Cloud AI Research
We conduct groundbreaking research with the goal to infuse AI into Google Cloud products and infrastructure.

We conduct groundbreaking research with the goal to infuse AI into Google Cloud products and infrastructure.
About the team
The Cloud AI Research team, a dynamic group of scientists and engineers, is dedicated to conducting transformative, high-impact research and achieving fundamental breakthroughs in artificial intelligence and AI systems. We explore novel, high-potential directions, pioneering a new class of "Co-X" agents designed to automate and augment complex human tasks.
Our projects range from developing AI agents that can generate and validate award-worthy research papers to those that manage complex data center networks and power consumption. We are also developing state-of-the-art agents for ML engineering and data science, and exploring creative frontiers with agents that can direct long-form video content. Foundational to this is our work on core agent capabilities, such as long-term memory, automated multi-agent system design, and verifiable safety. We collaborate closely with partners to ship these innovations, ensuring our breakthroughs advance both Google's products and the state of science.
Team focus summaries
We develop "Co-X" agents designed to automate and augment complex professional workflows. This includes pioneering agents for AI research (Co-AI Researcher), ML engineering (Co-ML Engineer), Data Science (Co-Data Scientist), network management (Co-Network Engineer), AI scientist (Co-Scientist) and creative content generation (Co-Director).
Our research builds the core technologies that enable more powerful and scalable agents. Key areas include developing robust long-term memory (Reflective Memory Management), automating the design of effective multi-agent systems (Agent Co-Designer), and establishing verifiable agent safety guardrails.
We focus on advancing the deep reasoning capabilities of AI agents. This work aims to push the state-of-the-art for systems that can conduct complex, multi-step research and analysis, with the goal of significantly outperforming existing industry benchmarks.
Featured publications
Highlighted work
-
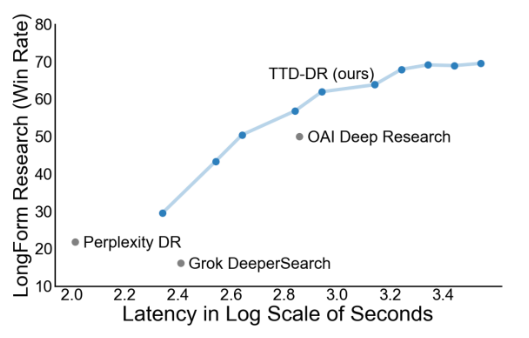 Deep Researcher with Test-Time DiffusionA Deep Research agent that achieves SOTA results in long-form report writing and complex reasoning.
Deep Researcher with Test-Time DiffusionA Deep Research agent that achieves SOTA results in long-form report writing and complex reasoning. -
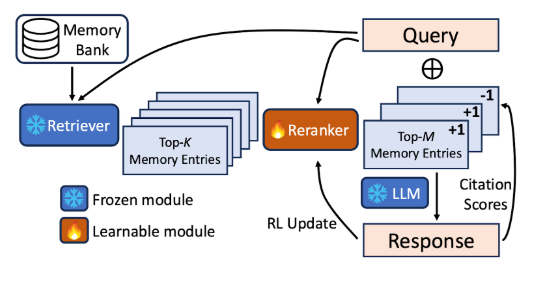 MemoryBankEnable personalized agents through LLM memory management.
MemoryBankEnable personalized agents through LLM memory management. -
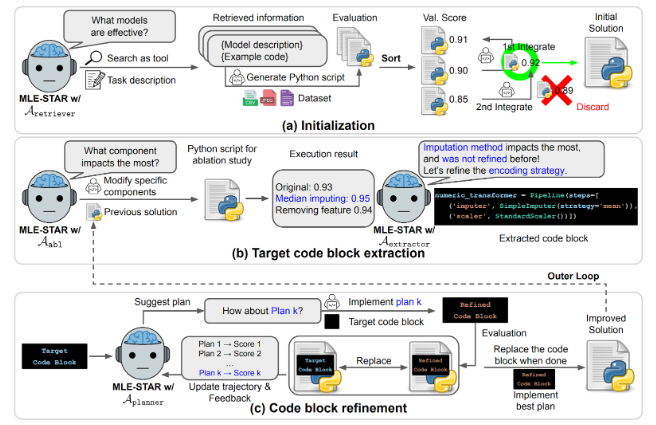 MLE-STARSOTA multi-agent systems for various machine learning engineering tasks (i.e., Automatically competing on Kaggle competition).
MLE-STARSOTA multi-agent systems for various machine learning engineering tasks (i.e., Automatically competing on Kaggle competition). -
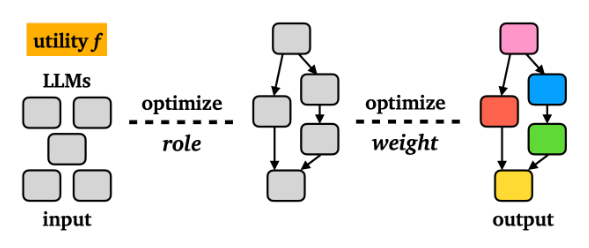 Heterogeneous Swarms: Jointly Optimizing Model Roles and Weights for Multi-LLM SystemsSOTA multi-agent system that jointly optimizes the model roles and weights.
Heterogeneous Swarms: Jointly Optimizing Model Roles and Weights for Multi-LLM SystemsSOTA multi-agent system that jointly optimizes the model roles and weights. -
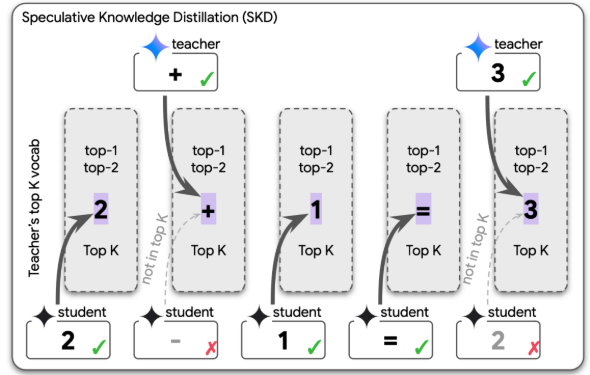 Speculative Knowledge Distillation: Bridging the Teacher-Student Gap Through Interleaved SamplingSOTA LLM distillation mechanism that uses student-teacher cooperation to generate high-quality, inference-aligned training data.
Speculative Knowledge Distillation: Bridging the Teacher-Student Gap Through Interleaved SamplingSOTA LLM distillation mechanism that uses student-teacher cooperation to generate high-quality, inference-aligned training data. -
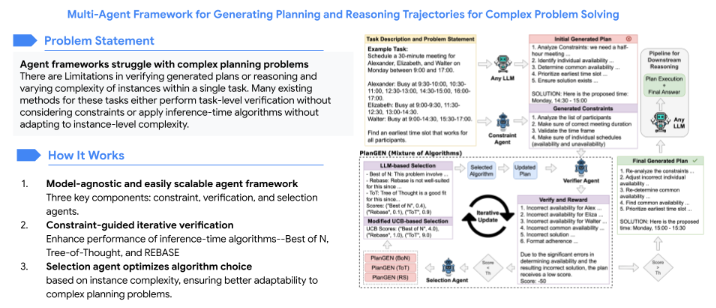 PlanGENMAS for Generating Planning and Reasoning Trajectories for Complex Problem Solving.
PlanGENMAS for Generating Planning and Reasoning Trajectories for Complex Problem Solving. -
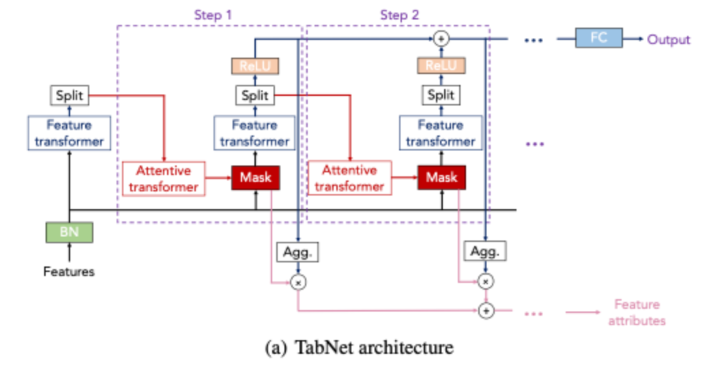 TabNetA new deep learning method for tabular data that gets state-of-the-art performance on many datasets and yields interpretable insights.
TabNetA new deep learning method for tabular data that gets state-of-the-art performance on many datasets and yields interpretable insights. -
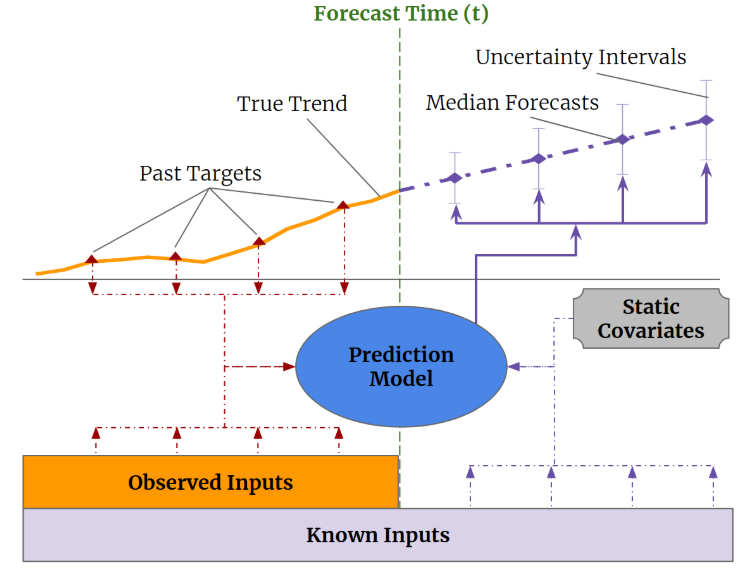 Temporal fusion transformerA new deep learning model for time-series with complex inputs that is state-of-the-art in terms of performance across a wide range of datasets.
Temporal fusion transformerA new deep learning model for time-series with complex inputs that is state-of-the-art in terms of performance across a wide range of datasets.
Some of our locations





Some of our people
-

Tomas Pfister
- Algorithms and Theory
- Machine Intelligence
- Machine Perception
- +1 more
-

Chen-Yu Lee
- Machine Intelligence
- Machine Perception
- Natural Language Processing
-

Jinsung Yoon
- Algorithms and Theory
- Machine Intelligence
- Machine Perception
- +1 more
-

Lesly Miculicich
- Machine Intelligence
- Machine Translation
- Natural Language Processing
-

Long T. Le
- Data Mining and Modeling
- Machine Learning
- Natural Language Processing
-

Rujun Han
- Machine Learning
- Natural Language Processing
-

Rajarishi Sinha
- Algorithms and Theory
- Machine Intelligence
- Machine Translation
- +1 more
-

Yanfei Chen
- Machine Intelligence
- Natural Language Processing
-

Zifeng Wang
- Algorithms and Theory
- Data Mining and Modeling
- Machine Intelligence
-
Bhavana Dalvi Mishra
- Human-Computer Interaction and Visualization
- Machine Intelligence
- Machine Learning
- +2 more
-

Chun-Liang Li
- Algorithms and Theory
- Machine Intelligence
- Machine Perception
- +1 more
-

Jiefeng Chen
- Machine Intelligence
- Natural Language Processing
-

Ke Jiang
- Machine Intelligence
- Natural Language Processing
-
Mihir Parmar
- Algorithms and Theory
- Machine Intelligence
- Machine Learning
- +1 more
-

Palash Goyal
- Algorithms and Theory
- Machine Intelligence
- Machine Learning
- +2 more
-

Rui Meng
- Machine Intelligence
- Machine Learning
-

Yale Song
- Machine Intelligence
- Machine Learning
- Machine Perception
-

Yiwen Song
- Machine Learning
- Natural Language Processing
