A Step Towards Protecting Patients from Medication Errors
April 2, 2020
Posted by Kathryn Rough, Research Scientist and Alvin Rajkomar, MD, Google Health
Quick links
While no doctor, nurse, or pharmacist wants to make a mistake that harms a patient, research shows that 2% of hospitalized patients experience serious preventable medication-related incidents that can be life-threatening, cause permanent harm, or result in death. There are many factors contributing to medical mistakes, often rooted in deficient systems, tools, processes, or working conditions, rather than the flaws of individual clinicians (IOM report). To mitigate these challenges, one can imagine a system more sophisticated than the current rules-based error alerts provided in standard electronic health record software. The system would identify prescriptions that looked abnormal for the patient and their current situation, similar to a system that produces warnings for atypical credit card purchases on stolen cards. However, determining which medications are appropriate for any given patient at any given time is complex — doctors and pharmacists train for years before acquiring the skill. With the widespread use of electronic health records, it may now be feasible to use this data to identify normal and abnormal patterns of prescriptions.
In an initial effort to explore solutions to this problem, we partnered with UCSF's Bakar Computational Health Sciences Institute to publish “Predicting Inpatient Medication Orders in Electronic Health Record Data” in Clinical Pharmacology and Therapeutics, which evaluates the extent to which machine learning could anticipate normal prescribing patterns by doctors, based on electronic health records. Similar to our prior work, we used comprehensive clinical data from de-identified patient records, including the sequence of vital signs, laboratory results, past medications, procedures, diagnoses and more. Based on the patient’s current clinical state and medical history, our best model was able to anticipate physician’s actual prescribing decisions three quarters of the time.
Model Training
The dataset used for model training included approximately three million medication orders from over 100,000 hospitalizations. It used retrospective electronic health record data, which was de-identified by randomly shifting dates and removing identifying portions of the record in accordance with HIPAA, including names, addresses, contact details, record numbers, physician names, free-text notes, images, and more. The data was not joined or combined with any other data. All research was done using the open-sourced Fast Healthcare Interoperability Resources (FHIR) format, which we’ve previously used to make healthcare data more effective for machine learning. The dataset was not restricted to a particular disease or therapeutic area, which made the machine learning task more challenging, but also helped to ensure that the model could identify a larger variety of conditions; e.g. patients suffering from dehydration require different medications than those with traumatic injuries.
We evaluated two machine learning models: a long short-term memory (LSTM) recurrent neural network and a regularized, time-bucketed logistic model, which are commonly used in clinical research. Both were compared to a simple baseline that ranked the most frequently ordered medications based on a patient’s hospital service (e.g., General Medical, General Surgical, Obstetrics, Cardiology, etc.) and amount of time since admission. Each time a medication was ordered in the retrospective data, the models ranked a list of 990 possible medications, and we assessed whether the models assigned high probabilities to the medications actually ordered by doctors in each case.
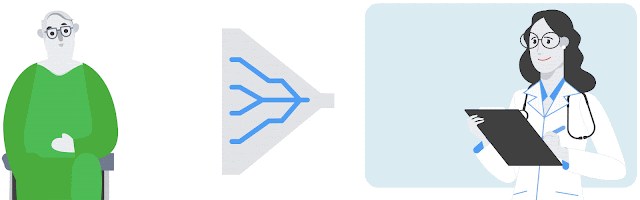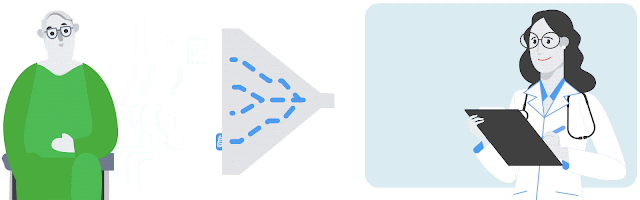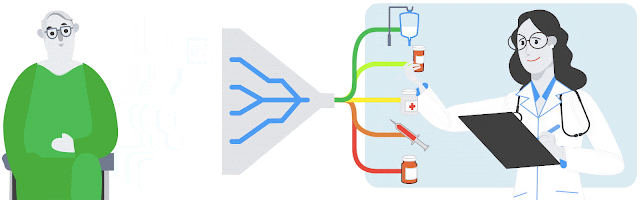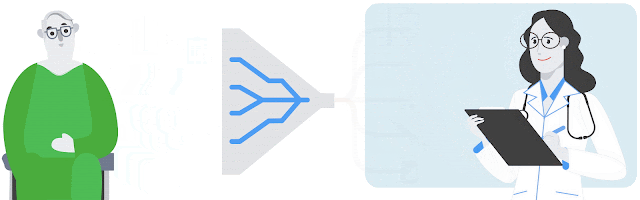
As an example of how the model was evaluated, imagine a patient who arrived at the hospital with signs of an infection. The model reviewed the information recorded in the patient’s electronic health record — a high temperature, elevated white blood cell count, quick breathing rate — and estimated how likely it would be for different medications to be prescribed in that situation. The model’s performance was evaluated by comparing its ranked choices against the medications that the physician actually prescribed (in this example, the antibiotic vancomycin and sodium chloride solution for rehydration).
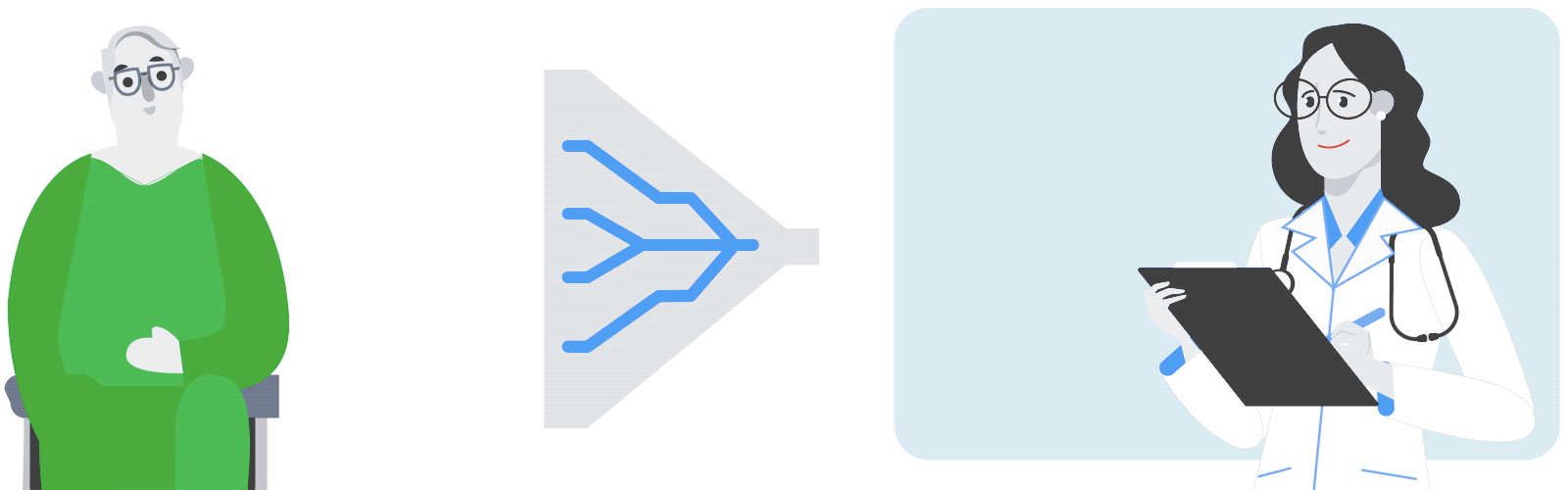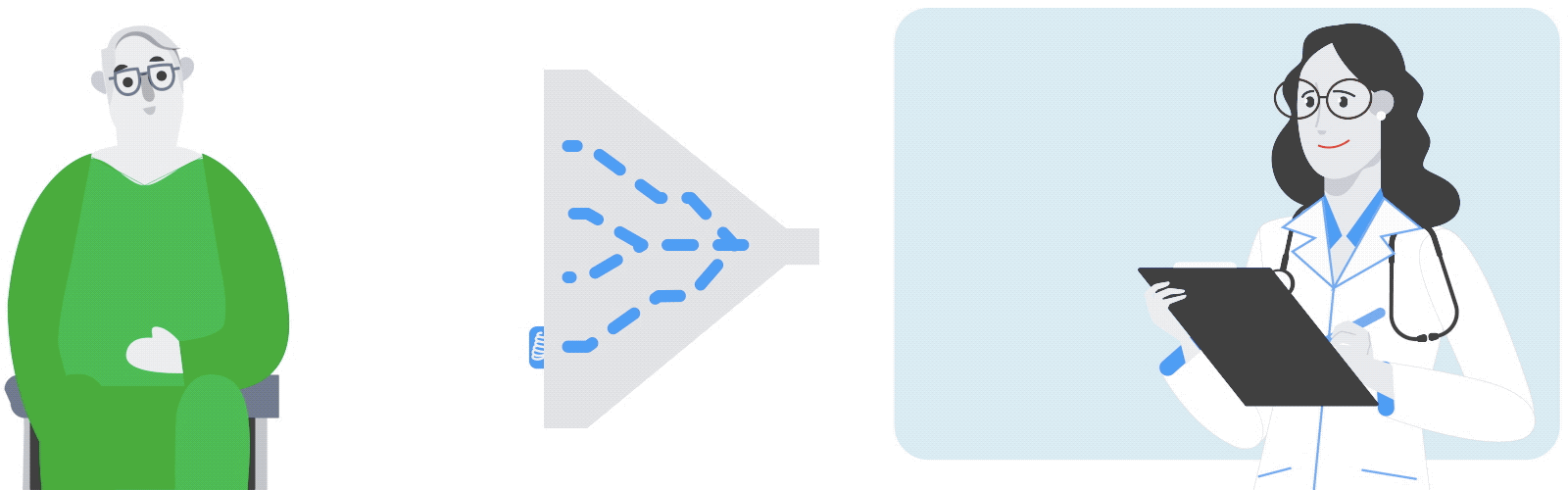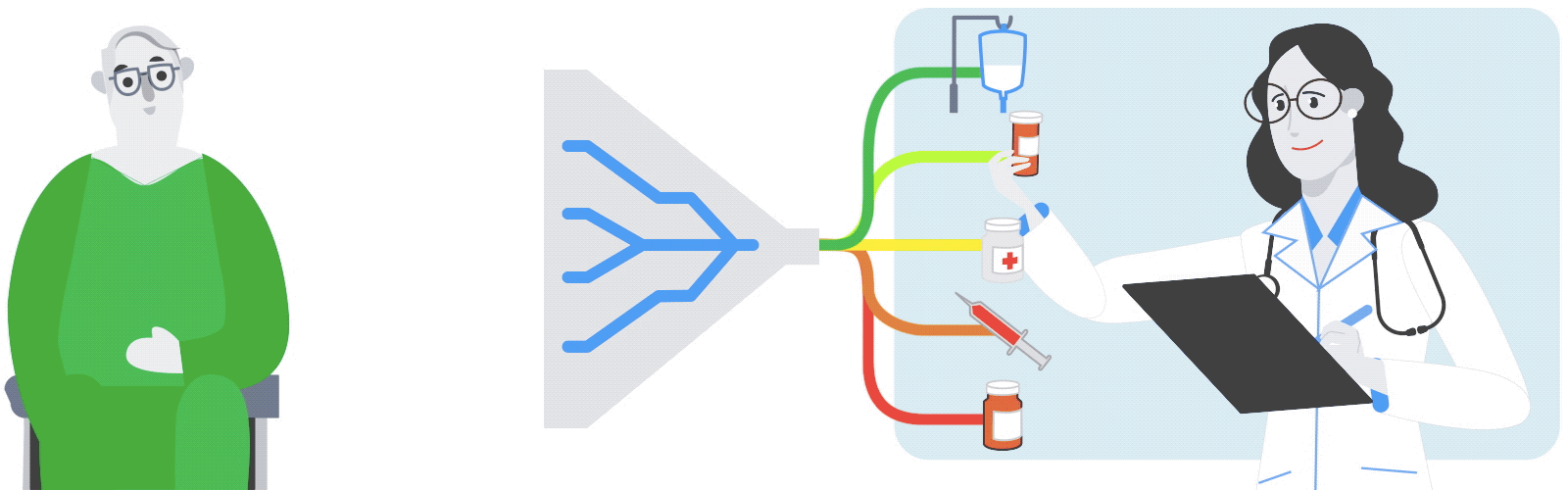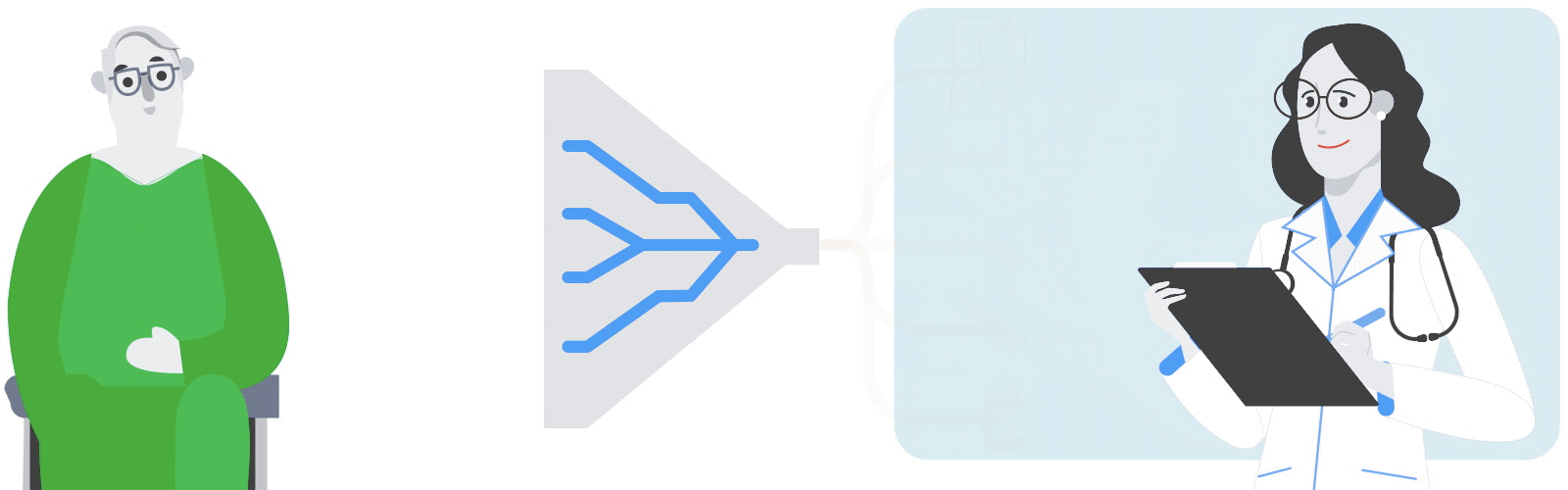 |
| Based on a patient’s medical history and current clinical characteristics, the model ranks the medications a physician is most likely to prescribe. |
Our best-performing model was the LSTM model, a class of models particularly effective for handling sequential data, including text and language. These models are capable of capturing the ordering and time recency of events in the data, making them a good choice for this problem.
Nearly all (93%) top-10 lists contained at least one medication that would be ordered by clinicians for the given patient within the next day. Fifty-five percent of the time, the model correctly placed medications prescribed by the doctor as one of the top-10 most likely medications, and 75% of ordered medications were ranked in the top-25. Even for ‘false negatives’ — cases where the medication ordered by doctors did not appear among the top-25 results — the model highly ranked a medication in the same class 42% of the time. This performance was not explained by the model simply predicting previously prescribed medications. Even when we blinded the model to previous medication orders, it maintained high performance.
What Does This Mean for Patients and Clinicians?
It’s important to remember that models trained this way reproduce physician behavior as it appears in historical data, and have not learned optimal prescribing patterns, how these medications might work, or what side effects might occur. However, learning ‘normal’ is a starting point to eventually spot abnormal, potentially dangerous orders. In our next phase of research, we will examine under which circumstances these models are useful for finding medication errors that could harm patients.
The results from this exploratory work are early first steps towards testing the hypothesis that machine learning can be applied to build systems that prevent mistakes and help to keep patients safe. We look forward to collaborating with doctors, pharmacists, other clinicians, and patients as we continue research to quantify whether models like this one are capable of catching errors, keeping patients safe in the hospital.
Acknowledgements
We would like to thank Atul Butte (UCSF), Claire Cui, Andrew Dai, Michael Howell, Laura Vardoulakis, Yuan (Emily) Xue, and Kun Zhang for their contributions towards the research work described in this post. We’d additionally like to thank members of our broader research team who have assisted in the development of analytical tools, data collection, maintenance of research infrastructure, assurance of data quality, and project management: Gabby Espinosa, Gerardo Flores, Michaela Hardt, Sharat Israni (UCSF), Jeff Love (UCSF), Dana Ludwig (UCSF), Hong Ji, Svetlana Kelman, I-Ching Lee, Mimi Sun, Patrik Sundberg, Chunfeng Wen, and Doris Wong.
Quick links
Other posts of interest
-

July 22, 2026
SymptomAI: Towards a conversational AI agent for everyday symptom assessment- General Science ·
- Health & Bioscience ·
- Natural Language Processing ·
- Responsible AI
-

July 22, 2026
Towards a quantum computer that learns from its errors- Machine Intelligence ·
- Quantum
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
×
❮
❯