A Large Corpus for Supervised Word-Sense Disambiguation
January 18, 2017
Posted by Colin Evans and Dayu Yuan, Software Engineers
Quick links
Understanding the various meanings of a particular word in text is key to understanding language. For example, in the sentence “he will receive stock in the reorganized company”, we know that “stock” refers to “the capital raised by a business or corporation through the issue and subscription of shares” as defined in the New Oxford American Dictionary (NOAD), based on the context. However, there are more than 10 other definitions for “stock” in NOAD, ranging from “goods in a store”to “a medieval device for punishment”. For a computer algorithm, distinguishing between these meanings is so difficult that it has been described as “AI-complete” in the past (Navigli, 2009; Ide and Veronis 1998; Mallery 1988).
In order to help further progress on this challenge, we’re happy to announce the release of word-sense annotations on the popular MASC and SemCor datasets, manually annotated with senses from the NOAD. We’re also releasing mappings from the NOAD senses to English Wordnet, which is more commonly used by the research community. This is one of the largest releases of fully sense-annotated English corpora.
Supervised Word-Sense Disambiguation
Humans distinguish between meanings of words in text easily because we have access to an enormous amount of common-sense knowledge about how the world works, and how this connects to language. For an example of the difficulty, “[stock] in a business” implies the financial sense, but “[stock] in a bodega” is more likely to refer to goods on the shelves of a store, even though a bodega is a kind of business. Acquiring sufficient knowledge in a form that a machine can use, and then applying it to understanding the words in text, is a challenge.
Supervised word-sense disambiguation (WSD) is the problem of building a machine-learned system using human-labeled data that can assign a dictionary sense to all words used in text (in contrast to entity disambiguation, which focuses on nouns, mostly proper). Building a supervised model that performs better than just assigning the most frequent sense of a word without considering the surrounding text is difficult, but supervised models can perform well when supplied with significant amounts of training data. (Navigli, 2009)
By releasing this dataset, it is our hope that the research community will be able to further the advance of algorithms that allow machines to understand language better, allowing applications such as:
- Facilitating the automatic construction of databases from text in order to answer questions and connect knowledge in documents. For example, understanding that a “hemi engine” is a kind of automotive machinery, and a “locomotive engine” is a kind of train, or that “Kanye West is a star” implies that he is a celebrity, but “Sirius is a star” implies that it is an astronomical object.
- Disambiguating words in queries, so that results for “date palm” and “date night” or “web spam” and “spam recipe” can have distinct interpretations for different senses, and documents returned from a query have the same meaning that is implied by the query.
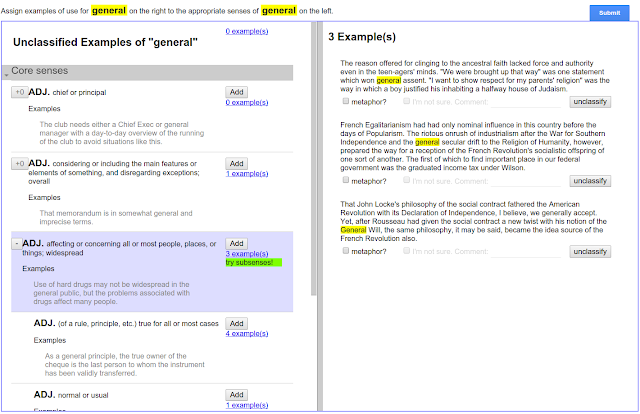
In the manually labeled data sets that we are releasing, each sense annotation is labeled by five raters. To ensure high quality of the sense annotation, raters are first trained with gold annotations, which were labeled by experienced linguists in a separate pilot study before the annotation task. The figure below shows an example of a rater’s work page in our annotation tool.

The left side of the page lists all candidate dictionary senses (in this case, the word “general”). Example sentences from the dictionary are also provided. The to-be-annotated words, highlighted within a sentence, are shown on the right side of the work page. Besides linking a dictionary sense to a word, raters could also label one of the three exceptions: (1) The word is a typo (2) None of the above and (3) I can’t decide. Raters could also check whether the word usage is a metaphor and leave comments.
The sense annotation task used for this data release achieves an inter-rater reliability score of 0.869 using Krippendorff's alpha (α >= 0.67 is considered an acceptable level of reproducibility, and α >= 0.80 is considered a highly reproducible result) (Krippendorff, 2004). Annotation counts are listed below.
Total | noun | verb | adjective | adverb | |
SemCor | 115k | 38k | 57k | 11.6k | 8.6k |
MASC | 133k | 50k | 12.7k | 13.6k | 4.2k |
Wordnet Mappings
We’ve also included two sets of mappings from NOAD to Wordnet. A smaller set of 2200 words was manually mapped in a process similar to the sense annotations described above, and a larger set was created algorithmically. Together, these mappings allow for resources in Wordnet to be applied to this NOAD corpus, and for systems built using Wordnet to be evaluated using this corpus.
You can learn more about our full research results on this corpus using LSTM-based language models and semi-supervised learning in “Semi-supervised Word Sense Disambiguation with Neural Models”.
Acknowledgements
The datasets were built with help from Eric Altendorf, Heng Chen, Jutta Degener, Ryan Doherty, David Huynh, Ji Li, Julian Richardson and Binbin Ruan.
Quick links
Other posts of interest
-

July 9, 2026
SensorFM: Towards a general intelligence and interface for wearable health data- Generative AI ·
- Machine Intelligence
-

June 30, 2026
Expanding our Heat Resilience data to 50+ global cities- Climate & Sustainability ·
- Earth AI ·
- Open Source Models & Datasets
-

June 30, 2026
Introducing TabFM: A zero-shot foundation model for tabular data- Data Management ·
- Machine Intelligence ·
- Product
×
❮
❯
