A Neural Network for Machine Translation, at Production Scale
September 27, 2016
Posted by Quoc V. Le & Mike Schuster, Research Scientists, Google Brain Team
Quick links
Ten years ago, we announced the launch of Google Translate, together with the use of Phrase-Based Machine Translation as the key algorithm behind this service. Since then, rapid advances in machine intelligence have improved our speech recognition and image recognition capabilities, but improving machine translation remains a challenging goal.
Today we announce the Google Neural Machine Translation system (GNMT), which utilizes state-of-the-art training techniques to achieve the largest improvements to date for machine translation quality. Our full research results are described in a new technical report we are releasing today: “Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation” [1].
A few years ago we started using Recurrent Neural Networks (RNNs) to directly learn the mapping between an input sequence (e.g. a sentence in one language) to an output sequence (that same sentence in another language) [2]. Whereas Phrase-Based Machine Translation (PBMT) breaks an input sentence into words and phrases to be translated largely independently, Neural Machine Translation (NMT) considers the entire input sentence as a unit for translation.The advantage of this approach is that it requires fewer engineering design choices than previous Phrase-Based translation systems. When it first came out, NMT showed equivalent accuracy with existing Phrase-Based translation systems on modest-sized public benchmark data sets.
Since then, researchers have proposed many techniques to improve NMT, including work on handling rare words by mimicking an external alignment model [3], using attention to align input words and output words [4] and breaking words into smaller units to cope with rare words [5,6]. Despite these improvements, NMT wasn't fast or accurate enough to be used in a production system, such as Google Translate. Our new paper [1] describes how we overcame the many challenges to make NMT work on very large data sets and built a system that is sufficiently fast and accurate enough to provide better translations for Google’s users and services.
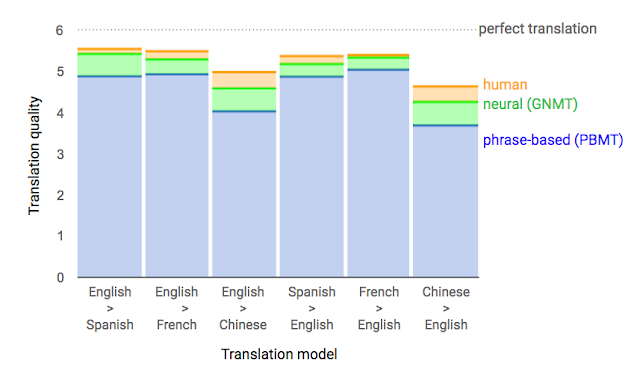
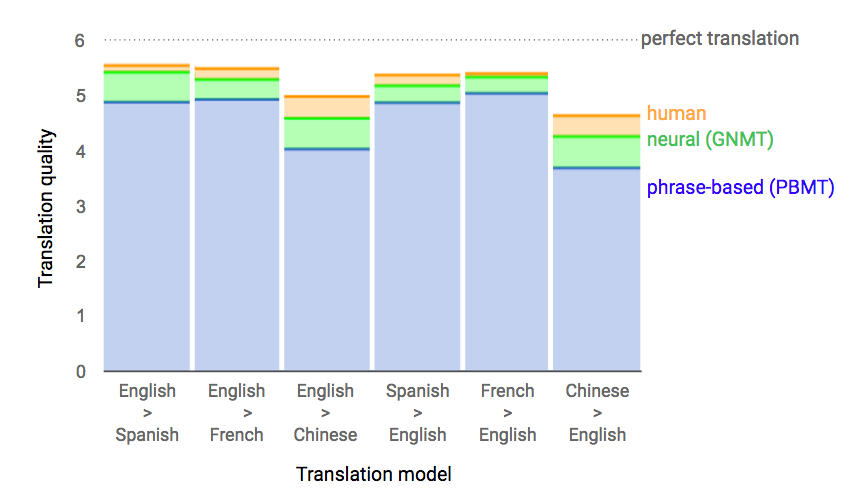 |
| Data from side-by-side evaluations, where human raters compare the quality of translations for a given source sentence. Scores range from 0 to 6, with 0 meaning “completely nonsense translation”, and 6 meaning “perfect translation." |
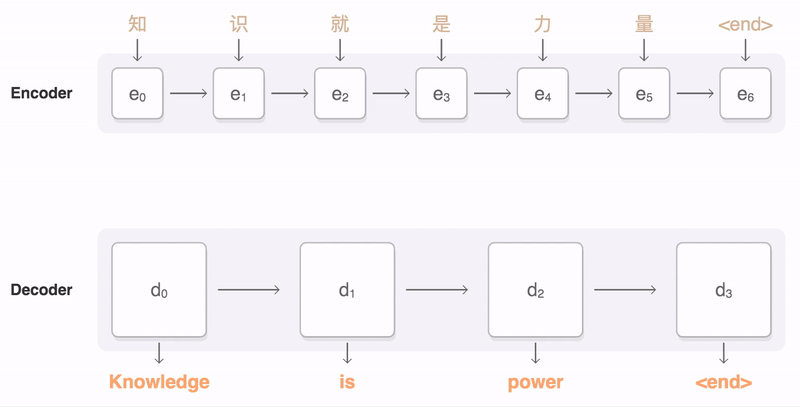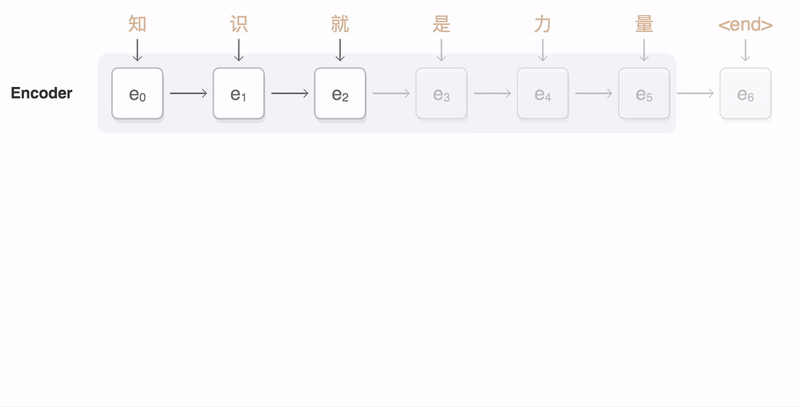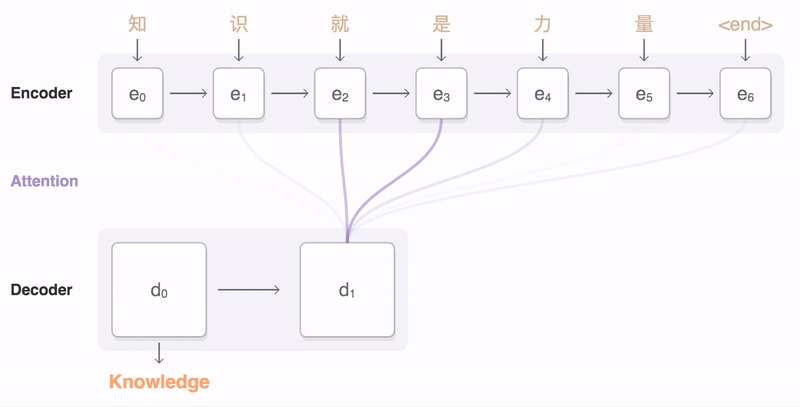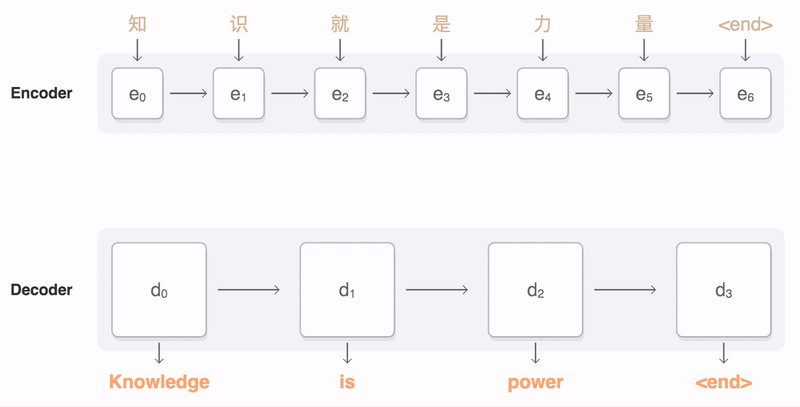
 |
| An example of a translation produced by our system for an input sentence sampled from a news site. Go here for more examples of translations for input sentences sampled randomly from news sites and books. |
Machine translation is by no means solved. GNMT can still make significant errors that a human translator would never make, like dropping words and mistranslating proper names or rare terms, and translating sentences in isolation rather than considering the context of the paragraph or page. There is still a lot of work we can do to serve our users better. However, GNMT represents a significant milestone. We would like to celebrate it with the many researchers and engineers—both within Google and the wider community—who have contributed to this direction of research in the past few years.
Acknowledgements:
We thank members of the Google Brain team and the Google Translate team for the help with the project. We thank Nikhil Thorat and the Big Picture team for the visualization.
References:
[1] Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation, Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V. Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, Jeff Klingner, Apurva Shah, Melvin Johnson, Xiaobing Liu, Łukasz Kaiser, Stephan Gouws, Yoshikiyo Kato, Taku Kudo, Hideto Kazawa, Keith Stevens, George Kurian, Nishant Patil, Wei Wang, Cliff Young, Jason Smith, Jason Riesa, Alex Rudnick, Oriol Vinyals, Greg Corrado, Macduff Hughes, Jeffrey Dean. Technical Report, 2016.
[2] Sequence to Sequence Learning with Neural Networks, Ilya Sutskever, Oriol Vinyals, Quoc V. Le. Advances in Neural Information Processing Systems, 2014.
[3] Addressing the rare word problem in neural machine translation, Minh-Thang Luong, Ilya Sutskever, Quoc V. Le, Oriol Vinyals, and Wojciech Zaremba. Proceedings of the 53th Annual Meeting of the Association for Computational Linguistics, 2015.
[4] Neural Machine Translation by Jointly Learning to Align and Translate, Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio. International Conference on Learning Representations, 2015.
[5] Japanese and Korean voice search, Mike Schuster, and Kaisuke Nakajima. IEEE International Conference on Acoustics, Speech and Signal Processing, 2012.
[6] Neural Machine Translation of Rare Words with Subword Units, Rico Sennrich, Barry Haddow, Alexandra Birch. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 2016.
Quick links
Other posts of interest
-

July 22, 2026
Towards a quantum computer that learns from its errors- Machine Intelligence ·
- Quantum
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

July 9, 2026
SensorFM: Towards a general intelligence and interface for wearable health data- Generative AI ·
- Machine Intelligence
×
❮
❯