
Robust speech recognition in AR through infinite virtual rooms with acoustic modeling
April 17, 2024
Chiong Lai and Mathieu Parvaix, Software Engineers, Google Augmented Reality
Acoustic room simulations allow the training of robust sound separation models for speech recognition on AR Glasses with minimal amounts of real data.
Quick links
As augmented reality (AR) technology becomes more capable and widely available, it has the potential to assist in a wide range of everyday situations. As we have shared previously, we are excited about the potential for AR and are continually developing and testing new technology and experiences. One of our research directions explores the potential for how speech models could transform communication for people. For example, in our previous Wearable Subtitles work, we augmented communication through all-day speech transcription, the potential of which is demonstrated in multiple user studies with people who are deaf and hard-of-hearing, or for communication across different languages. Such augmentation can be especially helpful in group conversations or noisy environments where people may encounter difficulty distinguishing what others say. Hence, accurate sound separation and speech recognition in a wearable form factor are key in offering a reliable and valuable user experience.
Captioning of speech in a real-world environment is particularly challenging in group conversations (left) or noisy environments with multiple surrounding speakers (right).
Developing deep learning solutions for audio signal processing requires access to large, high-quality datasets. For training sound separation models, recording audio on the actual device has the benefit of capturing the specific acoustics properties to be included in the model training. However, this recording process is time consuming and difficult given the need to use an actual device across a representative number of realistic environments. In contrast, using simulated data (e.g., from a room simulator) is fast and low cost, but may not capture the fine acoustics properties of the device.
In “Quantifying the Effect of Simulator-Based Data Augmentation for Speech Recognition on Augmented Reality Glasses”, presented at IEEE ICASSP 2024, we demonstrate that training on a hybrid set — composed of a small amount of real recordings with a microphone-equipped head-worn display prototype, and large amounts of simulated data — improves model performance. This hybrid approach makes it possible to:
- capture the acoustics properties of the actual hardware (not available in the simulated data), and
- easily and quickly generate large amounts of simulated data for different room sizes and configurations of acoustic scenes, which would be extremely time consuming to record with the actual device.
Furthermore, we also show that modeling the directivity on the prototype’s microphones, and therefore increasing the realism of the simulations, allows us to further reduce the amount of real data needed in the training set.
Sound propagation in a room
The propagation of sound waves from Point A to Point B can be modeled as follows,
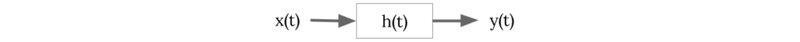
where x(t) is the time domain sound signal at Point A and y(t) is the sound signal at Point B. The impulse response (IR), h(t), characterizes mathematically how the sound waves change when propagating through the medium between Point A and B.
Below, we show an example of IR recorded in a moderately reverberant room. The IR consists of three main parts; initial delay, main peak and the tail. The initial delay tells us the time delay for the sound waves to propagate from Point A to Point B. The main peak provides the direct (line-of-sight) sound propagation from A to B, also called direct path. The tail consists of the reflections of sound waves (also called reverberation) from the walls, floor and ceiling of a room, which arrives much later with lower amplitudes due to the longer distance traveled.
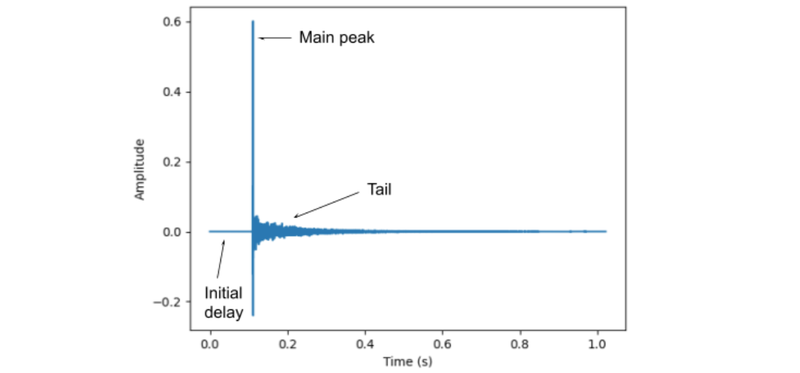
Example of a room IR captured on one head-worn microphone. The IR shows (a) the initial delay due to sound waves propagating from speaker to the microphone, (b) the main peak representing the direct (line-of-sight) propagation, and (c) the tail representing the sound reflections from the room.
Hybrid dataset
We developed a pipeline to capture the unique acoustics properties of the prototype in a range of representative environments. We record room impulse responses (RIRs) on the actual device in three different environments using a head-and-torso simulator (HATS) to capture realistic data. Nine loudspeakers and a mouth simulator provided 10 sound sources. We used a motorized turntable to control the sound source angle to the prototype, recording 720 RIRs per room (360° / 5° increments × 10 sound sources). The nine speakers are positioned around the prototype at different distances (1.0–4.2m) and heights (1.3–1.8m). The recorded RIR dataset is split into a training and evaluation set. For the simulated dataset, we generated 8000 IRs using a room simulator, with different RT60 reverberation times (0.2–1.5s), room volumes (length/width: 2–6m and height: 2–6m), and speaker positions (height: 1.3–2.1m, distance from prototype: 0.2–4m). All the simulated RIRs are used for training only.

Data collection setup. The prototype-mounted microphone is positioned on a rotating platform, surrounded by nine speakers, in addition to a 10th mouth simulation speaker. 720 RIR recordings were made with and without a head-and-torso simulator.
During training, speech and noise examples are spatialized and mixed together using public datasets (LibriTTS and FSD50K) and the recorded and simulated RIRs. Having access to the separate (i.e., pre-mixing) spatialized sources allows us to have ground truth data for supervised training. We train different CNN-based models (Conv-TasNet) based on the combination of the training set used (recorded, simulated, or both) and compare their performance. The model architecture and hyper-parameters are kept constant across models.
Acoustics modeling
We also hypothesized that microphone directivity could make the simulated IRs more realistic, since it is a key acoustics property captured in the recorded IRs. We therefore extended the simulated RIRs with microphone directivity and computed the direct-to-reverberant-ratio (DRR) to measure the power ratio between the direct path (line of sight) audio and its reverberant part. As hypothesized, our results (see below) show that we are able to bring the simulated IRs closer to the behavior of the recorded IRs and improve the quality of the simulated dataset, which in turn, improves overall model performance without the expensive and time-consuming recording process. A further point to note is that, as the simulated IRs are closer to the recorded IRs, the ratio of simulated-vs-recorded IRs in the hybrid dataset can be shifted more towards simulated IRs. This additional acoustics modeling therefore allows further reduction of recorded data without impacting model performance.
Results
For evaluation, we follow the same preprocessing steps as in the training, except that we use the evaluation set of the recorded IRs, and speech and noise audio that were excluded from training. After performing inference, the separated output audio is passed to an off-the-shelf automatic speech recognition (ASR) engine and the word-error-rate (WER) is calculated. We use the same unmodified ASR engine across all experiments, which is the same engine used in Pixel Recorder app. The same inference process is repeated for each model for comparison with the results summarized below.

Inference and evaluation pipeline.
The results show that the model trained using the hybrid dataset outperforms the models trained solely from the recorded, or simulated datasets, respectively. The hybrid model, S[4000]+M[720] (4000 simulated + 720 measured) has similar performance to M[1440] (1440 measured), while only needing half of the recordings — 1440 → 720 — due to the inclusion of 4000 simulated IRs in the training data. S[4000]+M[720] also outperforms models trained on S[8000] (8000 simulated), showing that a small subset of recorded (720) IRs reduces the needed number of simulated IRs (8000 → 4000).
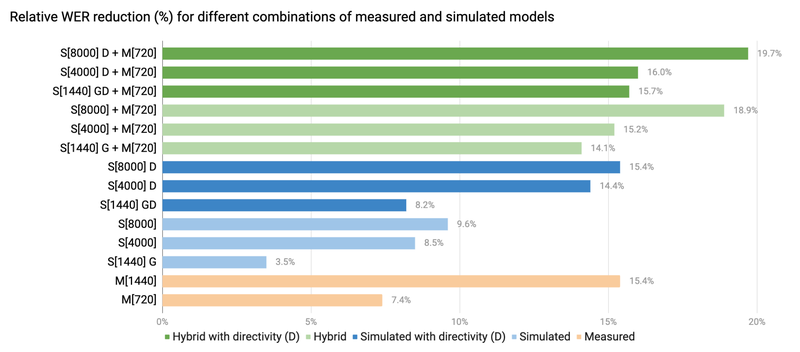
Comparison of different data augmentation approaches with measured and simulated IRs. M=Measured; S=Simulated; brackets=number of IRs, D=microphone directivity in simulation, G=simulations that use matching geometry to the measured rooms. The WER reduction is the improvement in WER compared to the baseline (without sound separation).
Conclusion
While having the potential to unlock many critical applications, speech recognition on wearables is challenging, especially in noisy and reverberant conditions. In this work, we quantify the effectiveness of using a room simulator to train a sound separation model used as a speech recognition front end. Using recorded IRs on a prototype in different rooms, we demonstrate that simulated IRs help improve speech recognition by (a) greatly increasing the amount of available simulated IRs, (b) by leveraging microphone directivity, and (c) by merging with a small number of measured IRs.
Simulation is a powerful tool for developing speech recognition systems for wearables. Our key takeaways for practitioners are:
- Realistic acoustics modeling can significantly reduce the amount of real-world data needed.
- Supplementing even limited real-world data with simulations provide vast gains in performance.
This work opens new avenues towards robust speech-driven AR experiences, paving the way for enhanced communication across countless applications.
Acknowledgements
This research has been largely conducted by Riku Arakawa, Mathieu Parvaix, Chiong Lai, Hakan Erdogan and Alex Olwal. Conceptual illustrations by Chris Ross.
Quick links
Other posts of interest
-
March 20, 2024
Computer-aided diagnosis for lung cancer screening- Health & Bioscience ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-
March 19, 2024
ScreenAI: A visual language model for UI and visually-situated language understanding- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-
March 18, 2024
MELON: Reconstructing 3D objects from images with unknown poses- Machine Intelligence ·
- Machine Perception