Alpa: Automated Model-Parallel Deep Learning
May 3, 2022
Posted by Zhuohan Li, Student Researcher, Google Research, and Yu Emma Wang, Senior Software Engineer, Google Core
Quick links
Update — 2022/05/06: This post has been updated to provide additional details about the collaboration with external research partners in the development of Alpa.
Over the last several years, the rapidly growing size of deep learning models has quickly exceeded the memory capacity of single accelerators. Earlier models like BERT (with a parameter size of < 1GB) can efficiently scale across accelerators by leveraging data parallelism in which model weights are duplicated across accelerators while only partitioning and distributing the training data. However, recent large models like GPT-3 (with a parameter size of 175GB) can only scale using model parallel training, where a single model is partitioned across different devices.
While model parallelism strategies make it possible to train large models, they are more complex in that they need to be specifically designed for target neural networks and compute clusters. For example, Megatron-LM uses a model parallelism strategy to split the weight matrices by rows or columns and then synchronizes results among devices. Device placement or pipeline parallelism partitions different operators in a neural network into multiple groups and the input data into micro-batches that are executed in a pipelined fashion. Model parallelism often requires significant effort from system experts to identify an optimal parallelism plan for a specific model. But doing so is too onerous for most machine learning (ML) researchers whose primary focus is to run a model and for whom the model’s performance becomes a secondary priority. As such, there remains an opportunity to automate model parallelism so that it can easily be applied to large models.
In “Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning”, published at OSDI 2022, we describe a method for automating the complex process of parallelizing a model, which was developed in close collaboration with researchers at Amazon Web Services, UC Berkeley, Shanghai Jiao Tong University, Duke University and Carnegie Mellon University. We demonstrate that with only one line of code Alpa can transform any JAX neural network into a distributed version with an optimal parallelization strategy that can be executed on a user-provided device cluster. We are also excited to announce the open-source release of Alpa’s code to the broader research community.
Alpa Design
We begin by grouping existing ML parallelization strategies into two categories, inter-operator parallelism and intra-operator parallelism. Inter-operator parallelism assigns distinct operators to different devices (e.g., device placement) that are often accelerated with a pipeline execution schedule (e.g., pipeline parallelism). With intra-operator parallelism, which includes data parallelism (e.g., Deepspeed-Zero), operator parallelism (e.g., Megatron-LM), and expert parallelism (e.g., GShard-MoE), individual operators are split and executed on multiple devices, and often collective communication is used to synchronize the results across devices.
The difference between these two approaches maps naturally to the heterogeneity of a typical compute cluster. Inter-operator parallelism has lower communication bandwidth requirements because it is only transmitting activations between operators on different accelerators. But, it suffers from device underutilization because of its pipeline data dependency, i.e., some operators are inactive while waiting on the outputs from other operators. In contrast, intra-operator parallelism doesn’t have the data dependency issue, but requires heavier communication across devices. In a GPU cluster, the GPUs within a node have higher communication bandwidth that can accommodate intra-operator parallelism. However, GPUs across different nodes are often connected with much lower bandwidth (e.g., ethernet) so inter-operator parallelism is preferred.
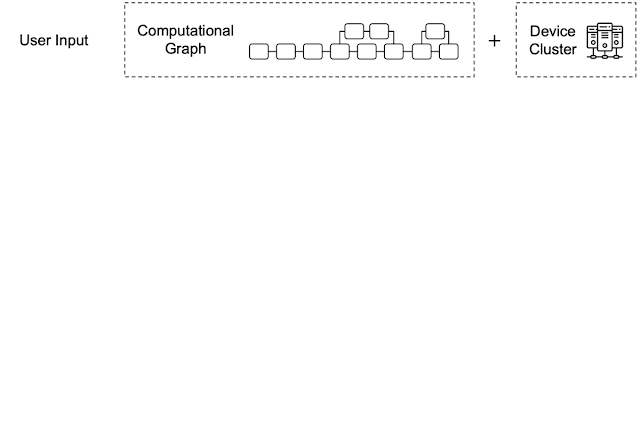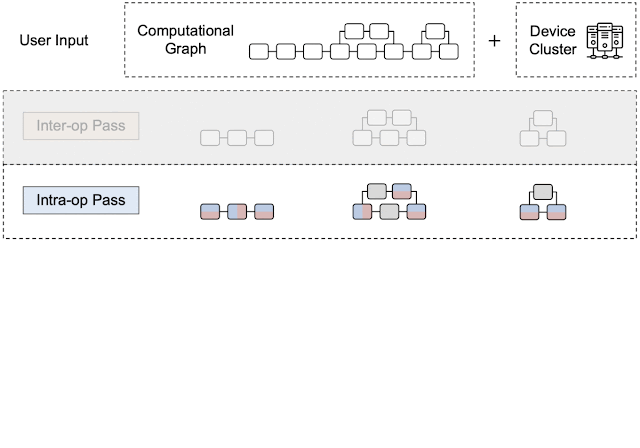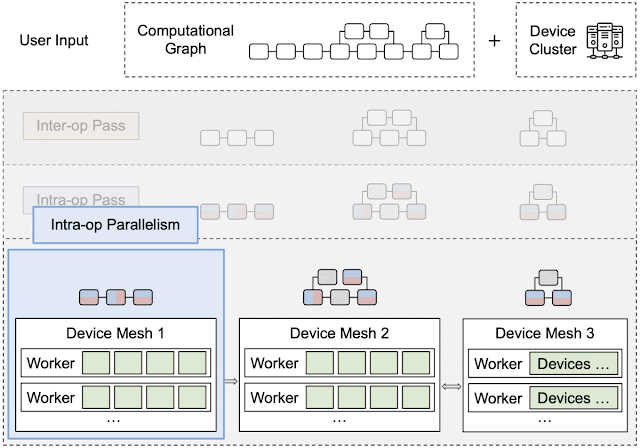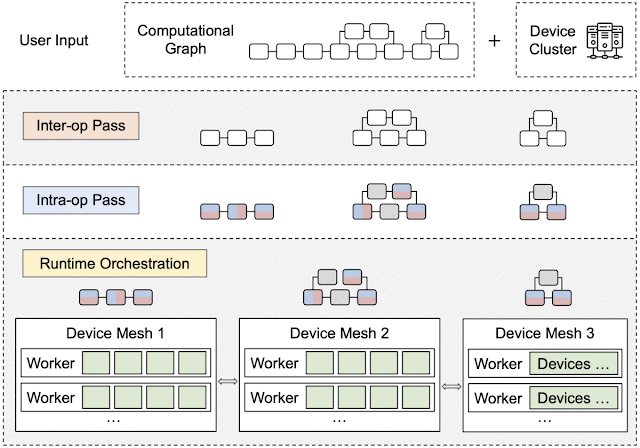
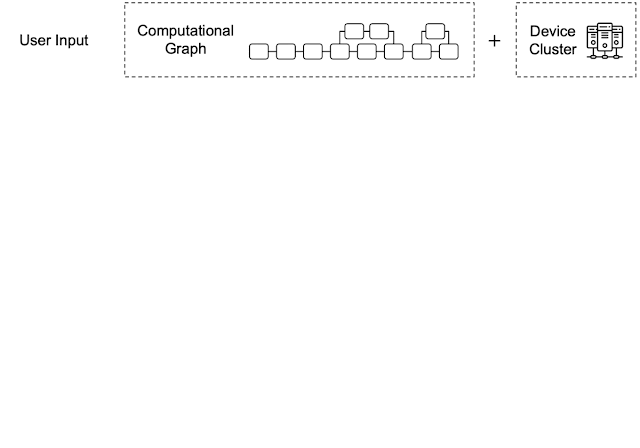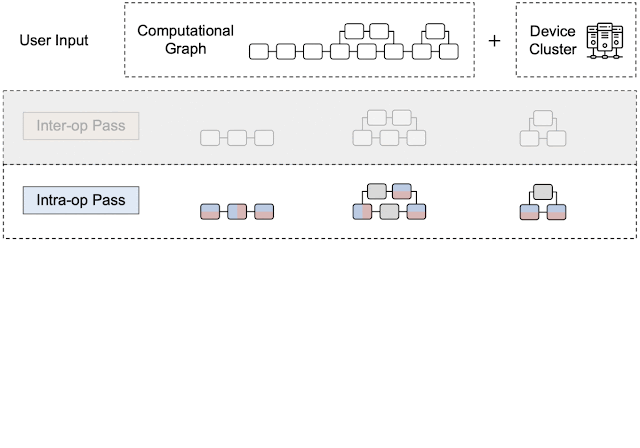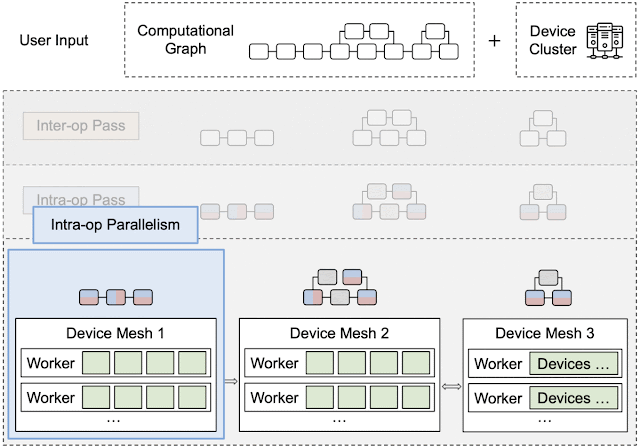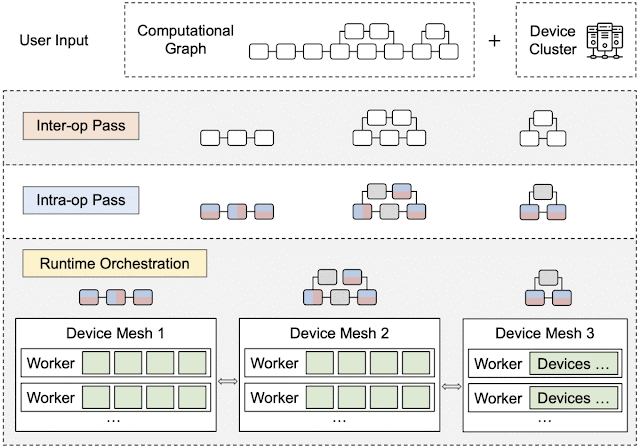
By leveraging heterogeneous mapping, we design Alpa as a compiler that conducts various passes when given a computational graph and a device cluster from a user. First, the inter-operator pass slices the computational graph into subgraphs and the device cluster into submeshes (i.e., a partitioned device cluster) and identifies the best way to assign a subgraph to a submesh. Then, the intra-operator pass finds the best intra-operator parallelism plan for each pipeline stage from the inter-operator pass. Finally, the runtime orchestration pass generates a static plan that orders the computation and communication and executes the distributed computational graph on the actual device cluster.
 |
| An overview of Alpa. In the sliced subgraphs, red and blue represent the way the operators are partitioned and gray represents operators that are replicated. Green represents the actual devices (e.g., GPUs). |
Intra-Operator Pass
Similar to previous research (e.g., Mesh-TensorFlow and GSPMD), intra-operator parallelism partitions a tensor on a device mesh. This is shown below for a typical 3D tensor in a Transformer model with a given batch, sequence, and hidden dimensions. The batch dimension is partitioned along device mesh dimension 0 (mesh0), the hidden dimension is partitioned along mesh dimension 1 (mesh1), and the sequence dimension is replicated to each processor.
 |
| A 3D tensor that is partitioned on a 2D device mesh. |
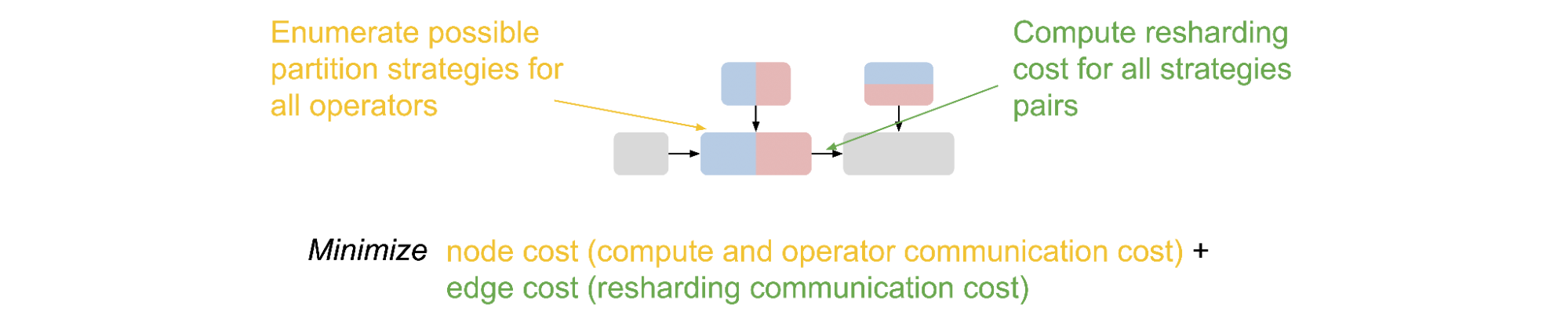
With the partitions of tensors in Alpa, we further define a set of parallelization strategies for each individual operator in a computational graph. We show example parallelization strategies for matrix multiplication in the figure below. Defining parallelization strategies on operators leads to possible conflicts on the partitions of tensors because one tensor can be both the output of one operator and the input of another. In this case, re-partition is needed between the two operators, which incurs additional communication costs.
 |
| The parallelization strategies for matrix multiplication. |
Given the partitions of each operator and re-partition costs, we formulate the intra-operator pass as a Integer-Linear Programming (ILP) problem. For each operator, we define a one-hot variable vector to enumerate the partition strategies. The ILP objective is to minimize the sum of compute and communication cost (node cost) and re-partition communication cost (edge cost). The solution of the ILP translates to one specific way to partition the original computational graph.
 |
Inter-Operator Pass
The inter-operator pass slices the computational graph and device cluster for pipeline parallelism. As shown below, the boxes represent micro-batches of input and the pipeline stages represent a submesh executing a subgraph. The horizontal dimension represents time and shows the pipeline stage at which a micro-batch is executed. The goal of the inter-operator pass is to minimize the total execution latency, which is the sum of the entire workload execution on the device as illustrated in the figure below. Alpa uses a Dynamic Programming (DP) algorithm to minimize the total latency. The computational graph is first flattened, and then fed to the intra-operator pass where the performance of all possible partitions of the device cluster into submeshes are profiled.
 |
| Pipeline parallelism. For a given time, this figure shows the micro-batches (colored boxes) that a partitioned device cluster and a sliced computational graph (e.g., stage 1, 2, 3) is processing. |
Runtime Orchestration
After the inter- and intra-operator parallelization strategies are complete, the runtime generates and dispatches a static sequence of execution instructions for each device submesh. These instructions include RUN a specific subgraph, SEND/RECEIVE tensors from other meshes, or DELETE a specific tensor to free the memory. The devices can execute the computational graph without other coordination by following the instructions.
Evaluation
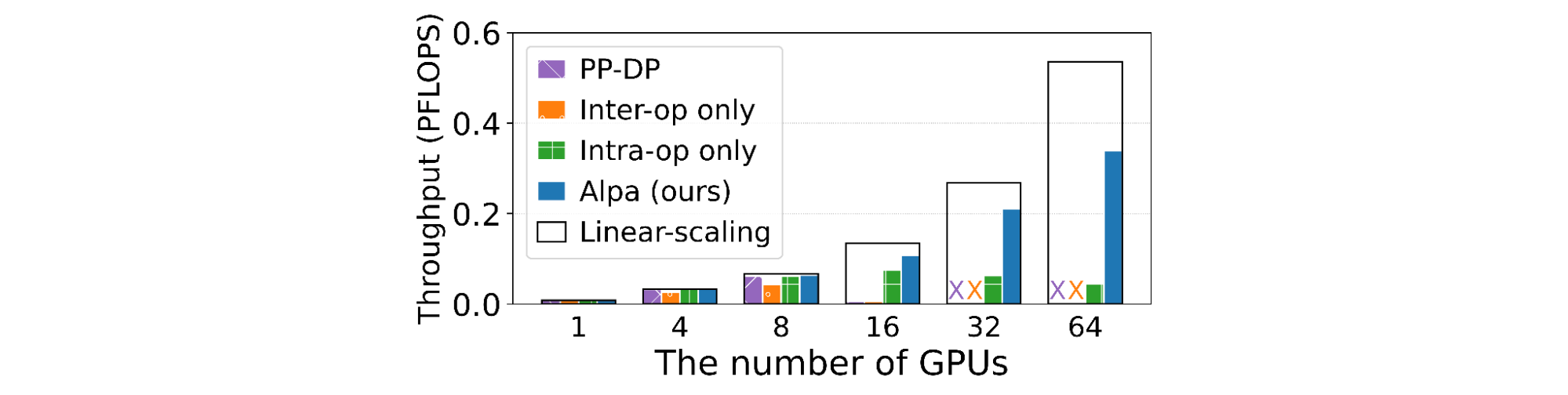
We test Alpa with eight AWS p3.16xlarge instances, each of which has eight 16 GB V100 GPUs, for 64 total GPUs. We examine weak scaling results of growing the model size while increasing the number of GPUs. We evaluate three models: (1) the standard Transformer model (GPT); (2) the GShard-MoE model, a transformer with mixture-of-expert layers; and (3) Wide-ResNet, a significantly different model with no existing expert-designed model parallelization strategy. The performance is measured by peta-floating point operations per second (PFLOPS) achieved on the cluster.
We demonstrate that for GPT, Alpa outputs a parallelization strategy very similar to the one computed by the best existing framework, Megatron-ML, and matches its performance. For GShard-MoE, Alpa outperforms the best expert-designed baseline on GPU (i.e., Deepspeed) by up to 8x. Results for Wide-ResNet show that Alpa can generate the optimal parallelization strategy for models that have not been studied by experts. We also show the linear scaling numbers for reference.
 |
| GPT: Alpa matches the performance of Megatron-ML, the best expert-designed framework. |
 |
| GShard MoE: Alpa outperforms Deepspeed (the best expert-designed framework on GPU) by up to 8x. |
 |
| Wide-ResNet: Alpa generalizes to models without manual plans. Pipeline and Data Parallelism (PP-DP) is a baseline model that uses only pipeline and data parallelism but no other intra-operator parallelism. |
 |
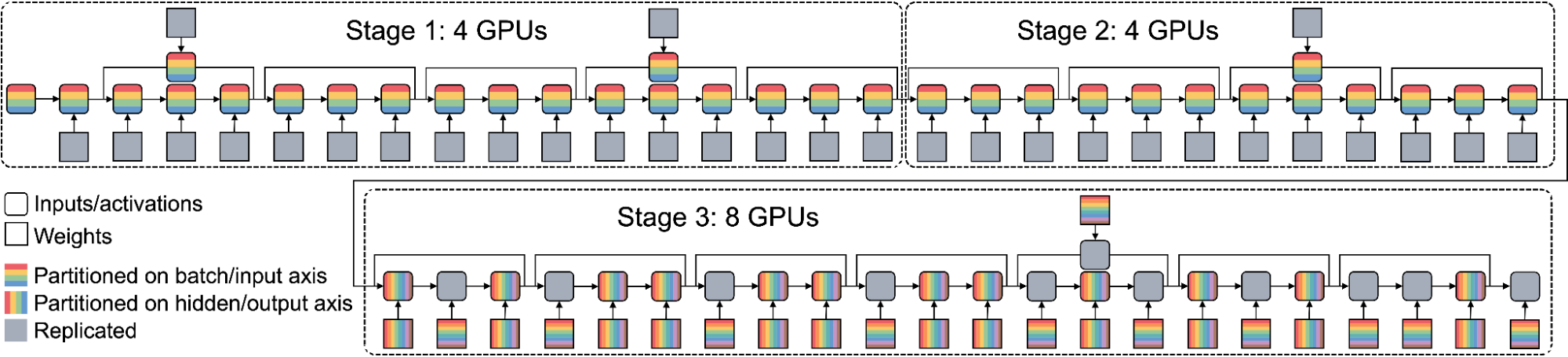
| The parallelization strategy for Wide-ResNet on 16 GPUs consists of three pipeline stages and is a complicated strategy even for an expert to design. Stages 1 and 2 are on 4 GPUs performing data parallelism, and stage 3 is on 8 GPUs performing operator parallelism. |
Conclusion
The process of designing an effective parallelization plan for distributed model-parallel deep learning has historically been a difficult and labor-intensive task. Alpa is a new framework that leverages intra- and inter-operator parallelism for automated model-parallel distributed training. We believe that Alpa will democratize distributed model-parallel learning and accelerate the development of large deep learning models. Explore the open-source code and learn more about Alpa in our paper.
Acknowledgements
Thank you to our colleagues at AWS, UC Berkeley, Shanghai Jiao Tong University, Duke University and Carnegie Mellon University for their partnership in this research. Thanks to the co-authors of the paper: Lianmin Zheng, Hao Zhang, Yonghao Zhuang, Yida Wang, Danyang Zhuo, Eric P. Xing, Joseph E. Gonzalez, and Ion Stoica. Lianmin (UC Berkeley & AWS) leads the effort on the intra-operator pass, Zhuohan (UC Berkeley & Google) leads the effort on the inter-operator pass, and Hao (UC Berkeley) leads the effort on the runtime orchestration pass. This project would not be possible without the internship opportunities provided by AWS and Google for Lianmin and Zhuohan respectively. We would also like to thank Shibo Wang, Jinliang Wei, Yanping Huang, Yuanzhong Xu, Zhifeng Chen, Claire Cui, Naveen Kumar, Yash Katariya, Laurent El Shafey, Qiao Zhang, Yonghui Wu, Marcello Maggioni, Mingyao Yang, Michael Isard, Skye Wanderman-Milne, and David Majnemer for their collaborations to this research.
Quick links
Other posts of interest
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

July 9, 2026
SensorFM: Towards a general intelligence and interface for wearable health data- Generative AI ·
- Machine Intelligence
-

June 30, 2026
Introducing TabFM: A zero-shot foundation model for tabular data- Data Management ·
- Machine Intelligence ·
- Product