A Multilingual Corpus of Automatically Extracted Relations from Wikipedia
June 2, 2015
Posted by Shankar Kumar, Google Research Scientist and Manaal Faruqui, Carnegie Mellon University PhD candidate
Quick links
In Natural Language Processing, relation extraction is the task of assigning a semantic relationship between a pair of arguments. As an example, a relationship between the phrases “Ottawa” and “Canada” is “is the capital of”. These extracted relations could be used in a variety of applications ranging from Question Answering to building databases from unstructured text.
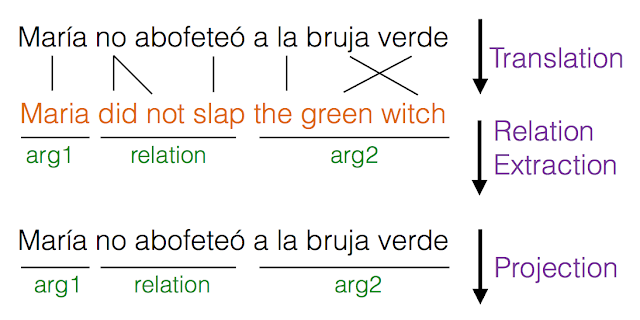
While relation extraction systems work accurately for English and a few other languages, where tools for syntactic analysis such as parsers, part-of-speech taggers and named entity analyzers are readily available, there is relatively little work in developing such systems for most of the world's languages where linguistic analysis tools do not yet exist. Fortunately, because we do have translation systems between English and many other languages (such as Google Translate), we can translate text from a non-English language to English, perform relation extraction and project these relations back to the foreign language.
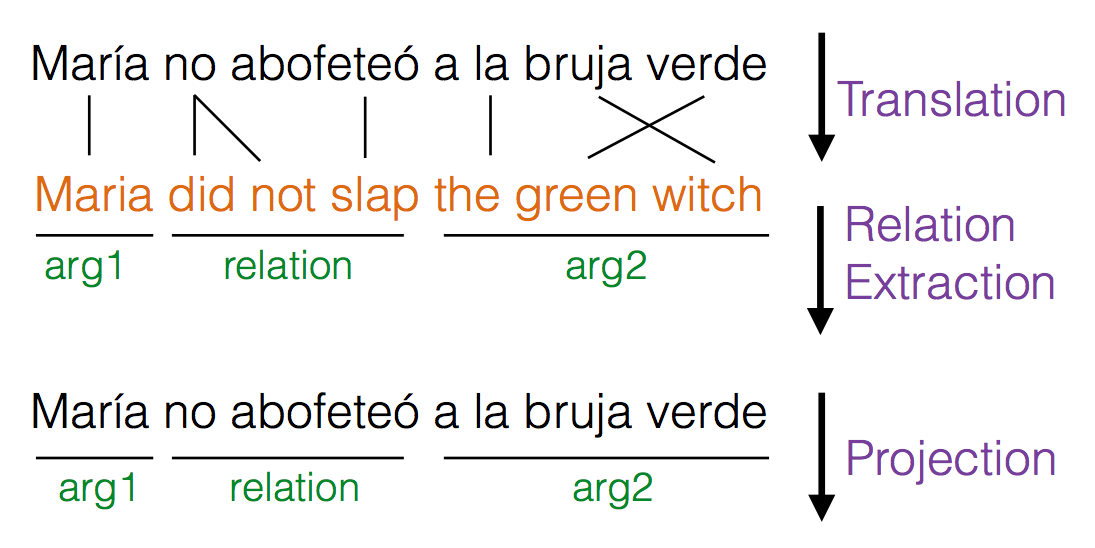 |
| Relation extraction in a Spanish sentence using the cross-lingual relation extraction pipeline. |
Since there is no such publicly available corpus of multilingual relations, we are releasing a dataset of automatically extracted relations from the Wikipedia corpus in 61 languages, along with the manually annotated relations in 3 languages (French, Hindi and Russian). It is our hope that our data will help researchers working on natural language processing and encourage novel applications in a wide variety of languages.
We wish to thank Bruno Cartoni, Vitaly Nikolaev, Hidetoshi Shimokawa, Kishore Papineni, John Giannandrea and their teams for making this data release possible. This dataset is licensed by Google Inc. under the Creative Commons Attribution-ShareAlike 3.0 License.
Quick links
Other posts of interest
-

July 30, 2026
Science One Framework: A verifiable autonomous research framework via Chain-of-Evidence- General Science ·
- Machine Intelligence ·
- Natural Language Processing
-

July 22, 2026
SymptomAI: Towards a conversational AI agent for everyday symptom assessment- General Science ·
- Health & Bioscience ·
- Natural Language Processing ·
- Responsible AI
-

June 30, 2026
Expanding our Heat Resilience data to 50+ global cities- Climate & Sustainability ·
- Earth AI ·
- Open Source Models & Datasets
×
❮
❯
