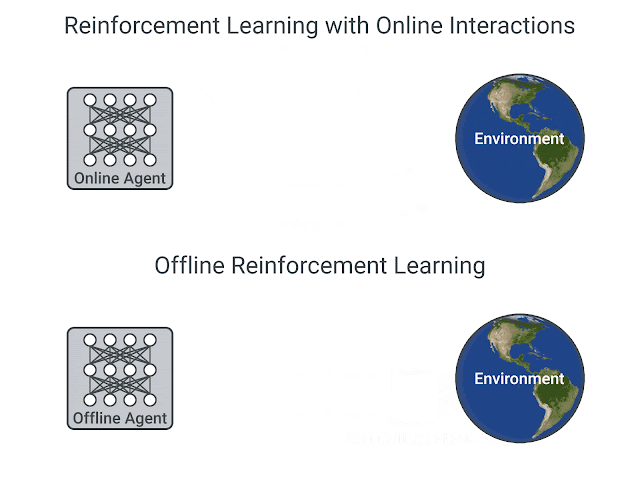
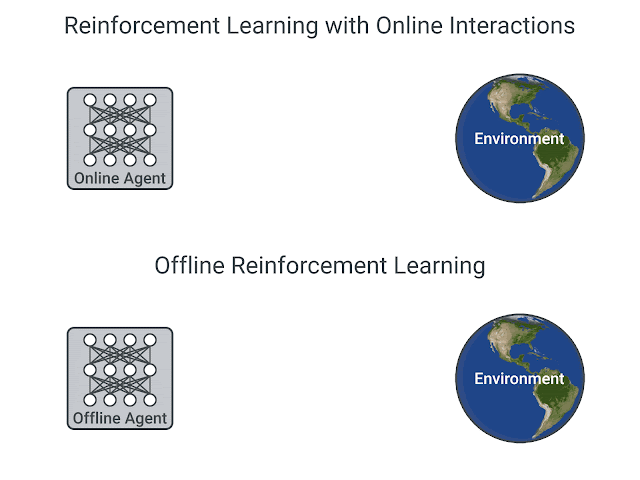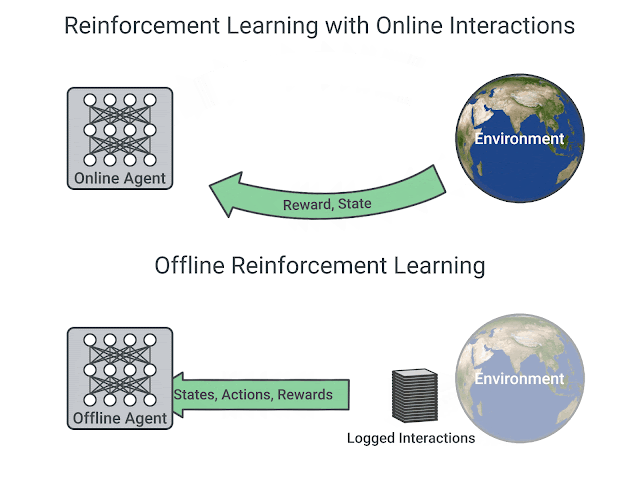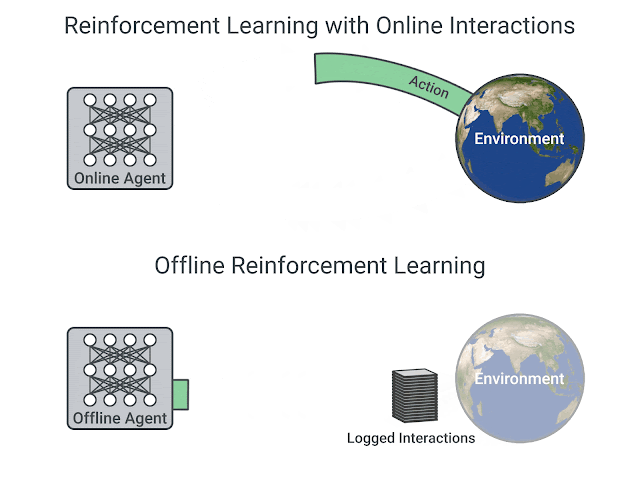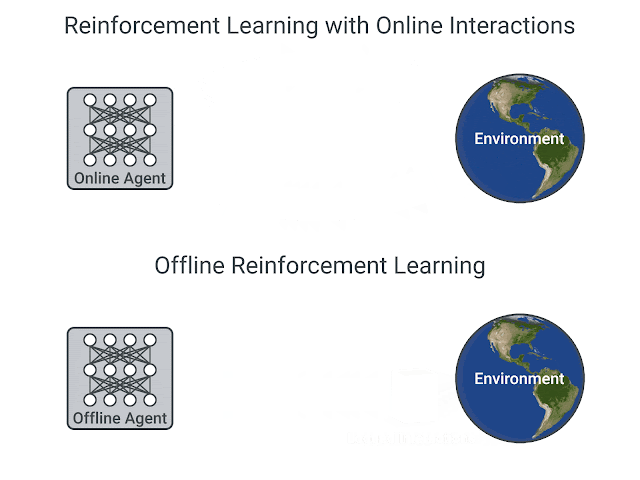
Existing interaction data can be used effectively using offline RL, which is the fully off-policy RL setting in which an agent is trained from a fixed dataset of logged experiences, without any further interactions with the environment. Offline RL can help (1) pretrain an RL agent using existing data, (2) empirically evaluate RL algorithms based on their ability to utilize a fixed dataset of interactions, and (3) deliver real-world impact. However, offline RL is considered challenging due to the distribution mismatch between online interactions and any fixed dataset of logged interactions, i.e., when the learned agent takes an action different from the data collection agent, we don’t know the reward that should be provided.
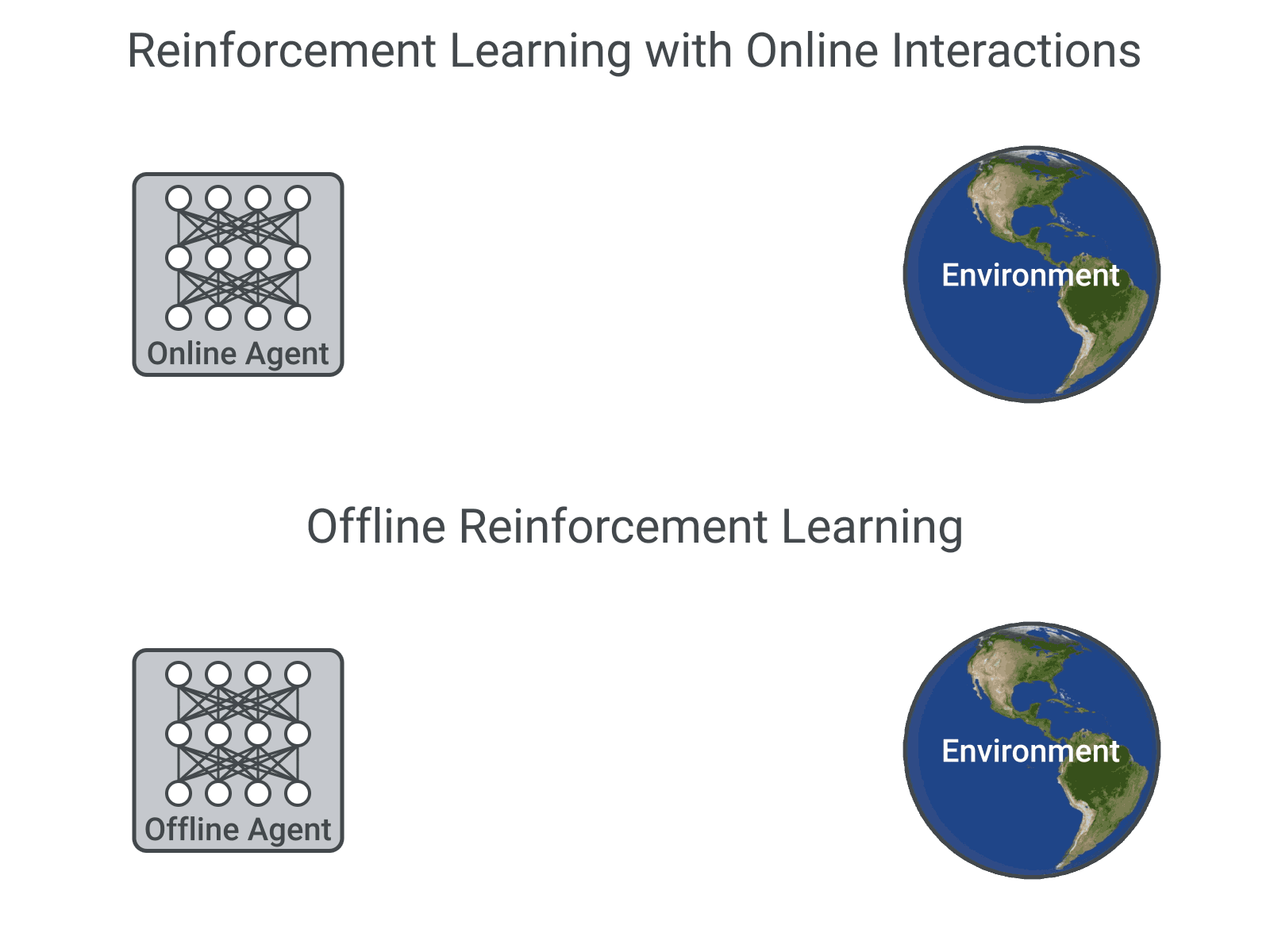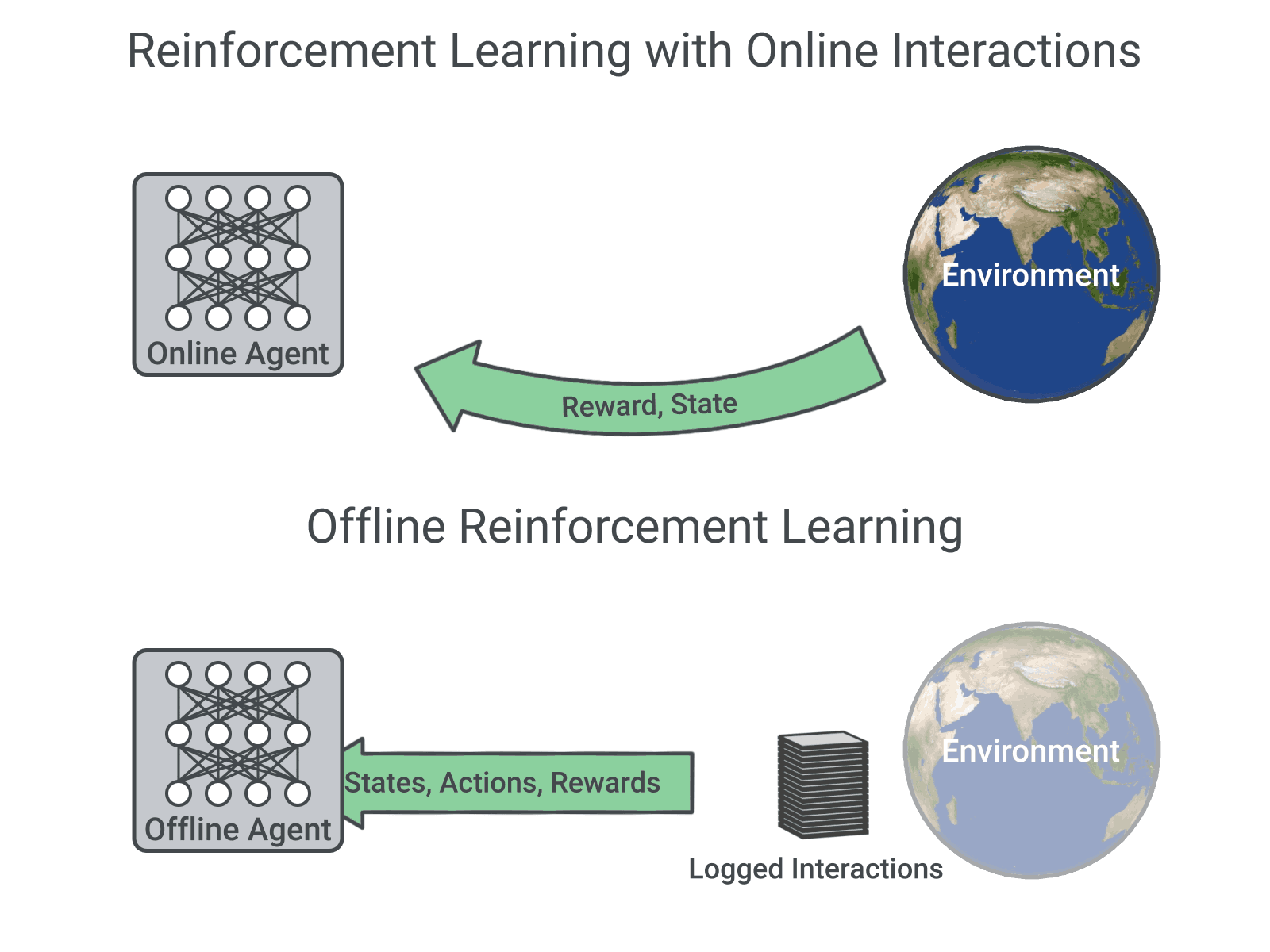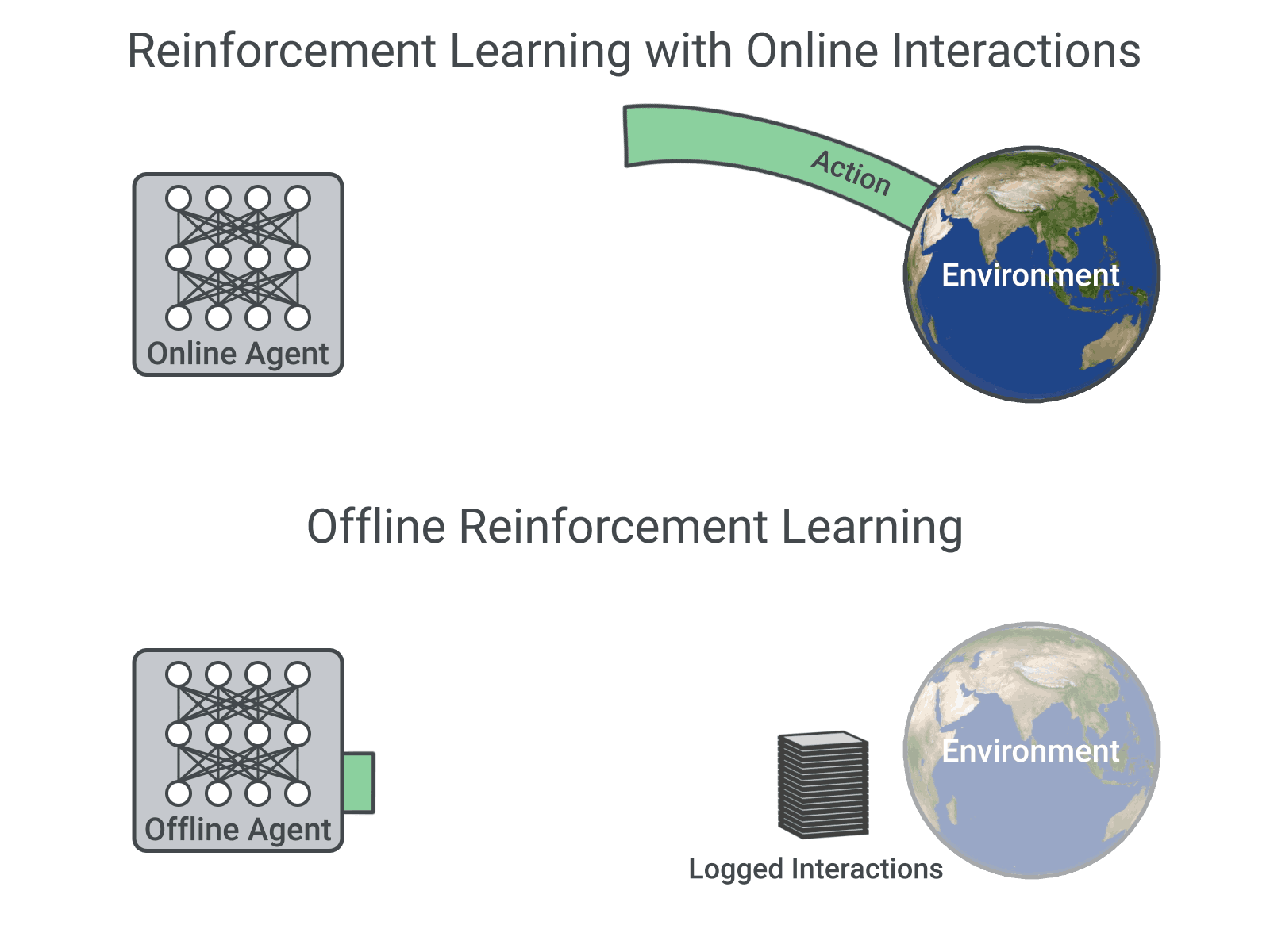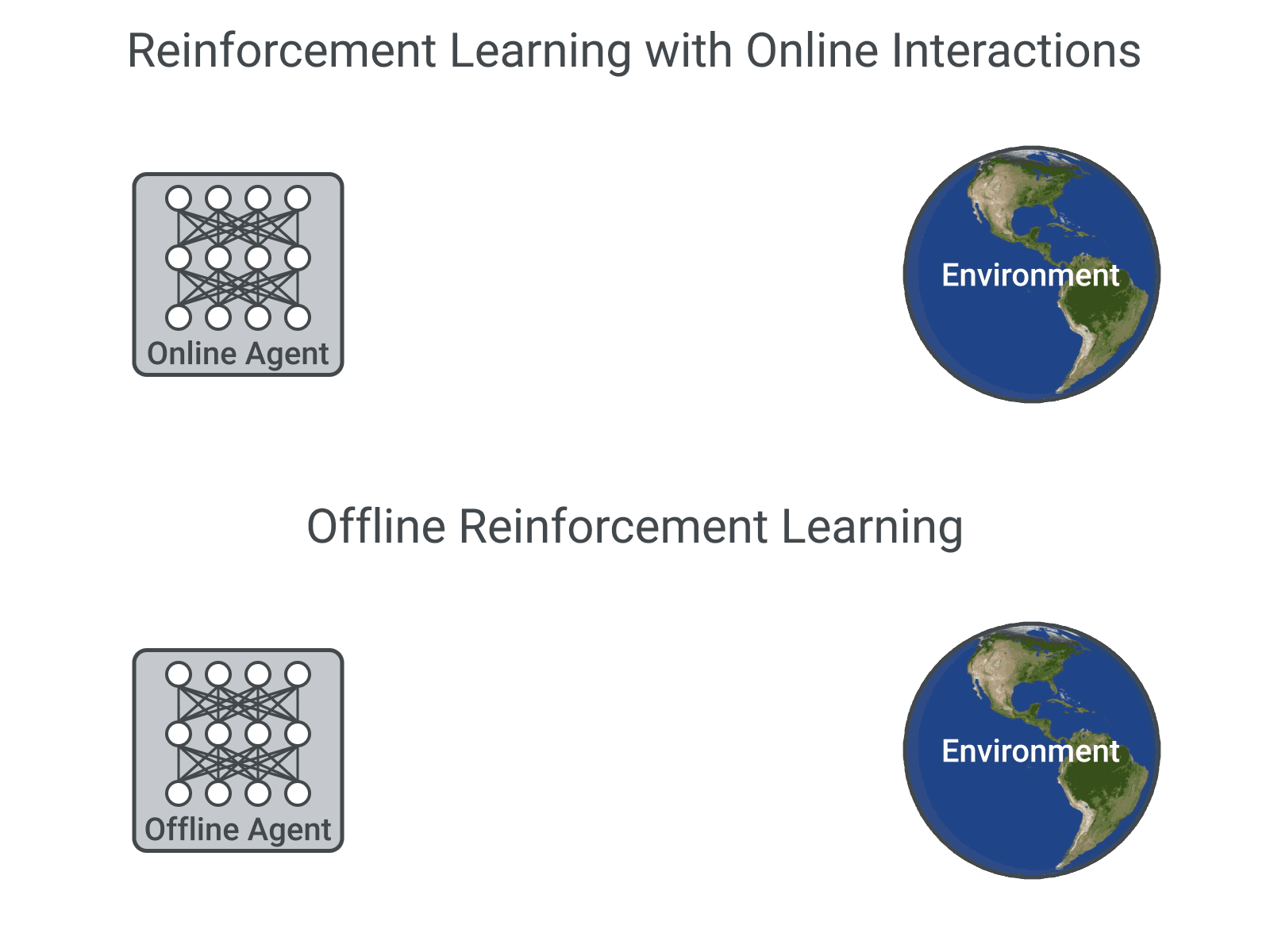 |
| RL with online interactions vs. Offline RL. |
A Primer on Off-policy and Offline RL
We summarize various approaches to RL below:

In principle, off-policy RL agents can learn from data collected by any policy, not just the policy being optimized. However, in the offline RL setting, recent work presents a discouraging view that standard off-policy agents diverge or otherwise yield poor performance. To fix this, previous work proposes remedies by regularizing the learned policy to stay close to the dataset of offline interactions.
The DQN Replay Dataset for Offline RL
In this work, we revisit offline RL by first creating the DQN Replay Dataset. This dataset is generated using DQN agents trained on 60 Atari 2600 games for 200 million frames each, while using sticky actions (with 25% probability that the agent’s previous action is executed instead of the current action) to make the problem more challenging. For each of the 60 games, we train 5 DQN agents with different random initializations, and store all of the (state, action, reward, next state) tuples encountered during training into 5 replay datasets per game, resulting in a total of 300 datasets.
 |
| Offline RL on Atari games using the DQN Replay Dataset. |
Training Offline Agents on the DQN Replay Dataset
We trained offline variants of DQN and distributional QR-DQN on the DQN Replay Dataset. Although the offline datasets contain data experienced by a DQN agent improving over time as training progresses, we compared the performance of offline agents against the best performing online DQN agent obtained after training (i.e., a fully-trained DQN). For each game, we evaluated the 5 offline agents trained (one per dataset), using online returns, reporting the best averaged performance.
Offline DQN underperforms fully-trained online DQN on all except a few games, where it achieves higher scores with the same amount of data. Offline QR-DQN, on the other hand, outperforms offline DQN and fully-trained DQN on most of the games. These results demonstrate that it is possible to optimize strong agents offline using standard deep RL algorithms. Furthermore, the disparity between the performance of offline QR-DQN and DQN indicates the difference in their ability to exploit offline data.
 |
| Offline DQN. Normalized improvement over a fully-trained DQN, per game, of offline DQN trained using DQN replay. On the normalized scale, fully-trained DQN corresponds to 100% performance while random agent corresponds to 0%. |
 |
| Offline QR-DQN. Normalized performance improvement (in %) over a fully-trained DQN agent, per game, of offline QR-DQN trained offline using DQN replay. |
In online RL, an agent chooses actions that it thinks will lead to high rewards, and then receives corrective feedback. Since it is not possible to collect additional data in offline RL, it is essential to reason about generalization using a fixed dataset. Leveraging methods from supervised learning that use an ensemble of models to improve generalization, we present two new offline RL agents:
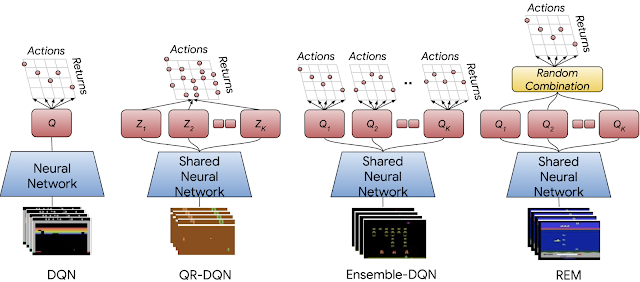
- Ensemble-DQN is a simple extension of DQN that trains multiple Q-value estimates and averages them for evaluation.
- Random Ensemble Mixture (REM) is an easy to implement extension of DQN inspired by Dropout. The key intuition behind REM is that if one has access to multiple estimates of Q-values, then a weighted combination of the Q-value estimates is also an estimate for Q-values. Accordingly, in each training step, REM randomly combines multiple Q-value estimates and uses this random combination for robust training.
 |
| Neural Network architectures for DQN, distributional QR-DQN and the expected RL variants with the same multi-head QR-DQN architecture, i.e., Ensemble-DQN and REM. In QR-DQN, each head (red rectangles) corresponds to a specific fraction of the return distribution, while in the proposed variants, each head approximates the Q-function. |
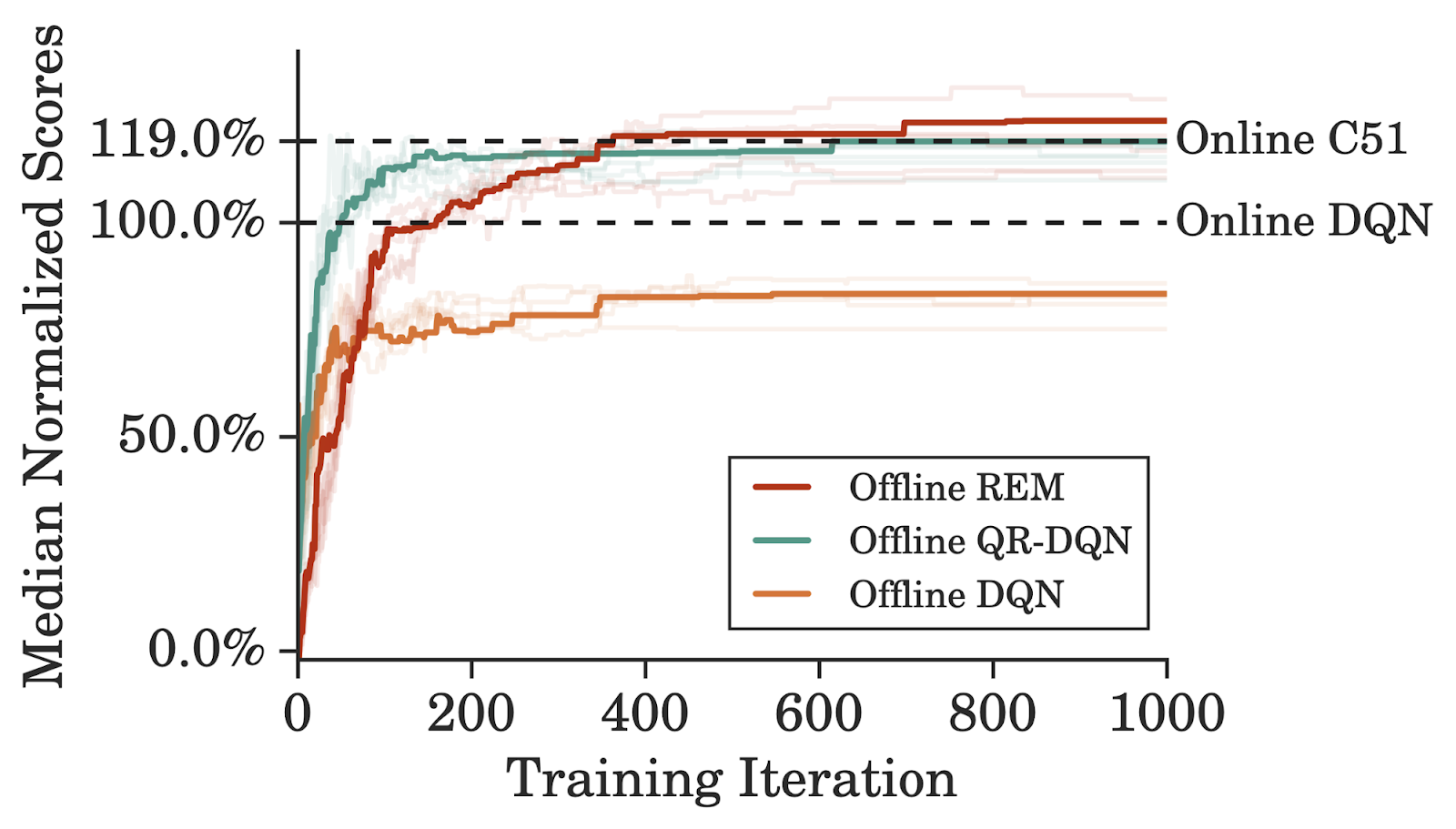 |
| Offline REM vs. baselines. Median normalized scores averaged over 5 runs across 60 Atari games of offline agents trained using DQN replay for 5x iterations, compared to online DQN. |
 |
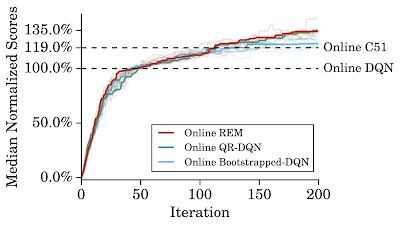
| Online REM vs. baselines. Median normalized evaluation scores averaged over 5 runs (shown as traces) across stochastic 60 Atari 2600 games of online agents trained for 200 million frames. Online REM with 4 Q-networks performs comparably to online QR-DQN. |
The discrepancy between these results and prior work that reports failure of standard RL agents in the offline setting could be attributed to the following factors:
- Offline Dataset Size: We trained offline QR-DQN and REM with reduced data obtained via randomly subsampling the entire DQN Replay Dataset, maintaining the same data distribution. Analogous to supervised learning, performance tends to increase as the size of data increases. With only 10% of the entire dataset, REM and QR-DQN approximately recover the performance of fully-trained DQN.
- Offline Dataset Composition: We trained offline RL agents on the first 20 million frames per game in the DQN Replay Dataset. Offline REM and QR-DQN outperform the best policy in this lower quality dataset, indicating that standard RL agents work well in the offline setting with sufficiently diverse datasets.

Offline RL with Lower Quality Dataset. REM and QR-DQN trained on offline data collected from DQN trained for 20 iterations (by using the first 20M frames from each game replay dataset). The horizontal line shows the performance of best policy in this dataset, which is significantly worse than fully-trained DQN. - Offline Algorithm Choice: There are claims that standard off-policy agents are ineffective on continuous control tasks when trained offline. However, we found that recent continuous control agents, such as TD3, perform comparably to a sophisticated offline agent when trained on large and diverse offline datasets.

Acknowledgements
This research was conducted in collaboration with Dale Schuurmans. We’d like to thank members of the Google Research, Brain Team for valuable discussions. A prior version of this work was presented as a contributed talk at NeurIPS 2019 DRL Workshop.
Quick links
Other posts of interest
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

July 9, 2026
SensorFM: Towards a general intelligence and interface for wearable health data- Generative AI ·
- Machine Intelligence
-

June 30, 2026
Expanding our Heat Resilience data to 50+ global cities- Climate & Sustainability ·
- Earth AI ·
- Open Source Models & Datasets
×
❮
❯